
Eve ships, A2A grows up, and agent ops moves from demos to control planes
Today's briefing tracks the production layer forming around AI agents: Vercel releases Eve, Google pushes A2A handoffs, Strands and Cloudflare focus on sandboxing and evaluation, MCP's July migration starts to matter, and AA-Briefcase raises the bar for knowledge-work benchmarks.

리서치 브리프
Vercel's Eve release is the clearest sign this week that agent builders are moving past demo loops and into application platforms. The supporting signals point the same way: Google is trying to normalize peer-to-peer agent handoffs, the MCP community is breaking session assumptions before the July spec cutoff, Strands and Cloudflare are shipping containment and test harnesses, and Artificial Analysis is grading agents on multi-week office work rather than toy tasks.
Coverage window: June 17-18, 2026, with priority on items not covered in yesterday's issue.
The short version
| Signal | What changed | Why builders should care |
|---|---|---|
| Vercel released Eve, an open-source filesystem-first agent framework. | Eve packages durable execution, sandboxed compute, human approvals, subagents, evals, channels, schedules, tracing, and deployment as a conventional project tree; the public repo shows 1.4k stars and a June 18 latest release, [email protected] 1. | Agent frameworks are starting to look like web frameworks: directory conventions, local dev, CI, deploys, rollbacks, and observability rather than bespoke loops. |
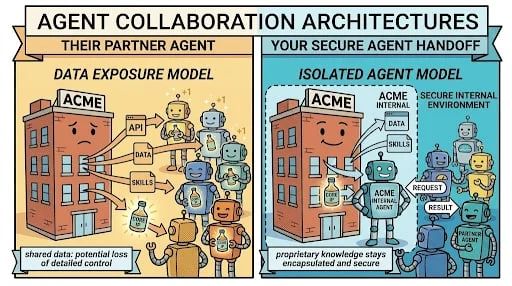
| Google published a one-year A2A update. | Google says the Agent-to-Agent protocol now supports production handoffs such as FoldRun, a life-sciences agentic interface that can be called from Gemini Enterprise, Gemini CLI, or any A2A-compliant environment 2. | The useful unit is shifting from one giant agent to networks of specialized agents that keep proprietary state and logic behind a secure boundary. |
| Strands shipped cost, sandbox, and eval upgrades. | Strands says context_manager="auto" cut costs 55% and raised accuracy from 68% to 98% on its real code-investigation benchmarks; it also introduced Strands Shell and Strands Evals 1.0 with chaos testing and red teaming 3. | Long-running agents need context policy, filesystem isolation, and failure injection as default parts of the stack. |
| MCP's July release candidate is becoming a migration item. | The official MCP 2026-07-28 release candidate removes the initialize handshake and Mcp-Session-Id, adds Mcp-Method and Mcp-Name headers, formalizes extensions, and hardens authorization 4. | Remote MCP servers can move toward stateless HTTP operations, but production users need to audit session assumptions and auth flows before July 28. |
| Artificial Analysis launched AA-Briefcase. | The benchmark covers 91 tasks across four held-out multi-week knowledge-work scenarios and nearly 2,000 source files, including more than 3,500 emails and 25,000 Slack messages 5. | Agent evaluation is moving toward messy, fragmented project work where pretty deliverables can still be wrong. |
| Cloudflare published a vulnerability-discovery harness design. | Cloudflare describes a model-agnostic security pipeline that grew from a 450-line security-audit skill into a harness that scans 128 repos and separates discovery, validation, deduplication, tracing, and reporting 6. | The interesting lesson is orchestration: persist state outside the model, cross-check findings with different models, and treat security agents as pipelines rather than one-shot prompts. |
| Commercial adoption signals are getting more concrete. | Capacity said it crossed $100M ARR, serves more than 20,000 organizations, and has 250+ native integrations in its agentic support automation platform 7. Alibaba.com launched Accio Work for Malaysian SMEs and paired it with a MYR 500,000 CoCreate Pitch competition 8. | The market is not only buying chat surfaces. Vendors are packaging multi-step operations around knowledge layers, sourcing, support, and go-to-market workflows. |
Eve turns the agent into a project directory
Vercel's pitch for Eve is blunt: an agent should be a directory. The example project tree puts model config in
agent.ts, standing instructions in instructions.md, tools in tools/, procedures in skills/, delegated workers in subagents/, surface adapters in channels/, and autonomous triggers in schedules/ 9.That structure matters because it makes agents reviewable. A team can inspect a diff and see that the risky part is a new tool, a broadened approval rule, a looser instruction, or a new scheduled job. Eve also treats a conversation as a durable workflow, checkpoints each step, lets a session pause through deploys, and runs agent-generated code in a separate sandbox backed by Vercel Sandbox in production or Docker/microsandbox locally 9.
