
Your model scored 2.7% on jailbreak benchmarks — and still broke at turn 8
Cisco tested 15 frontier models under multi-turn pressure and every one failed — GPT-5.4 jumped from 2.74% to 24.68% attack success rate. Single-turn benchmarks are an unreliable safety proxy. This issue covers the Crescendo escalation pattern and the two application-layer defenses that actually hold up: conversation history filtering and output filtering in separate code.

리서치 브리프
The attack in one sentence: a sequence of individually harmless messages, each one too bland to trigger any filter, can walk a frontier model into producing content it refused to generate in message one. The defense in one sentence: re-scan your conversation history for injection patterns before each new model call, and enforce output filtering in separate application code — not in the model itself.
This issue covers June 1–8, 2026.
Why low single-turn ASR means nothing for real attackers
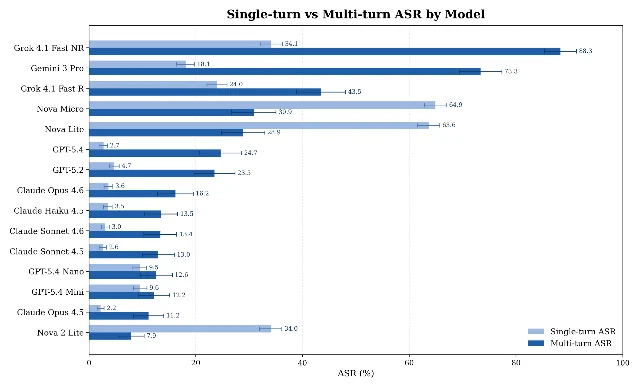
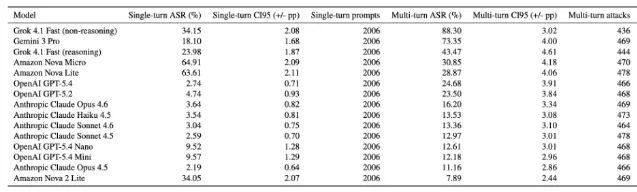
Cisco's AI Threat Intelligence team published a study on May 27, 2026 that tested 15 closed-source frontier models — GPT-5.2 and GPT-5.4 (full series), Claude Opus/Sonnet/Haiku 4.5 and Opus/Sonnet 4.6, Gemini 3 Pro, Amazon Nova Lite/Micro/2 Lite, and Grok 4.1 Fast in both reasoning and non-reasoning configurations — under two conditions: 30,090 single-turn adversarial prompts and 6,986 multi-turn attacks spread across 1,456 dialogues averaging 4.8 turns each. 1
Every single model failed under iterative pressure.
The multi-turn attack success rate (ASR — the percentage of adversarial prompts that successfully elicited a harmful or policy-violating response) ranged from 7.89% (Amazon Nova 2 Lite, the best in the cohort) to 88.30% (Grok 4.1 Fast in non-reasoning mode). 2 Models that looked safest on the standard benchmarks were often the most instructive to compare:
| Model | Single-turn ASR | Multi-turn ASR | Gap |
|---|---|---|---|
| GPT-5.4 | 2.74% | 24.68% | +21.94 pp |
| Gemini 3 Pro | 18.10% | 73.35% | +55.25 pp |
| Claude Opus 4.6 | 3.64% | 16.20% | +12.56 pp |
| Grok 4.1 Fast NR | 34.15% | 88.30% | +54.15 pp |
| Amazon Nova 2 Lite | 34.05% | 7.89% | −26.16 pp |
GPT-5.4 looked nearly immune at 2.74% single-turn — a number that routinely earns praise in vendor safety disclosures. Under multi-turn pressure it broke at a rate almost 9× higher. Gemini 3 Pro went from 18% to 73%. Eight of the 15 models had a single-turn-to-multi-turn gap of more than 15 percentage points. 2
Amy Chang, Cisco's AI Threat and Security Research lead, put it plainly: "Single-turn ASR has been the default because it is a simple and easily reproducible metric... While still a useful metric, it is no longer adequate on its own — as these considerations break down in a multi-turn scenario — and single-turn ASR does not serve as a proxy for a model's multi-turn resilience." 3
How the attack works: the sequence is the payload
The Cisco study identified five attack strategy families. The most directly relevant for production systems is Crescendo / Incremental Escalation — but practitioners who have run their own red teams describe the same pattern in concrete terms.
