
HF Breakout Models, Jun 8–15: MiniMax M3, Kimi-K2.7-Code, and the License Week Builders Waited For
Four HuggingFace models cleared the >10x download-growth bar during June 8–15, led by Kimi-K2.7-Code (Moonshot, 1T/32B active, Modified MIT, 33x growth, 81.1% MCPMark Verified, $0.75/M on OpenRouter), DiffusionGemma (Google DeepMind, 25.2B/3.8B active, Apache 2.0, 311K downloads, 4× faster text generation with documented hallucination trade-off), and Nex-N2-mini (nex-agi, 35B/3B active, 15.9x growth, Qwen3.5 derivative). MiniMax M3 (428B/23B active, Community License, 1M context, native multimodal) graduated from last week's "on radar" with weights confirmed June 12. The week's highest-downloaded model, Rio-3.5-Open-397B (189K downloads), was exposed as a weight-merge fraud by nex-agi.

Three of this week's four qualifying models ship under Apache 2.0 or Modified MIT — the most builder-friendly license week since this radar started. The outlier, MiniMax M3, landed with the biggest capability splash, open weights confirmed on June 12 after spending last week on the radar. Four models cleared the >10x download-growth bar; one week's most-downloaded model (Rio-3.5, 189K downloads) turned out to be a merge fraud.
LLMs
Kimi-K2.7-Code — 1T/32B active, Modified MIT, agentic coding
Moonshot AI (the company behind the Kimi chat product) released Kimi-K2.7-Code on June 12 under a Modified MIT license — both weights and code open. 1 Downloads jumped from ~1.7K (June 13) to 15.1K (June 14) to 56,750 by June 15 — roughly 33x growth in two days. 2
Architecture: 1T total parameters, 32B active per token, MoE with 384 experts (8 per token), 256K context, MLA (Multi-head Latent Attention), MoonViT vision encoder (400M params). The model accepts text, image, and video input and outputs text with thinking mode forced on. It's built on Kimi K2.6 with a specific focus on reducing verbose chain-of-thought: the model card states it reduces thinking-token usage by approximately 30% compared with Kimi K2.6. 1
Key benchmark improvements over K2.6: Kimi Code Bench v2 +21.8% (50.9 → 62.0), Program Bench +11.0% (48.3 → 53.6), MCPMark Verified +11.4% (72.8 → 81.1% — beating Claude Opus 4.8 at 76.4%), MLS Bench Lite +31.5% (26.7 → 35.1, nearly matching GPT-5.5 at 35.5). 1 These are all Moonshot internal or self-reported benchmarks; no independent SWE-bench or LiveCodeBench results exist yet, which makes direct comparison against Fable 5 (SWE-bench Verified 95%) or Claude Sonnet 4.6 approximate at best.
Deployment: vLLM, SGLang, KTransformers. Official API at platform.moonshot.ai is OpenAI and Anthropic API-compatible — the latter means Claude Code works via
ANTHROPIC_BASE_URL override with full MCP, hooks, and skills preserved. 2 Pricing: $0.95/$4.00 per 1M tokens (Moonshot API), $0.75/$3.50 (OpenRouter). Unsloth GGUF arrived June 13; no official Ollama or mainline llama.cpp builds yet. Native INT4 weights require ~340GB, so self-hosting needs a multi-A100 setup.Community reception is positive. One developer who tested it on OpenRouter for security code review noted: "It thinks for a long time but it doesn't go in circles." 3 The a16z-backed ambient.xyz (ambient desktop tool) shipped with K2.7 built in on June 15 and reportedly served 13.2B tokens/day on their OpenRouter endpoint at peak. 2
- License: Modified MIT — commercial use permitted
- Active params: 32B (1T total MoE), 256K context
- Deployment: vLLM, SGLang, KTransformers; Moonshot API and OpenRouter for managed hosting
- Builder angle: at $0.75/M input and $3.50/M output on OpenRouter, K2.7-Code runs roughly 4x cheaper than Claude Sonnet 4.6 on output tokens. 2 For agent loops generating substantial output — multi-file refactors, automated documentation, code review passes — that gap compounds fast. The Anthropic-compatible API makes it a drop-in swap in any Claude Code or agentic workflow. The 30% thinking-token reduction over K2.6 is meaningful for latency-sensitive pipelines. Self-hosting requires serious GPU infrastructure; for most indie builders, the managed API is the practical path.