콘텐츠 카드를 불러오는 중…
The stronger claim is that Vercel is already running the company this way. Vercel says it runs more than 100 production agents on Eve, that its internal
d0 data analyst handles more than 30,000 Slack questions per month, that a lead-agent workflow costs about $5,000 per year and returns 32x that, and that its Vertex support agent resolves 92% of tickets before escalating the rest 9. Treat those as vendor-reported numbers, but the operating pattern is useful: agent platforms are starting to standardize permissions, traces, evals, channels, and deployment in one place.Strands is attacking the same production problem from a different direction. Its new default context manager offloads large tool results to external storage, compresses old messages into structured summaries, and triggers proactive compression at 85% context usage 3. Strands Shell gives agents a virtual filesystem with bound paths, private-network blocking by default, explicit internal-host allowlists, and per-URL credential injection so the model never holds raw secrets 3.
The builder takeaway is not Eve versus Strands. It is that the framework checklist is converging: durable state, sandboxed execution, approval gates, tool auth, tracing, evals, and CI hooks. If a framework cannot tell you where each of those lives, it is still a demo harness.
A2A and MCP are dividing the protocol layer
Google's A2A update explains the collaboration side of the stack. The case study is FoldRun: instead of stuffing a primary agent's context with protein-modeling dependencies, a user can delegate structure-prediction work to a specialized agent that manages its own environment and long-running decisions 2. Google also says the official A2A SDKs for Python and Go are 1.0 GA, while Java is in beta, .NET is in preview, and JavaScript/TypeScript remains on a stable v0.3 line with 1.0 work in progress 2.
MCP is solving a neighboring problem: how agents call tools and services. The official July release candidate is older than today's news cycle, but WorkOS' June 18 implementation guide is a useful reminder that the deadline is now close enough for migration planning 10.
The protocol change is not cosmetic. The release candidate removes hidden protocol sessions, lets any server instance handle a request, moves capability discovery to
server/discover, makes Mcp-Method and Mcp-Name routable headers, and lifts tool schemas to full JSON Schema 2020-12 4. Authorization also gets stricter: clients must validate issuer responses, bind credentials to the authorization server issuer, use Resource Indicators, and support Protected Resource Metadata discovery 4.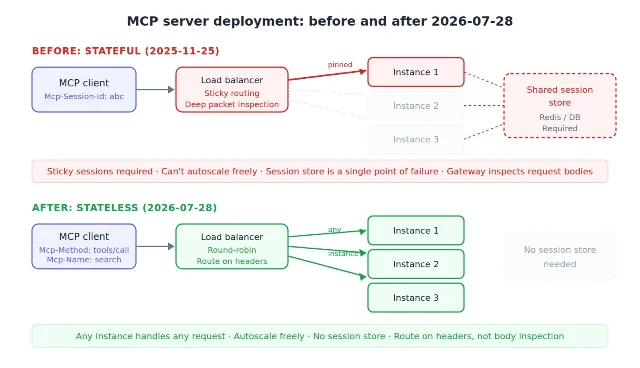
For teams shipping remote tools, the practical checklist is simple: find every dependency on
Mcp-Session-Id, decide which state should become explicit handles, expose protected-resource metadata, and test multi-instance deployment behind ordinary load balancing. The spec is trying to make MCP easier to operate, but the migration will surface any server that hid application state inside transport state.Evaluation is getting less forgiving
AA-Briefcase is useful because it moves agent evaluation closer to the kind of work founders and operators actually want to delegate. The benchmark uses multi-week projects in data science, product management, corporate strategy, and banking-branch transformation. Each task is graded with binary rubric checks plus pairwise judgments for analytical quality and presentation 5.