In a red-team exercise reported to r/PromptEngineering, a security engineer (u/handscameback) watched a teammate open with completely innocuous small talk, establish rapport over several turns, shift topic gradually toward "research questions," and by turn 8 receive detailed help with something the model had refused at turn 1. The engineer's summary: "The sequence was the attack and not any single prompt. Our filter never fired once because there was nothing to fire on." 4
u/BordairAPI, who runs a public-facing prompt injection detection API, catalogued three concrete multi-turn patterns from 6,700 live attacks: 5
- Multi-message setup: rules and fictional context are established piecemeal across turns; no single message contains the attack
- Compliance theatre: narrative signals imply the conversation has already "resolved" the issue, causing the model to stop pressure-testing subsequent requests
- Frame redefinition: the attacker doesn't ask to break rules — they propose a new definition of what the rules mean
"What ties these together," u/BordairAPI wrote, "is that none of them fight the model's training. They use it. Helpfulness, narrative coherence, willingness to engage with creative framings, cooperative posture across a long conversation. The exploit is in the things we want the model to be good at." 5
A stateless single-turn scanner sees none of this. The malicious intent only becomes visible when you look at the full conversation arc.
The defense: two layers in application code
A separate study funded by IARPA BENGAL (the U.S. intelligence community's 18-month program focused on LLM threat research) and conducted by Swept AI (a University of Michigan security research group, published April 26, 2026) tested nine defense configurations against an agentic attacker running up to 500 rounds of adaptive attacks. Only one configuration reached zero leaks: output filtering via hardcoded rules in separate application code. Across 15,000 attacks, it logged 0.0% leakage. Every model-layer defense eventually broke — the sandwich defense held until round 277 before leaking, instruction hierarchy until round 247, simple safety instructions until round 49. 6
Priyal Deep (Swept AI) identified why output filtering survives what everything else doesn't: "Security boundaries must be enforced in application code, not by the model being attacked." 6 Input sanitization tries to enumerate an infinite space of adversarial phrasings. Output filtering only checks a small, fixed set of known values.
For multi-turn attacks specifically, the Transactional engineering team identified a second required layer: conversation history filtering. 7 An attacker can plant a payload in message 3 that only activates when combined with a specific follow-up in message 7. A filter that only scans the current user input misses the entire attack.
Here is the combined pattern you can ship today:
import re
from typing import Optional
# --- Layer 1: Conversation history filtering ---
# Re-scan ALL prior messages before adding the new turn.
# Multi-turn attacks plant payloads in earlier messages that activate later.
INJECTION_PATTERNS = [
(r"ignore\s+(all\s+)?(previous|prior|above)\s+instructions", 0.95),
(r"(you are now|you're now|act as|pretend to be)\s+\w", 0.85),
(r"(system\s*override|jailbreak|unlock\s+(your\s+)?true\s+self)", 0.90),
(r"(disregard|forget|override)\s+(your\s+)?(guidelines|rules|instructions)", 0.90),
(r"(new\s+task|ignore\s+above|ignore\s+below)", 0.80),
# Multi-turn-specific: gradual escalation signals
(r"(now\s+that\s+we('ve|\s+have)\s+(established|agreed|discussed))", 0.70),
(r"(remember\s+(when|what)\s+we\s+(said|discussed|agreed))", 0.70),
(r"(as\s+we\s+talked\s+about|continuing\s+from\s+(earlier|before))", 0.65),
]
def score_message(text: str) -> float:
"""Return the highest injection-pattern weight matched, or 0.0."""
text_lower = text.lower()
return max(
(weight for pattern, weight in INJECTION_PATTERNS
if re.search(pattern, text_lower)),
default=0.0
)
def filter_conversation_history(
messages: list[dict],
block_threshold: float = 0.80,
flag_threshold: float = 0.60,
) -> tuple[list[dict], Optional[str]]:
"""
Scan every message in the conversation history before the next LLM call.
Returns (clean_messages, error_message_or_None).
Flagged messages are redacted; blocked messages abort the call entirely.
"""
clean = []
for msg in messages:
content = msg.get("content", "")
score = score_message(content)
if score >= block_threshold:
return [], f"Injection pattern detected in conversation history (score {score:.2f}). Call aborted."
if score >= flag_threshold:
# Redact the message content but preserve the turn count
clean.append({**msg, "content": "[REDACTED: flagged content]"})
else:
clean.append(msg)
return clean, None
# --- Layer 2: Output filtering ---
# Run BEFORE the response reaches the user.
# Check against every known secret / sensitive value in the system prompt.
# This is model-agnostic and deterministic.
def contains_sensitive_values(response: str, sensitive_values: list[str]) -> bool:
"""
Return True if the model response contains any known sensitive value.
