Distillation rung: where we are (as of June 2026)
Evidence-based ladder estimate, not projection
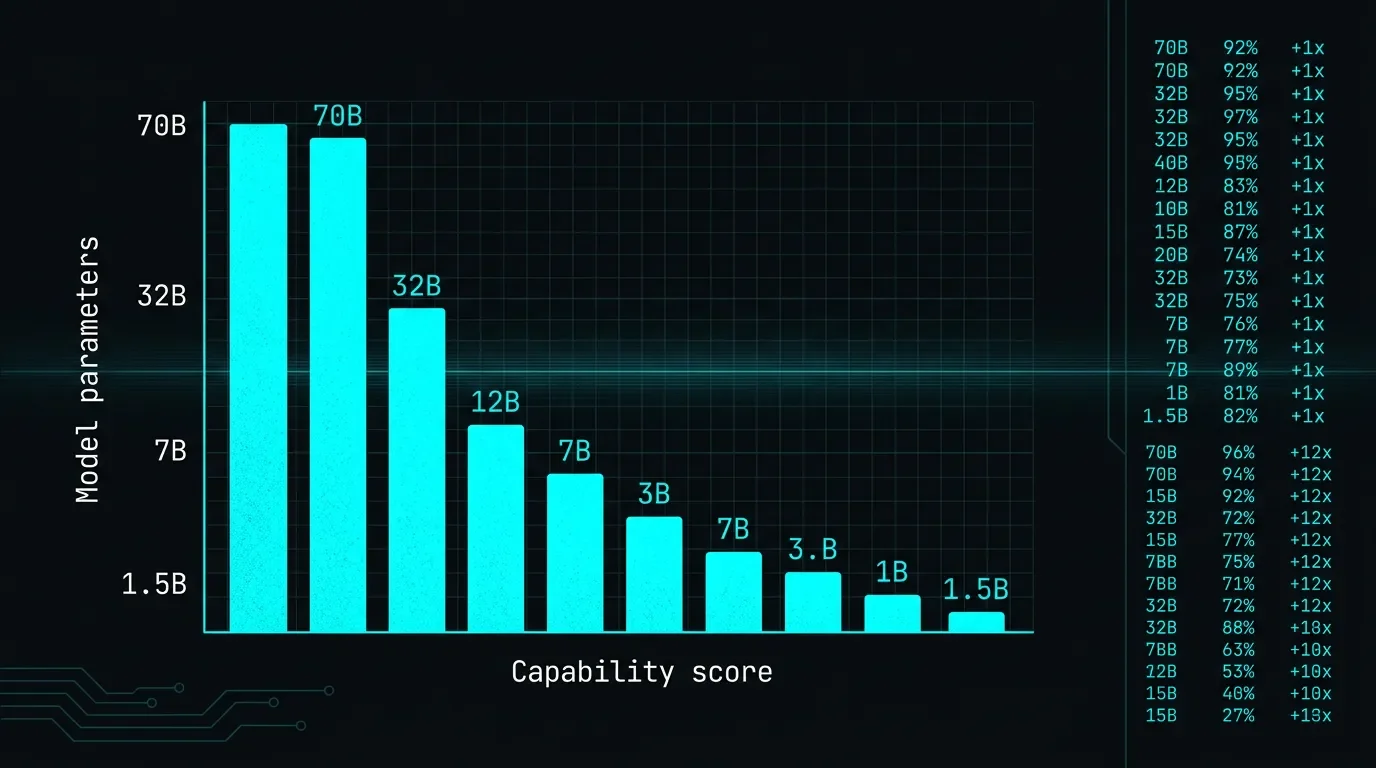
DeepSeek's R1 distilled 7B model scores 55.5% on AIME 2024 -- versus GPT-4o's 9.3% -- at roughly 1/40th the serving cost of the full 671B model. This issue traces the exact technique behind that compression, compares it to a newer non-parametric approach that achieves similar accuracy recovery with zero weight changes, and examines why person distillation -- capturing how a specific human reasons -- remains at a much earlier rung.

이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.