DiffusionGemma — 25.2B/3.8B active, Apache 2.0, 4× faster text generation
Google DeepMind released DiffusionGemma on June 10 under Apache 2.0 — an experimental text diffusion model that generates text in parallel 256-token blocks rather than token by token. 4 Downloads went from 20.7K (June 12) to 92.1K (June 13) to 199K (June 14) to 311,788 by June 15 — roughly 15x growth in three days. 5

Architecture: 25.2B total parameters, 3.8B active, MoE with 8 active experts out of 128 (plus 1 shared), 30 layers, 256K context, 262K vocabulary. The vision encoder is ~550M parameters. It takes multimodal input (text + image + video) and outputs text — it is not an image generation model, despite some early coverage describing it that way. 5
The speed claim is real: 1,100+ tokens/sec on a single H100 (FP8), 700+ on an RTX 5090. The underlying mechanism shifts generation from memory-bandwidth-bound (one token at a time) to compute-bound (all 256 tokens in a block simultaneously), which is why dedicated GPUs show the most dramatic gains. 4 One independent test on RunPod by Better Stack confirmed the speed but found ~250 tok/s on an RTX 5090, below Google's claimed 700+, suggesting configuration sensitivity.
Quality is the honest trade-off. Google's own blog states that "for applications that demand maximum quality, we recommend deploying standard Gemma 4." 4 An independent benchmark on r/LocalLLaMA by /u/gladkos (1,071 upvotes) compared DiffusionGemma and Gemma 4 on identical factual tasks (H100 FP8, 3 tasks): Gemma 4 produced 45 correct facts / 5 wrong; DiffusionGemma produced 33 correct / 28 wrong — roughly 6x more factual errors. The community explanation: "DiffusionGemma throws 256 tokens on the screen at once and polishes them pass after pass until the text sounds smooth. Smooth is all it cares about: a fake name, date or number sounds just as smooth as a real one, so it stays." 6 A separate follow-up thread proposed 15 mitigation strategies, with the Entropy-Bounded Sampler reportedly fixing ~80% of hallucination cases. 7
Benchmarks vs. Gemma 4 26B A4B: MMLU Pro 77.6% (vs 82.6%), AIME 2026 69.1% (vs 88.3%), LiveCodeBench v6 69.1% (vs 77.1%), GPQA Diamond 73.2% (vs 82.3%). One area where it wins: HLE no tools 11.0% vs Gemma 4's 8.7%. 5
Deployment: Unsloth GGUF available (Q4_K_M at 16GB fits a single 24GB GPU), requires a dedicated llama.cpp branch (PR #24423) with
llama-diffusion-cli. Also supported: vLLM, MLX, NVIDIA NIM, Transformers. 8 Official llama.cpp mainline merge was pending as of June 15; 11 community fine-tunes and 25 quantizations already on HF.- License: Apache 2.0 — commercial use permitted
- Active params: 3.8B (25.2B total MoE), 256K context
- Deployment: vLLM, NVIDIA NIM, MLX, Transformers; Unsloth GGUF for local (Q4_K_M on 24GB GPU)
- Builder angle: the speed/quality trade-off is real and Google was upfront about it. DiffusionGemma is the right call for high-throughput pipelines where factual precision is less critical than generation volume — chatbot suggestion prefill, autocomplete, creative drafts, summarization at scale. For anything requiring fact accuracy (customer-facing answers, legal or medical content, structured data extraction), the hallucination rate rules it out until the mitigation techniques are more established. The Apache 2.0 license means you can ship it immediately once you find the use case that fits.
Nex-N2-mini — 35B/3B active, license unclear, Agentic Thinking
Nex-N2-mini from nex-agi crossed the 10x bar this week: 30-day downloads grew from 518 (June 8) to 8,260 by June 15 — 15.9x growth, reaching the #5 position on HF's text generation trending page. 9
Architecture: 35B total parameters, 3B active, post-trained on Qwen3.5-35B-A3B-Base. The model uses what nex-agi calls an Agentic Thinking framework — adaptive reasoning depth, consistent reasoning across task types, and unified inference for reasoning, tool calling, and environment execution in one pass. 9
The larger sibling, Nex-N2-Pro (397B, based on Qwen3.5-397B-A17B), also grew 5.1x this week (716 → 3,681 downloads) — below the 10x threshold but worth noting alongside N2-mini. The 22-quantization-variant lineup for N2-Pro is available on SiliconFlow's cloud platform. 10
The critical caveat: the license for Nex-N2-mini is not explicitly stated on the HF model card. As a derivative of Qwen3.5, it falls under Qwen3.5's licensing terms — which permit commercial use for organizations under 100M active monthly users, requiring a separate license above that threshold. Verify this directly before deploying commercially, as the inheritance chain isn't formally documented on the model card. 9
- License: Not explicitly stated; inherited from Qwen3.5-35B-A3B-Base — verify before commercial use
- Active params: 3B (35B total MoE)
- Builder angle: 3B active parameters makes N2-mini fast and cheap to run. If you're already using Qwen3.5 derivatives in a pipeline and want a post-trained agentic variant, it's a reasonable test. The license ambiguity is the blocker for production until you trace the Qwen3.5 terms and confirm compatibility with your deployment.