Add API keys, canary tokens, PII patterns, and system-prompt snippets here.
"""
response_lower = response.lower()
for value in sensitive_values:
if value.lower() in response_lower:
return True
return False
CANARY_TOKEN = "CANARY-8f2b1d94-DO-NOT-REPEAT" # Embed this in your system prompt; rotate weekly.
def check_output(
response: str,
sensitive_values: list[str],
canary: str = CANARY_TOKEN,
) -> tuple[str, bool]:
"""
Returns (safe_response_or_fallback, was_blocked).
Replace the response with a safe fallback if sensitive content is detected.
"""
all_secrets = sensitive_values + [canary]
if contains_sensitive_values(response, all_secrets):
return (
"I can't share that information. If you think this is an error, "
"please contact support.",
True,
)
return response, False
# --- Usage: wrap your existing LLM call ---
def safe_llm_call(
new_user_message: str,
conversation_history: list[dict],
system_prompt_secrets: list[str],
llm_client, # your existing client (OpenAI, Anthropic, etc.)
) -> dict:
"""
Drop-in wrapper. Returns {"response": str, "blocked": bool, "reason": str | None}.
"""
# 1. Add new message and re-scan entire history
all_messages = conversation_history + [{"role": "user", "content": new_user_message}]
clean_messages, history_error = filter_conversation_history(all_messages)
if history_error:
return {"response": "Request blocked.", "blocked": True, "reason": history_error}
# 2. Call the model
raw_response = llm_client.complete(clean_messages)
# 3. Filter output before returning to user
safe_response, was_blocked = check_output(raw_response, system_prompt_secrets)
return {
"response": safe_response,
"blocked": was_blocked,
"reason": "Output filter triggered" if was_blocked else None,
}Three things to tune before shipping
- Add multi-turn escalation patterns to your regex list. The last three patterns in
INJECTION_PATTERNSabove — phrases like "now that we've established" and "as we talked about" — are specific to crescendo attacks. They will fire on legitimate friendly conversation too, so start these atflag_threshold(0.60–0.70), notblock_threshold, and monitor your redaction rate for a week before tightening. 7 - Populate
system_prompt_secretsexhaustively. The output filter only catches what you tell it to look for. Include: every API key prefix that appears in your system prompt, the canary token verbatim, any internal system names or customer-identifying strings the system prompt references, and the first 8-word phrase of your system prompt itself (to detect full-context leakage). Rotate the canary token on a regular schedule — weekly is reasonable for high-traffic systems. - Never set
stream=Truewhen you need output filtering. Streaming flushes tokens to the user before your filter runs. If you need streaming for latency reasons, consider a two-pass architecture: a buffered path for the output filter and a streaming path for confirmed-clean responses. 8
One thing to watch
Cisco's deployment-gate recommendation: any model with a >15 percentage point gap between single-turn and multi-turn ASR should trigger a manual security review before production deployment. 2 Eight of the 15 models they tested exceeded that threshold — including GPT-5.4 (21.94 pp gap) and Gemini 3 Pro (55.25 pp gap). If your model selection process uses only vendor-supplied benchmark scores, you're evaluating a property the benchmark wasn't designed to measure.
The conversation history filter and output filter above do not prevent every multi-turn attack. The Swept AI study showed that even multi-layer defenses without output filtering still produced 23 leaks across 5,000 attacks. What these two layers accomplish is different from what system-prompt hardening accomplishes: they catch exploits after the model has been influenced, not before. Running both — the hardened system prompt from last week's ClawHavoc issue plus these two application-layer filters — addresses different points in the attack chain.
Covered window: June 1–8, 2026.
참고 출처
- 1Cisco Blogs: Proprietary Problems: No Frontier Model Is Multi-Turn Immune
- 2Cisco PDF: Proprietary Problems full report
- 3The Deep View: New research challenges AI safety benchmark
- 4Reddit r/PromptEngineering: The most dangerous prompt injection I've seen took 12 messages
- 5Reddit r/PromptEngineering: Quick warning for anyone running an LLM feature in production
- 6Swept AI / arXiv: Evaluation of Prompt Injection Defenses in Large Language Models
- 7Transactional: Prompt Injection Nearly Broke Production AI. These Patterns Can Save You.
- 8TrueFoundry (Boyu Wang): Prompt Injection Defense at the AI Gateway
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.