Memory 技术日报 2026-06-16:KV 共享、可执行用户记忆、搜索栈持久化
本期筛出 3 条大模型 memory 方向的一手进展:SwiftCache 用跨模型显存共享降低长对话 KV 加载成本,User as Code 把个性化记忆变成可执行状态,Elastic 展示用 Elasticsearch 承载 Claude Code 跨会话记忆的工程路线。读完可快速判断今天该跟进哪一层 memory 基础设施。

리서치 브리프
先看结论
今天的三条 memory 进展指向同一件事:大模型的「记忆」正在从提示词里的历史记录,拆成三层可优化的基础设施:KV 缓存怎么放、用户状态怎么表达、跨会话记忆怎么检索。本期覆盖窗口为 2026-06-15 10:00 至 2026-06-16 10:00(北京时间);入选条目均来自本轮可打开的一手论文或工程博客。
| 方向 | 本期进展 | 关键数字 / 机制 | 最该跟进的人 |
|---|---|---|---|
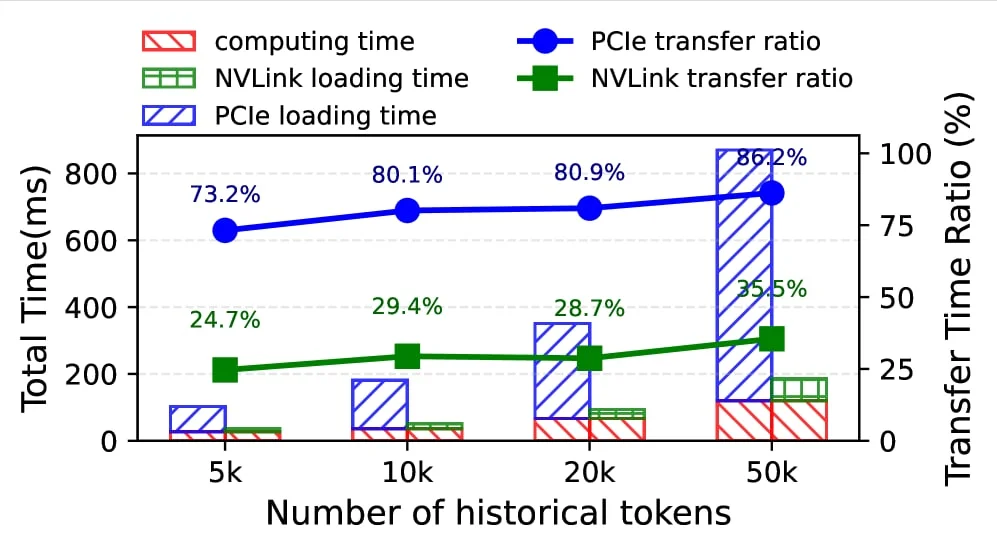
| KV 缓存调度 | SwiftCache 把低 KV 需求模型的空闲 GPU 显存借给高需求模型,通过 NVLink 做跨模型 KV 共享 1 | P99 TTFT 最高降低 69%,最大上下文长度最高扩展 3.98 倍 1 | 做多模型 serving、长对话、agent 后端的人 |
| 个性化长期记忆 | User as Code 把用户记忆表示成 typed Python 状态和可执行规则,而不是只做向量检索 2 | LOCOMO 78.8%;聚合型问题 UaC 99%,检索式记忆基线为 6%-43% 2 | 做个人助理、CRM agent、长期用户画像的人 |
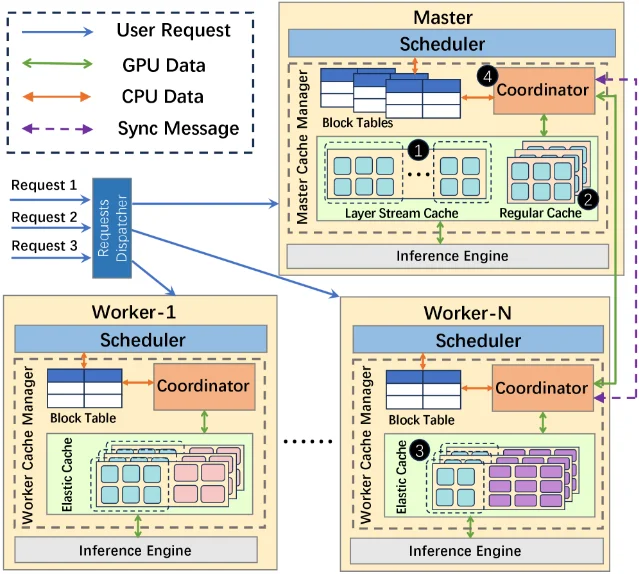
| 工程化 agent memory | Elastic 发布 Claude Code + Elasticsearch 持久记忆方案,利用 hybrid search、ES | QL、知识图谱和 hooks 连接跨会话记忆 3 | 七类索引承载 memory、messages、tasks、sessions、status、entities、entity-history,并用 BM25 + dense vector 融合召回 3 |
1. SwiftCache:KV 缓存不只可以压缩,也可以在模型之间「借显存」
SwiftCache 关注的是多轮对话和 agent 服务里最现实的一类瓶颈:历史 token 越积越多,KV cache 需要在 HBM、CPU 内存、SSD 之间搬运,TTFT 被历史 KV 的加载拖慢。论文观察到,不同模型同机部署时,KV cache 需求并不一致:长上下文模型显存吃紧,短请求模型却可能有空闲 KV 空间。SwiftCache 的做法是让低需求模型把空闲 GPU KV cache block 借给高需求模型,优先走 NVLink,而不是慢得多的 PCIe/CPU 路径 1。
论文的两个设计点值得单独看。第一,Layer Stream Cache 只把当前执行层的 KV 留在本地 GPU,其他层按需从外部显存流入;这利用了「同一时刻只有当前层访问自己的 KV」这一事实。第二,Elastic Cache 用 block-major 布局,让 worker 模型可以在 O(1) 时间把空闲 cache 容量借出或收回 1。
对工程团队的含义是:长上下文优化不只有「少存」一条路。KV 压缩、prefix caching、分层 offload 之外,多模型共部署时的空闲显存也可以成为一类调度资源。如果你的线上系统同时跑 chat、rerank、embedding、短任务 agent,SwiftCache 这类思路比单模型内优化更贴近生产调度问题。
2. User as Code:把用户记忆从「可检索文本」改成「可执行状态」
User as Code 的核心判断很直接:很多个性化记忆问题不是「找出最相似的几条事实」,而是「在一堆事实上做确定性计算」。例如,问「去年我出过几次国?」时,向量检索可能只拿到几条旅行记录;如果用户状态已经是 typed Python list,这个问题就是一行
