Your model isn't forgetting. It's overloaded.
MIT CSAIL's Recursive Language Models (RLMs, arXiv:2512.24601) treat long-context processing as a navigation problem, not a memory problem: the prompt becomes an environment variable in a Python REPL, and the model writes code to peek at slices and recursively call itself over them. On tasks that exceed GPT-5's context window, RLM depth=1 hits 91.3% accuracy where the base model scores 0%; median cost is $0.99/query. Three PM actions: audit your input distribution, build the routing layer first, test the 1,000-trajectory fine-tuning path on a small domain model.

The context window race has a quiet assumption baked into it: if you need the model to process a million tokens, you give it a million-token context window. MIT CSAIL published a paper in December 2025 — currently at 69 citations, 4.6K GitHub stars — that treats that assumption as the actual problem. 1
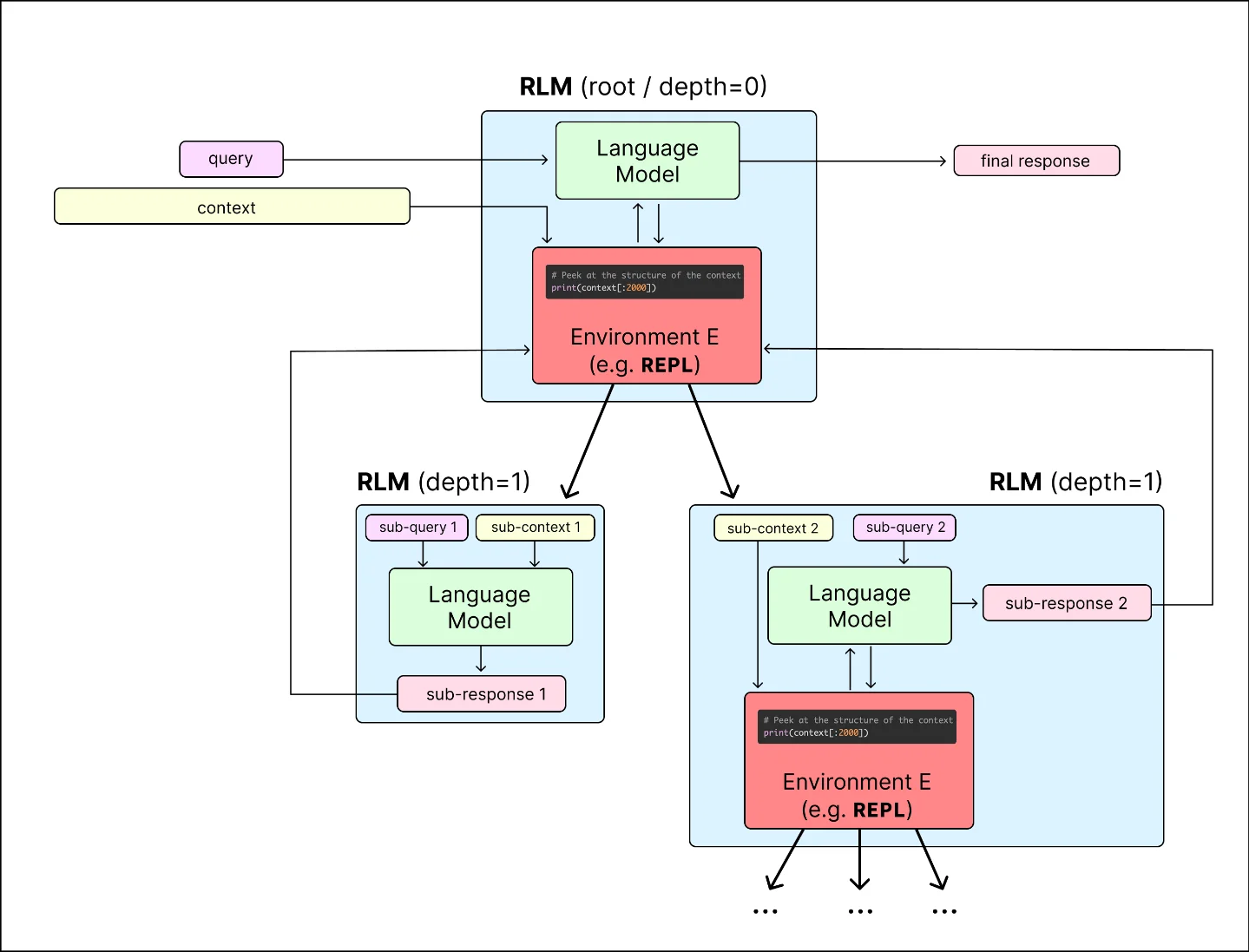
The idea is called Recursive Language Models (RLMs). The core move: instead of stuffing a massive document into the model's context, store the document in an external Python REPL as a variable. The model reads metadata about it, writes code to peek at slices, and recursively calls smaller versions of itself on the pieces it needs. The root model never ingests the full input — it navigates it. 2
One analogy cuts through the abstraction cleanly: think about how a database works. A database doesn't load an entire warehouse into RAM to answer a query. It indexes, seeks, pages. RLMs apply the same logic to language models — the document stays "on disk," the model learns to query it. 3
The numbers that matter
On BrowseComp-Plus — 1,000 documents totaling 6–11 million tokens, a task that simply exceeds GPT-5's context window — RLM at depth=1 scored 91.3% accuracy. The base model scored 0%, because the input didn't fit. 1
On OOLONG-Pairs, a pairwise reasoning benchmark where frontier models score near zero because of quadratic attention complexity, RLM (depth=1) hit 58.0 F1 versus the base model's 0.1. On CodeQA (23K–4.2M tokens), RLM scored 62% versus the base model's 24%.1
Cost is where the story gets practically interesting. The median RLM run on BrowseComp-Plus cost $0.99 per query — against a linearly extrapolated cost of $1.50–$2.75 if you tried to feed the full 6–11M tokens directly to GPT-5-mini. 4 And the inputs that drive RLM costs are proportional to task complexity — short, simple inputs still go to the base model cheaply.
