
Claude Opus 4.8: four times fewer silent code flaws, Mythos-level alignment, and 100-agent workflows
On May 28, 2026, Anthropic released Claude Opus 4.8 — an upgrade that cuts unremarked code flaws by 4x versus Opus 4.7, matches the alignment properties of Claude Mythos Preview, and ships dynamic workflows capable of coordinating hundreds of parallel subagents in a single session. Pricing is unchanged. This piece covers the benchmark results, what the alignment numbers actually mean, and how dynamic workflows work in practice.

리서치 브리프
On May 28, 2026, Anthropic released Claude Opus 4.8 — not a generation change, but a targeted upgrade that landed on a specific set of problems that matter most for the people running Opus in production: reliability in agentic coding tasks, honesty about what it has and hasn't done, and alignment properties that now, for the first time, match the company's most safety-constrained model.
Pricing stayed flat at $5/$25 per million input/output tokens. The API model string is
claude-opus-4-8. Simultaneously, three new features shipped: dynamic workflows for Claude Code, effort control in claude.ai, and a Messages API change that lets developers push mid-task instruction updates without breaking the prompt cache. 1Four times less likely to miss its own bugs
The headline capability claim in the release is about honesty, not raw benchmark performance. AI coding assistants have a well-known failure mode: they confidently generate or review code and silently pass over flaws rather than flagging uncertainty. Anthropic's internal evaluations show Opus 4.8 is around four times less likely than Opus 4.7 to allow flaws in code it has written to go unremarked.
This is a qualitative shift for anyone relying on Claude for production code review. Multiple early testers made the same observation independently. Cursor's team reported that Opus 4.8 "exceeds prior Opus models across every effort level" on CursorBench, with tool calling that "uses fewer steps for the same intelligence." Devin's team, which runs autonomous engineering workloads unattended, said 4.8 "uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need." They also flagged something specific: 4.8 fixes the "comment-verbosity and tool-calling issues we saw with Opus 4.7."
The framing here matters. Anthropic trained all previous Opus models to be honest in the sense of not making claims they can't support. What Opus 4.8 changes is the agentic application of that principle — the tendency to press forward regardless, which often manifests as overconfidence in code review. The four-times figure is a proxy for a genuine behavioral change in long-running workflows where catching errors before merge is the actual job.
What the benchmarks actually show
Opus 4.8 leads the published field on five of six benchmark categories, with one notable exception.
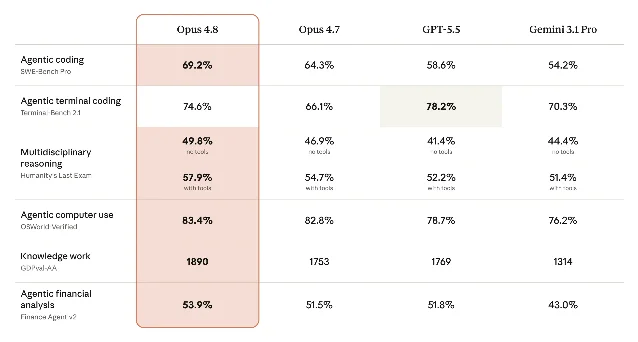
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Agentic coding (SWE-Bench Pro) | 69.2% | 64.3% | 58.6% | 54.2% |
| Agentic terminal coding (Terminal-Bench 2.1) | 74.6% | 66.1% | 78.2% | 70.3% |
| Multidisciplinary reasoning, no tools (Humanity's Last Exam) | 49.8% | 46.9% | 41.4% | 44.4% |
| Multidisciplinary reasoning, with tools | 57.9% | 54.7% | 52.2% | 51.4% |
| Agentic computer use (OSWorld-Verified) | 83.4% | 82.8% | 78.7% | 76.2% |
| Knowledge work (GDPval-AA) | 1890 | 1753 | 1769 | 1314 |
| Agentic financial analysis (Finance Agent v2) | 53.9% | 51.5% | 51.8% | 43.0% |
GPT-5.5 takes Terminal-Bench 2.1 at 78.2% versus Opus 4.8's 74.6% — a gap worth watching for teams doing heavy shell-based automation. On every other reported dimension, Opus 4.8 leads, with the most significant jump on pure reasoning: Humanity's Last Exam with no tools goes from 41.4% (GPT-5.5) to Opus 4.8's 49.8%, a spread of over 8 percentage points. 1
The legal results deserve a separate mention. Harvey reported that Opus 4.8 "delivers the highest score recorded on our Legal Agent Benchmark, and is the first model to break 10% overall on the all-pass standard." CoCounsel noted "meaningful improvements in consistency and reasoning quality" for fiduciary-grade workflows. In domains where a single missed clause has consequences, the 4x reduction in unremarked code flaws translates directly into how much attorney work customers will hand off.
Dynamic workflows: hundreds of parallel subagents
The more architecturally interesting launch item is dynamic workflows in Claude Code — a feature that lets Claude spawn and coordinate hundreds of parallel subagents within a single session, all checking each other's work before results surface. 2
The use cases Anthropic and early users have demoed are genuinely large-scale:
- Codebase-wide migrations: Jarred Sumner used dynamic workflows to port Bun from Zig to Rust — roughly 750,000 lines of Rust, 99.8% of the existing test suite passing, eleven days from first commit to merge. One workflow mapped Rust lifetimes for every struct field; a second wrote every
.rsfile as a behavior-identical port of its.zigcounterpart, with hundreds of agents working in parallel and two reviewers per file; a fix loop then drove build and test until both ran clean. - Security audits across entire services: Claude searches a repo in parallel, runs independent verification on every finding, and surfaces only confirmed issues.
