

1/4

Goedel-Architect cracks MiniF2F — Lean 4 × AI-for-Math Weekly #2
2026. 6. 15. · 08:08
갤러리
Week of Jun 8–15, 2026 · Issue #2
Card 1 — Cover
Goedel-Architect hits 99.2% pass@1 on MiniF2F. A Princeton/MIT team released Goedel-Architect (arXiv:2606.06468), an open-source agentic framework centered on blueprint generation and refinement — generating a dependency graph of definitions and lemmas, then closing each node in parallel with a Lean prover. Using DeepSeek-V4-Flash (284B-A13B) as backbone, it attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench without any natural-language proof hints — and with optional NL seeding reaches 100% MiniF2F, 88.8% PutnamBench (597/672), 4/6 IMO 2025, 11/12 Putnam 2025, and 3/6 USAMO 2026. Claimed to be 500× cheaper than comparable open-source pipelines at these scores. Code is public.
Also: OProver-32B (M-A-P / Nanjing University, arXiv:2605.17283) achieves 93.3% MiniF2F @pass@32, outperforming DeepSeek-Prover-V2 671B across all five benchmarks with a 32B model. Fully open-weight with OProofs corpus (1.77M Lean statements, 6.86M compiler-verified proofs).
LeanMarathon: 7 Erdős-related theorems formalized, 0 sorries, 258 lemmas.
Card 2 — Prover Leaderboard
MiniF2F-test, June 2026:
| Prover | pass@1 | pass@32 |
|---|---|---|
| Goedel-Architect | 99.2% | 100%* |
| OProver-32B | — | 93.3% |
| DeepSeek-Prover-V2 (671B) | 61.9% | 88.9% |
*100% requires NL proof seeding on the remaining 2 problems
PutnamBench (pass@1 unless noted):
- Goedel-Architect: 75.6% (no NL seed) / 88.8% (with NL seed, 597/672)
- OProver-32B: 11.3% @pass@32
- DeepSeek-Prover-V2: ~7.4% @pass@1024 (prior result)
Notes for reproducibility:
- Goedel-Architect uses DeepSeek-V4-Flash API; pass@1 reported on standard MiniF2F-test split.
- OProver reports pass@32 (unbiased estimate over n=64 rollouts); no independent external replication yet for either system.
- Kimina-Prover (not yet reported on these specific splits this week).
Card 3 — New Benchmarks & Harnesses
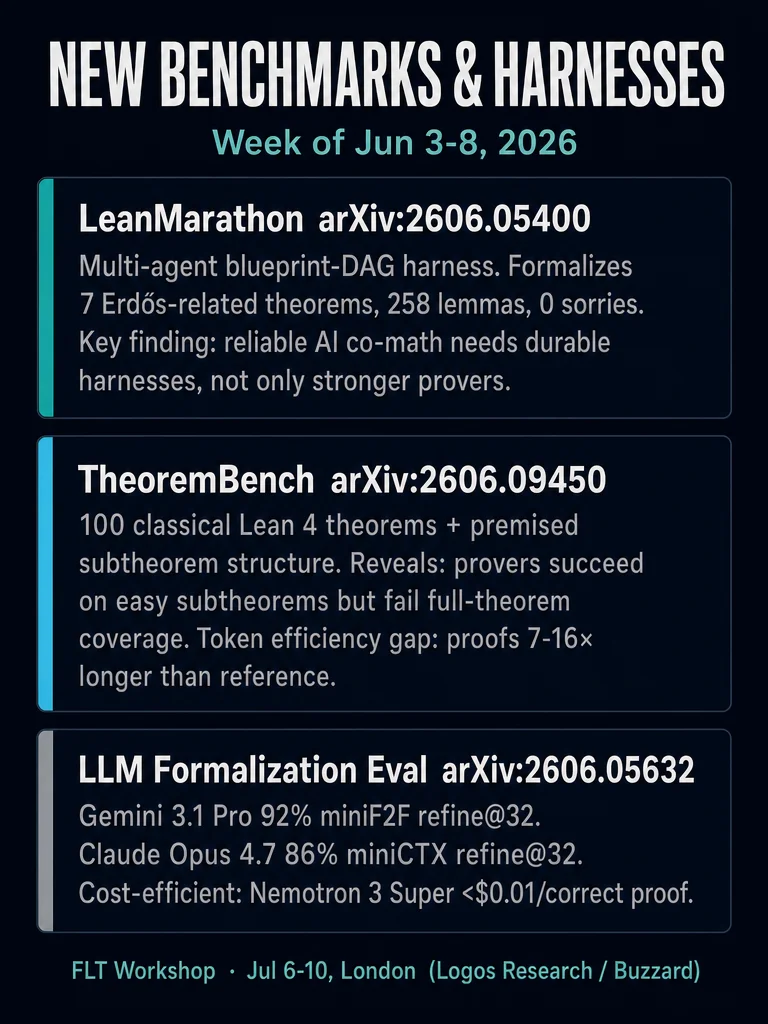
LeanMarathon (arXiv:2606.05400, Jun 3) — A multi-agent blueprint-DAG harness for long-horizon autoformalization. Four contract-scoped agents (construct, audit, prove, repair) operate on an evolving blueprint file. In three autonomous runs, it formalizes all 7 target theorems spanning 4 Erdős problems, 258 lemmas, 0 sorries. Key claim: "reliable AI co-mathematics requires not only stronger provers, but durable harnesses that preserve target fidelity." Code on GitHub. No independent external replication yet.