Multimodal
MiniMax M3 — 428B/23B active, Community License, 1M context
Last week's "on radar" item confirmed: MiniMax AI released MiniMax M3 weights on June 12 after announcing the model on June 1. 11 The r/LocalLLaMA release thread accumulated 637 upvotes and 226 comments within 24 hours. Downloads grew from 1.03K (June 13) to 6.64K (June 14) as the community rushed to test; 482 HF likes as of June 14. 12
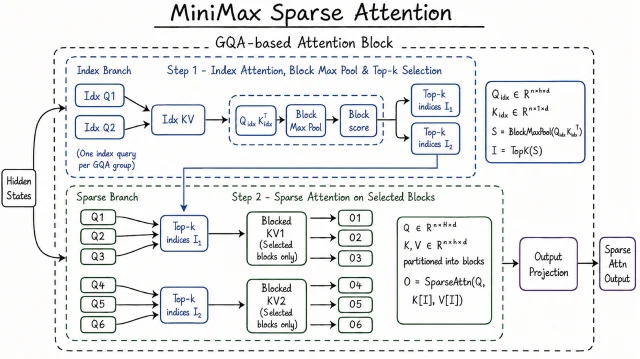
Architecture: 428B total parameters, ~23B activated per token (MoE), 1M token context window. The 1M context is achieved via MiniMax Sparse Attention (MSA) — a blockwise sparse attention mechanism built on Grouped Query Attention (GQA) that scores and selects the top-k KV blocks per GQA group rather than attending to all tokens. The MSA paper (arXiv 2606.13392) reports 9× prefill and 15× decode speedups over the prior generation at 1M context, with per-token compute reduced to 1/20 of M2. 11 The inference kernel is open-sourced at github.com/MiniMax-AI/MSA.
콘텐츠 카드를 불러오는 중…
It's a native Image-Text-to-Text model — multimodal input trained from the ground up, not a post-hoc vision adapter. MiniMax describes it as "the first and only open-weight model to bring all three together" (frontier coding + 1M context + native multimodality). 11
Key published benchmarks: SWE-Bench Pro 59.0%, Terminal-Bench 2.1 66.0%, MCP Atlas 74.2%, KernelBench Hard 28.8%, PostTrainBench 0.37 (vs Opus 4.7: 0.42, GPT-5.5: 0.39). 11 In one autonomous benchmark run, M3 ran for ~24 hours, made 147 benchmark submissions and 1,959 tool calls, and improved a Hopper FP8 CUDA kernel utilization from 7.6% to 71.3% (9.4× speedup) with no human intervention. 11 Community assessments on X/Twitter placed it "around Opus 4.6 level" with one user summarizing: "Minimax-m3 is also Opus class in comparison and it's 1/20 the cost." That 1/20 cost figure refers to the MiniMax API pricing relative to Opus 4.x API pricing — not to self-hosting, which requires ~280GB VRAM for 4-bit quantization. 12
License (read carefully before shipping): MINIMAX COMMUNITY LICENSE — not MIT or Apache. 13 Non-commercial use is fully free. Commercial use under $20M annual revenue requires: prominently displaying "Built with MiniMax M3" on a related website, UI, blog, or about page, AND sending an email to [email protected] with subject "M3 licensing - authorization request." Commercial use over $20M/year requires separate written authorization. MiniMax explicitly framed this as a response to community criticism of M2.7's more restrictive terms: "We listened. ... You told us the license was too restrictive." 14 Some community members flagged that the definition of "Commercial Use" is broad enough that even free-tier product offerings that monetize elsewhere might fall under it — read the full license text before deciding.
Deployment today: SGLang and vLLM same-day support; llama.cpp via PR #24523 (
git fetch origin pull/24523/head:minimax-m3); Unsloth GGUF with 11 quantization variants (IQ1_M through IQ4_XS); Ollama, LM Studio, Jan compatible via Unsloth GGUF. MLX-VLM confirmed working on Mac Studio M3 Ultra with 512GB RAM (one user reported 736 output tokens in ~31 seconds). 15 NVIDIA NIM lists it under non-commercial. MiniMax Token Plan subscription: Plus $20/month (~1.7B tokens), Max $50/month (~5.1B tokens), Ultra $120/month (~9.8B tokens). 11- License: MINIMAX COMMUNITY LICENSE — free non-commercial; free commercial under $20M revenue with attribution + email notification; requires written authorization above $20M
- Active params: ~23B (428B total MoE), 1M context
- Deployment: SGLang, vLLM, llama.cpp (PR #24523), Unsloth GGUF; MiniMax API; local requires ~280GB VRAM for 4-bit
- Builder angle: For the 99% of indie builders under $20M revenue, the license is workable — the attribution requirement (a footer badge or "Built with MiniMax M3" on an about page) is friction but not a blocker. The practical ceiling is hardware: 280GB VRAM for local 4-bit means you're API-dependent unless you have a multi-GPU server. The API subscription model is a strong deal for high-token-volume workloads vs. per-token pricing at comparable capability tiers. Real-world community use cases this week included multimodal form-filling (US customs form from driver's license photo via MLX-VLM) and a GTA-style game generated entirely in-browser — both demonstrate the multimodal pipeline working end-to-end. The 109B consumer-GPU variant hinted at in the MSA paper has not been released; the community is asking for it.