sum(...)。论文提出两阶段管线:第一阶段保留 append-only fact log,不覆盖原始事实;第二阶段周期性把事实 checkpoint 成 typed Python 对象和规则函数。这样,passport、trip、allergy、medication 等状态不仅能被读取,也能被解释器执行约束检查 2。
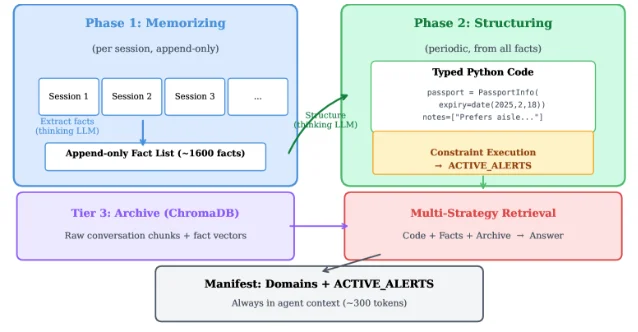
这篇论文最有用的不是「用 Python 存用户资料」这个表层形式,而是它给 memory 产品划出了一条边界:事实召回、聚合分析、主动提醒是三种不同能力。论文报告 UaC 在 LOCOMO 上达到 78.8%,接近 full-context 上界 79.8%;在聚合型 benchmark 上达到 99%,而检索式 memory 基线落在 6%-43% 2。
需要注意的是,这种路线会把 schema 设计、代码生成、版本管理和安全审查拉进 memory 系统。它更适合稳定、强结构、需要跨会话执行规则的用户状态;如果只是短期偏好和松散笔记,文本 memory 仍然更轻。
3. Elastic 的 agent-memory:把搜索索引直接变成跨会话记忆层
Elastic 的方案不是新论文,而是一篇很具体的工程实践:给 Claude Code agent 接上 Elasticsearch,让 session 决策、任务状态、markdown 实体和跨设备 handoff 都进入同一个可检索索引。文章的立场是:如果团队已经有 Elasticsearch,就不必先引入专门 memory 服务,搜索栈本身已经具备 hybrid recall、时间过滤、metadata query 和运维能力 3。
它的架构由
bridge CLI 和七类索引组成:agent-memory 存 decisions、patterns、context、feedback;agent-sessions 记录 action history;{agent}-entities 和 {agent}-entity-history 把 markdown 文件当成可搜索实体和时间快照。Claude Code 的三个 hook 负责自动写入:SessionStart 同步记忆和 heartbeat,PostToolUse 在写入 markdown 时索引实体,Stop 记录 session end 3。
agent-memory 通过 bridge CLI 把 Claude Code hooks、七类 Elasticsearch 索引和知识图谱命令连接起来 3。 这条进展对 RAG / memory 工程有两个提醒。第一,agent memory 不是只有向量相似度:task ID、文件名、版本号、blocked dependency 这类精确锚点需要 BM25;概念性回忆需要 dense vector;时间敏感上下文还需要 temporal decay。第二,记忆系统是否可用,很大程度取决于写入路径是否自动化。靠 agent 主动「记一下」很脆,靠 hooks 把关键动作写入索引更接近生产形态。
今天的工程判断
如果把三条放在一起看,memory 技术的重点正在从「上下文能放多长」转向「哪部分记忆应该以哪种形式存在」。
- 运行时记忆:KV cache 是最贵、最贴近 GPU 的记忆,适合做调度、共享、压缩和 offload。SwiftCache 属于这一层。
- 用户状态记忆:长期个性化不一定适合只用文本检索。User as Code 把可执行状态和规则放到 memory 设计中心。
- 工作流记忆:工程 agent 需要跨会话、跨设备、跨任务回忆决策和实体。Elastic 的方案说明现有搜索栈可以承担这层。
今天最值得带走的一句话:memory 不是单一模块,而是一组不同生命周期、不同延迟预算、不同一致性要求的状态系统。下一步评估 memory 方案时,不要先问「用哪个向量库」,先问这条记忆是 KV、用户状态、文档证据、任务日志,还是可执行规则。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.