- Adversarial verification: When the cost of a wrong answer is high, a workflow gives Claude independent attempts at the problem, then assigns adversarial agents to try to break each result.
The coordination model matters here: plans are formed dynamically from the prompt rather than pre-programmed, subtasks fan out across agents running in parallel, and results are checked before being folded in. Progress is saved as the run goes, so an interrupted job picks up rather than restarts. This is meaningful for tasks that extend into hours or days.
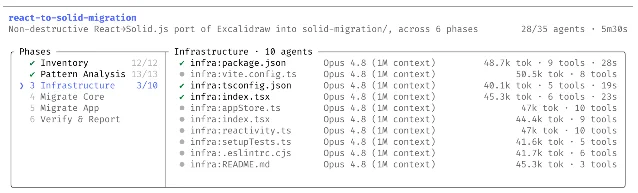
The token consumption caveat is real: dynamic workflows use "meaningfully more usage than a typical Claude Code session." Anthropic recommends starting on a scoped task. For Enterprise plans, workflows are off by default — admins enable via the Claude Code settings panel. For Max and Team plans, they're on by default.
Effort control and the Messages API change
Two quieter additions in this release will matter more to developers than their brief descriptions suggest.
Effort control is now available to all claude.ai and Cowork users via a control alongside the model selector. At higher effort settings, Opus 4.8 thinks more frequently and more deeply; at lower settings, it responds faster and uses rate limits more slowly. In Claude Code, the
xhigh effort level (labeled "extra") is recommended for difficult tasks and long-running asynchronous workflows. The ultracode setting is a new Code-specific mode that sets effort to xhigh and lets Claude decide automatically when to spin up a dynamic workflow.Anthropic's note on the default is specific: Opus 4.8 defaults to
high effort, which it judges as "the best overall balance of quality and user experience." On coding tasks, this spends a similar number of tokens as Opus 4.7's default — but the performance at that token budget is meaningfully better.The Messages API now accepts
system entries inside the messages array. Previously, updating Claude's instructions mid-task meant routing the update through a user turn, which broke the prompt cache or required awkward workarounds. The new behavior lets developers push updated permissions, token budgets, or environment context as an agent runs, without disrupting the cache. For teams running complex multi-step agent harnesses, this removes a common pain point that previously required either caching sacrifices or architectural gymnastics.The alignment angle: reaching Mythos-level misalignment rates
Anthropic runs a detailed alignment assessment before every release, and the Opus 4.8 results are worth reading carefully — not because the numbers are perfect, but because of what they're being compared against.
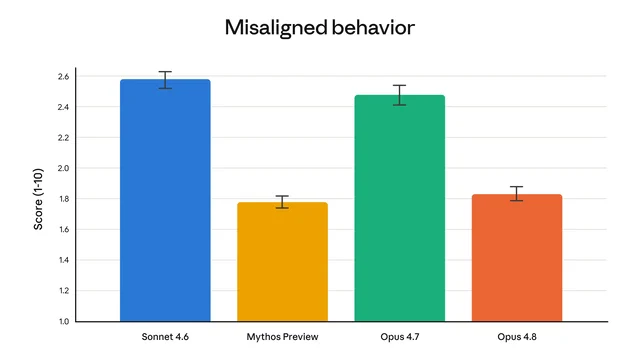
The alignment team's conclusion: Opus 4.8 "reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user's best interest." On misaligned behaviors — specifically deception or cooperation with misuse — rates are "substantially lower than Opus 4.7, and similar to our best-aligned model, Claude Mythos Preview."
That second sentence is the important one. Mythos Preview is the model currently restricted to a small number of organizations under Project Glasswing, Anthropic's cybersecurity initiative, because its capability level requires stronger cyber safeguards before general release. Reaching Mythos-level alignment properties in a generally available model means Anthropic has managed to decouple capability from misalignment risk — at least at this scale of capability.
The misalignment chart (above) shows the score distribution across Sonnet 4.6, Mythos Preview, Opus 4.7, and Opus 4.8 on a 1-10 scale. Opus 4.7 sits close to Sonnet 4.6 at roughly 2.5. Opus 4.8 and Mythos Preview both land near 1.8, a drop of ~0.7 points. Whether a 0.7-point improvement on an internal 1-10 scale constitutes "substantially lower" is a judgment call — but the grouping is telling. Anthropic has put Opus 4.8 in the same bracket as its most safety-restricted model.
What's next — and the Mythos footnote
The announcement closes with two pieces of forward-looking information.
First, Anthropic says it is working on models that deliver "many of the same capabilities as Opus at a lower cost" — which is the expected direction for the Sonnet line, but the framing as a near-term development commitment is new.
Second, and more significant: Anthropic expects to bring Mythos-class models to all customers "in the coming weeks." The release notes that models at Mythos's capability level currently require stronger cyber safeguards before general release — and that work is in progress. When Mythos ships broadly, the alignment properties now present in Opus 4.8 will be combined with substantially higher capability. The alignment work that went into 4.8 is, in effect, a public preview of what Anthropic's team expects to have ready when that model ships.
The upgrade from Opus 4.7 to 4.8 is incremental by design — Anthropic describes it as "a modest but tangible improvement." What makes it notable is that the modesty is concentrated in capability gains and the tangibility is concentrated in behavioral reliability: honesty about errors, alignment parity with Mythos, and an architecture that can orchestrate 100-agent workflows. Those are exactly the properties that matter for the long-running, high-stakes workloads that the Opus line is built for.
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.