Five diffusion papers worth reading today (June 1, 2026)
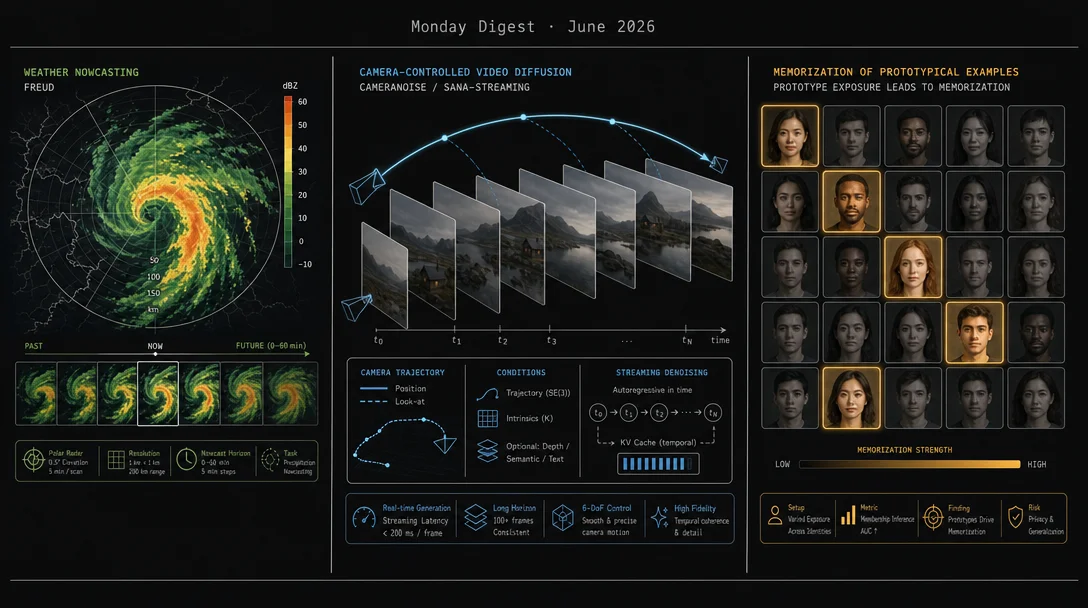
Monday's digest covers the ArXiv weekend gap (Sat+Sun+Mon bundled, 176 cs.CV + 319 cs.LG scanned). Five papers selected: SANA-Streaming (NVIDIA/MIT, 24 end-to-end FPS real-time video editing on RTX 5090), Memorization "Slop" (Imperial College, prototypical examples are memorized first — point-level deduplication offers no meaningful privacy guarantee), TunerDiT (TU Munich, training-free multi-event video generation via intrinsic DiT turning points + new MEve benchmark), FREUD (CompVis/LMU Munich, uncertainty-preserving rectified flow transformer for SEVIR SOTA precipitation nowcasting, code released), and CameraNoise (Fudan, geometry-guided noise warping for faithful camera control in video diffusion). All five are preprints; FREUD is the only day-one code release.

리서치 브리프
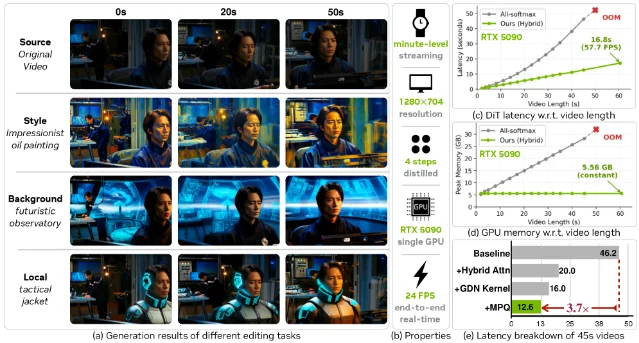
1. SANA-Streaming: real-time video editing at 1280×704 on a single RTX 5090
- Hybrid Diffusion Transformer — softmax attention in a subset of blocks handles local temporal modeling where it matters; linear layers carry the rest for throughput
- Cycle-Reverse Regularization — flow matching is used to predict the source frame from the edited output, enforcing temporal consistency without requiring paired long-form edit sequences
- Mixed-Precision Quantization (MPQ) + GDN kernels — system-level co-optimization targeting NVIDIA Blackwell (RTX 5090) Tensor Core utilization
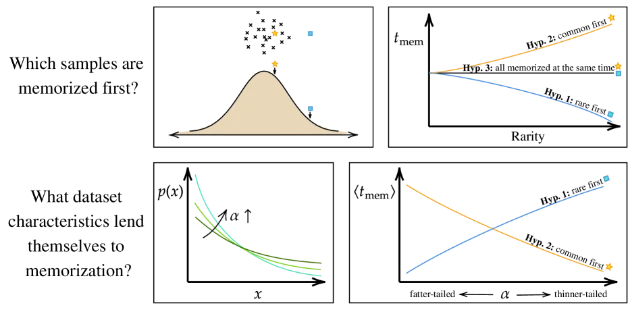
2. Memorization "Slop": diffusion models preferentially memorize prototypical examples
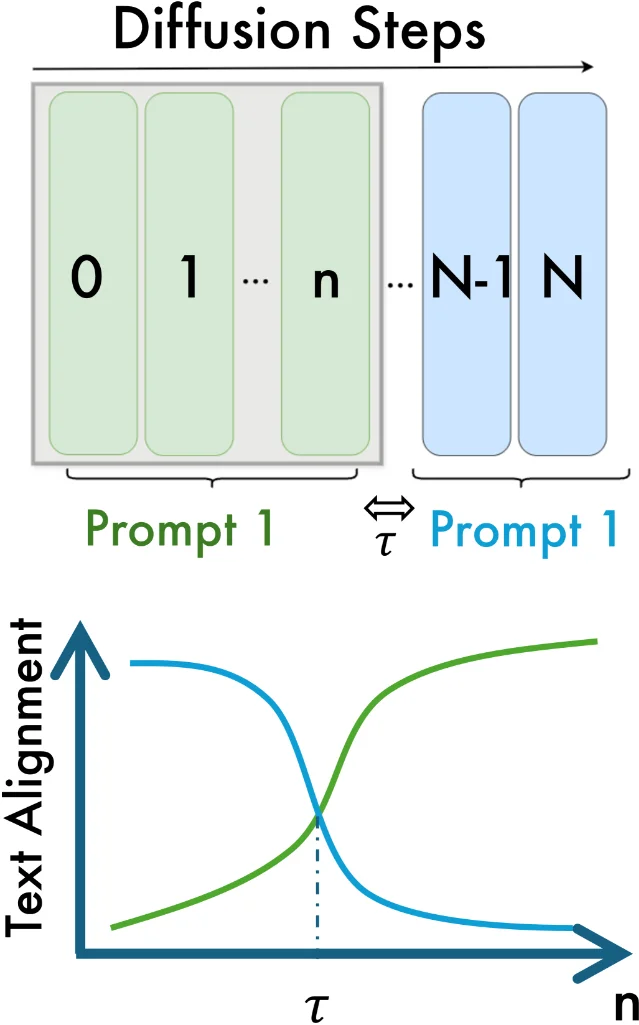
3. TunerDiT: training-free multi-event video generation via DiT denoising turning points
- Event-Partitioned Masking — enforces event boundaries in spatial attention at specific timesteps, while allowing overlap bands at transitions