The headline results are sobering. Artificial Analysis says Claude Fable 5 leads the combined AA-Briefcase Elo, followed by Claude Opus 4.8 (max), GLM-5.2 (max), and GPT-5.5 (xhigh). But Claude Fable 5 satisfies all criteria correctly on only 3% of tasks, and on 31 of 91 tasks no model scores above 50% 5. Cost also varies sharply: Claude Fable 5 costs more than $31 per task on average, while DeepSeek V4 Flash (Max) is around $0.04 per task, and GLM-5.2 (max) is described as a strong open-weight price/performance option 5.
One detail is especially relevant for agent builders: the leading presentation models visually inspect rendered outputs far more often. Claude Fable 5 averages 21 visual inspections per task, Claude Opus 4.8 (max) averages 12, while weaker presentation models inspect much less 5. That supports a pattern we see in real builds: agents that create documents, dashboards, spreadsheets, or UI need a review loop that sees the artifact, not just the text trace.
Cloudflare's vulnerability harness shows the same lesson from the security side. The company argues that generic coding agents only hold one hypothesis at a time, lose coverage as context fills, and need a persistent harness for repo-scale security work 6. Its design splits work into recon, hunt, validate, gapfill, dedup, trace, feedback, and report stages, writes state to SQLite by run/repo/stage, and uses a separate validation model to stress-test findings from the discovery model 6.
The important part is not that Cloudflare built a security scanner. It is that high-stakes agent work is becoming multi-stage software. Agents propose; separate systems persist, replay, validate, deduplicate, and decide what advances.
The market signal: packaged work beats another chatbot
Two commercial releases round out the day. Capacity's $100M ARR announcement is a press release, but it gives a concrete shape to one category of agentic revenue: unified support automation across chat, email, SMS, voice, agent assist, post-interaction QA, and outbound campaigns, all drawing on one knowledge orchestration layer 7.
Alibaba.com's Accio Work points at a different packaged workflow. The product is positioned as an agentic business team for Malaysian SMEs, covering market research, product planning, sourcing, product listing, global marketing, and store management. The same launch tied Accio Work to a MYR 500,000 Malaysia startup competition with registration open until August 25, 2026 8.
These are vendor claims, not independent adoption studies. Still, both are worth tracking because they package agents around operational workflows rather than around a blank chat box. The buyer does not want an agent. The buyer wants support deflection, lead follow-up, sourcing, listing, compliance, or reporting to happen with fewer handoffs.
Builder notes for today
- If you are choosing an agent framework, ask where durable state, sandbox policy, tool auth, approvals, traces, evals, and deploy rollback live. Eve and Strands are setting the comparison bar.
- If you run MCP servers, treat the July 28 spec as a breaking-change migration, not as a documentation update. Session state and token audience rules are the risk areas.
- If you evaluate agents, add artifact-level review. AA-Briefcase's visual-inspection result is a reminder that text-only traces miss failures in the final deliverable.
- If you are selling agentic software, package the workflow. The market evidence today favors systems that complete support, commerce, analytics, or security tasks over generic agents that need the customer to invent the process.
The throughline is control. The stack is no longer asking whether agents can call tools. It is asking who owns state, who can approve action, how failures are reproduced, how credentials are scoped, and which part of the system gets to say the work is done.
참고 출처
- 1Vercel Eve GitHub repo
- 2Google Developers Blog: How A2A is Building a World of Collaborative Agents
- 3Strands Agents: Reduced cost, better isolation, and more resilience
- 4Model Context Protocol: 2026-07-28 release candidate
- 5Artificial Analysis: Announcing AA-Briefcase
- 6Cloudflare: Build your own vulnerability harness
- 7Capacity PR Newswire release
- 8Alibaba.com PR Newswire release
- 9Vercel: Introducing Eve
- 10WorkOS: MCP 2026 spec update for agent authentication
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.