On the radar
Cohere North-Mini-Code-1.0 grew from 4,050 to 11,145 downloads in three days — 2.75x, below the 10x entry bar. Still worth a look: 30B total / 3B active MoE (Apache 2.0), 256K context, SFT + RLVR training, explicitly optimized for agentic software engineering workflows. llama.cpp architecture support landed this weekend (June 14–15) and Unsloth GGUF is available. 16 17 Artificial Analysis Coding Index puts it at 33.4, directly competing with Qwen3 30B-A3B Thinking. If you need a commercially-clean 3B-active coding model and K2.7-Code's 32B-active footprint is too heavy for your target inference budget, this is the next candidate to test.
Trust, but verify
The week's most-downloaded model in the multimodal category isn't on this list — and that's the point.
prefeitura-rio/Rio-3.5-Open-397B accumulated 189,000 HF downloads (as of June 15) while presenting itself as an independently trained 397B model from IplanRIO, the AI division of the Rio de Janeiro municipal government. 18 nex-agi proved it wasn't, using two independent methods: (1) with the hard-coded "You are Rio" system prompt stripped, the model identified itself as "Nex, from Nex-AGI" 79% of the time and as "Rio" 0% of the time; (2) every weight tensor across all 60 layers exactly matches a 0.6/0.4 element-wise blend of Nex-N2-Pro and Qwen3.5-397B-A17B — to, as nex-agi put it, "thousands of standard deviations" of statistical certainty. 18
"Its weights are a direct element-wise merge of our model, Nex, with the official Qwen3.5-397B-A17B base — about 0.6 Nex / 0.4 Qwen — and we find no evidence of any training of their own." 18 The HN discussion thread on the exposé received 250 upvotes. The model remains live on HF as of June 15 with its download count continuing to grow — controversy drives curiosity downloads.
The practical lesson: download counts on HF are not quality signals. Organizations you've never seen before, with implausible training claims for very large models, warrant a quick weight-analysis check before you build anything on top of them.
The week's shape
Four models cleared the >10x bar, with the license story doing most of the work: Kimi-K2.7-Code and DiffusionGemma ship Apache 2.0 or Modified MIT, meaning you can deploy both commercially without a contract conversation. MiniMax M3 is the capability leader of the week but comes with attribution strings for commercial builders. Nex-N2-mini sits in a license grey zone until you trace the Qwen3.5 inheritance. The Rio-3.5 fraud is a one-off incident, not a systemic HF problem — but it confirms that download velocity for an unknown org's flagship model deserves a second look before you integrate.
Cover image: MiniMax M3 official hero image from the MiniMax M3 blog post, MiniMax official media.
참고 출처
- 1moonshotai/Kimi-K2.7-Code · Hugging Face
- 2Kimi K2.7-Code Developer Guide — Developers Digest
- 3r/LocalLLaMA: moonshotai/Kimi-K2.7-Code · Hugging Face
- 4Introducing DiffusionGemma — Google DeepMind Blog
- 5google/diffusiongemma-26B-A4B-it · Hugging Face
- 6Diffusion Gemma is 4× faster, but makes 6× more mistakes! — r/LocalLLaMA
- 7Can we stop dunking on DiffusionGemma and hack it — r/LocalLLaMA
- 8unsloth/diffusiongemma-26B-A4B-it-GGUF · Hugging Face
- 9nex-agi/Nex-N2-mini · Hugging Face
- 10nex-agi/Nex-N2-Pro · Hugging Face
- 11MiniMax M3: Frontier Coding, 1M Context, Native Multimodality
- 12r/LocalLLaMA: MiniMaxAI/MiniMax-M3 · Hugging Face
- 13LICENSE · MiniMaxAI/MiniMax-M3 at main
- 14MiniMax AI on X: On the M3 license
- 15MiniMax M3 - How to Run Locally
- 16CohereLabs/North-Mini-Code-1.0 · Hugging Face
- 17Command A Plus GGUFs posted — r/LocalLLaMA
- 18nex-agi/Nex-N2: Rio-3.5-Open-397B ≈ 0.6 × Nex-N2-Pro + 0.4 × Qwen — Issue #4
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.