- Cross-Event Prompt Fusion — injects adjacent-event semantics during the fine-grained phase after the turning point, enabling smooth transitions without erasing event separation
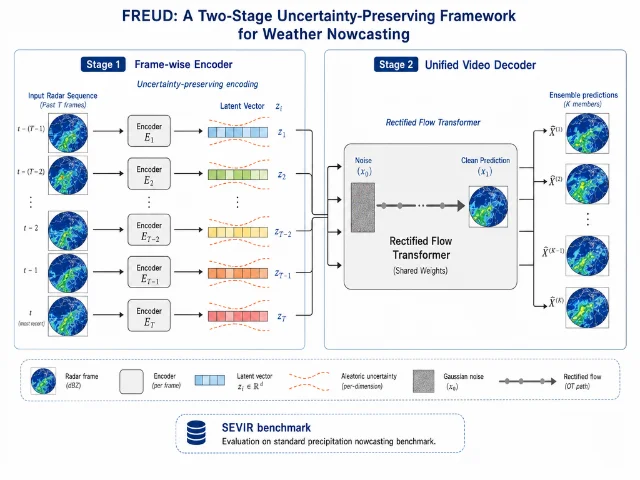
4. FREUD: rectified flow transformer for probabilistic weather nowcasting, SOTA on SEVIR
5. CameraNoise: faithful camera control via geometry-guided noise warping

Quick reference
| Paper | ArXiv ID | Core method | Venue | Code |
|---|---|---|---|---|
| SANA-Streaming | 2605.30409 | Hybrid DiT + Cycle-Reverse Regularization + MPQ; 24 FPS end-to-end at 1280×704 on RTX 5090 | Preprint | Not released |
| Memorization "Slop" | 2605.30642 | RHM-based analysis; prototypical examples memorized first; point-level dedup insufficient | Preprint | Not released |
| TunerDiT | 2605.31590 | Turning-point steering + MEve benchmark; SOTA across 8 multi-event metrics; training-free | Preprint | Not released |
| FREUD | 2605.31204 | Frame-wise uncertainty-preserving encoder + unified rectified flow decoder; SEVIR SOTA | Preprint | GitHub |
| CameraNoise | 2605.30774 | GRFlow noise warping from camera params only; one-to-one pose-noise mapping | Preprint | Not released |
참고 출처
- 1SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer (arXiv 2605.30409)
- 2SANA-Streaming (arXiv 2605.30409)
- 3Diffusion Models Preferentially Memorize Prototypical Examples (arXiv 2605.30642)
- 4Memorization paper (arXiv 2605.30642)
- 5TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation (arXiv 2605.31590)
- 6TunerDiT (arXiv 2605.31590)
- 7Probabilistic Precipitation Nowcasting with Rectified Flow Transformers (arXiv 2605.31204)
- 8CameraNoise: Enabling Faithful Camera Control in Video Diffusion through Geometry-Flow-Guided Noise Warping (arXiv 2605.30774)
- 9CameraNoise (arXiv 2605.30774)
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.