TheoremBench (arXiv:2606.09450, Jun 8) — ~100 classical theorems in Lean 4, released in plain and premised variants (main theorem + automatically extracted supporting subtheorems). DeepSeek-Prover-V2-7B tops at premised pass@64 = 0.46; Goedel-Prover-V2-8B = 0.33; Kimina-Distill-8B = 0.22. Finding: provers are strongly biased toward easy subtheorems; generated proofs are 7–16× longer than reference proofs (token efficiency gap). Benchmark code/data released.
LLM Formalization Eval (arXiv:2606.05632, Jun 4) — Compares frontier LLMs on miniF2F and miniCTX using refine@32. Gemini 3.1 Pro: 92% miniF2F refine@32. Claude Opus 4.7: 86% miniCTX refine@32. Cost-efficient options: Nemotron 3 Super and GPT-OSS 120B at <$0.01/correct proof. Caveat: refine@32 ≠ pass@1; single-attempt reliability not established.
FLT Workshop — Kevin Buzzard's formalization workshop runs Jul 6–10, 2026, London, funded by Logos Research. Goal: experiment with AI autoformalization of FLT prerequisites. Buzzard notes autoformalization still unreliable on definition-heavy material. No new sorries closed in FLT repo this week. EPSRC TCC lecture notes (11 lectures) now public on GitHub.
Card 4 — Signal vs Hype
Verification audit this week:
| Item | Verdict |
|---|---|
| Goedel-Architect 99.2% pass@1 MiniF2F | ✓ Lean kernel-verified, open-source pipeline |
| OProver 32B beats DeepSeek 671B | ✓ Open weights + OProofs corpus public |
| LeanMarathon 0 sorries, 7 theorems | ✓ GitHub artifacts, runnable |
| TheoremBench coverage finding | ⚠ No external replication yet |
| LLM Eval Gemini/Claude scores | ⚠ refine@32 budget, not pass@1 |
Persistent flags:
- PutnamBench gains for Goedel-Architect depend on NL seeding (human-provided proof outlines). Strong result, but pass@1 without seeding (75.6%) is the more conservative baseline.
- OProver's training relies on OProofs corpus bootstrapped from public Lean resources; contamination with miniF2F training split not explicitly audited.
- FLT formalization: no new sorry closures this week. Workshop Jul 6–10 is the next milestone.
- Mathlib Initiative: no new public Q2 metrics this week; last known trajectory on track for <1-week PR review cycles.
Editorial weight this issue: Goedel-Architect and OProver are the two strongest open-weight results — both with public artifacts. LeanMarathon is the most interesting methodological contribution. TheoremBench and the LLM Eval are useful calibration tools with honest limitations. Hype discount applied to competition-benchmark headlines without pass@1 reporting.
Primary sources: arXiv:2606.06468 · arXiv:2605.17283 · arXiv:2606.05400 · arXiv:2606.09450 · arXiv:2606.05632 · Xena/FLT workshop
댓글