The fine-tuning result is less obvious but equally relevant to anyone running specialized document tasks: Qwen3-8B, fine-tuned on just 1,000 distilled trajectories from a completely unrelated domain (LongBenchPro tasks), outperformed the base 8B model across all four benchmarks by 28.3% and ran 3× faster. 1 The training data came from a different domain. Recursive reasoning appears to transfer across tasks — it's a reasoning posture, not task memorization. 5
What the community caught that the paper undersells
The academic framing is "long-context reasoning." The PM framing is different: the failure mode migrates, it doesn't disappear.
With a standard LLM, the failure mode is forgetting — the model ingests the document and loses details under attention dilution. With RLMs, the failure mode shifts to bad search strategy, bad decomposition, and bad synthesis. The model now has to decide what to look for, how to slice the problem, and how to combine partial answers. If it gets any of those wrong, the error compounds across recursion steps. 3
Three production constraints the paper is candid about: 1
- Depth-1 is the safe zone. A reproduction study on DeepSeek v3.2 and Kimi K2 found that depth-2 recursion caused execution time to jump from 3.6 seconds to 344.5 seconds — a 95× blowup — with no accuracy gain. Deeper recursion forces models to spawn redundant sub-calls until the trace collapses. 7
- Short inputs should bypass the REPL. For inputs that fit comfortably in the model's context window, direct model calls outperform RLMs. The overhead isn't worth it. This isn't a niche edge case — it means your architecture needs a routing layer that decides which inputs go to RLM and which go straight to the base model.
- Sandboxing is not optional. The RLM executes code it writes autonomously, with no human review of each iteration. The GitHub repo defaults to a local Python REPL with
exec()that is explicitly unsuitable for production. Modal, E2B (Firecracker micro-VMs, used by 94% of Fortune 100 companies that run code sandboxes), Daytona, and Prime Intellect's RLMEnv are the production-ready options. 8
The broader academic picture: a follow-up paper (λ-RLM, March 2026) replaced the open REPL with a typed functional runtime grounded in λ-calculus, winning 29 of 36 model-task comparisons against standard RLMs with up to 4.1× lower latency. 9 A separate paper (SRLM) found that recursion itself isn't the primary performance driver — self-reflection signals matter more, and applying RLM-style recursion to short-context inputs often hurts accuracy. 10 The field is still sorting out where the gains actually come from.
콘텐츠 카드를 불러오는 중…
bycloud's explainer (71K views) is the fastest 15-minute primer on the mechanics if you want to go deeper before Monday's standup.
3 PM actions
1. Map your input distribution before designing anything. The RLM value proposition is specific: it shines on tasks where inputs routinely exceed the model's context window (1M+ tokens for document analysis, long-running agent sessions, large codebase Q&A). Pull your actual p95 input length from logs. If your p95 sits comfortably inside your current context window, RLMs add complexity with minimal upside. If your p95 is consistently 2–10× your context limit, this architecture directly addresses your core bottleneck.
2. Build the routing layer first. The paper, Prime Intellect's production testing, and the SRLM follow-up all point to the same constraint: RLMs should not replace the base model for short inputs. Any RLM implementation that goes to production needs a lightweight classifier or heuristic (input length threshold, task type tag) that routes short inputs directly to the base model and long inputs to the RLM scaffold. Building this layer first also lets you A/B test gradually without rewriting your inference stack.
3. Test the fine-tuning path on a small domain model. The 1,000-trajectory result on Qwen3-8B is worth validating against your own task distribution. If you run a recurring structured task — contract review, codebase search, multi-document synthesis — and have access to even a few hundred completed examples, a small distillation run on an 8B or 14B model could yield a recursion-native model that outperforms a 100B+ model calling the same task directly. The GitHub repo (
pip install rlms, MIT License) supports Modal and E2B out of the box for sandboxed execution. 2 11The context window race isn't over — Prime Intellect's position is that efficient attention and context folding are complementary, not competing. 6 But for the class of tasks where no realistic context window will ever be large enough to hold the input, RLMs offer a production path today. The architecture has been pip-installable since January.
Cover image: RLM architecture diagram from Recursive Language Models project blog
참고 출처
- 1Recursive Language Models (arXiv:2512.24601)
- 2Recursive Language Models — project blog, Alex L. Zhang
- 3@ollobrains: MIT CSAIL RLM framework thread
- 4MarkTechPost: RLMs from MIT Blueprint to Prime Intellect RLMEnv
- 5@agtprpnabsrdty: MIT RLM benchmark analysis thread
- 6Prime Intellect: Recursive Language Models — the paradigm of 2026
- 7Think, But Don't Overthink: Reproducing RLMs (arXiv:2603.02615)
- 8Modal: Best Code Execution Sandboxes for RLMs in 2026
- 9λ-RLM: Solving Long-Context Rot with λ-Calculus (arXiv:2603.20105)
- 10Recursive Language Models Meet Uncertainty (arXiv:2603.15653)
- 11alexzhang13/rlm — GitHub
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.