

1/3

Anthropic reverses Fable 5 'secret sabotage' policy — in under 24 hours
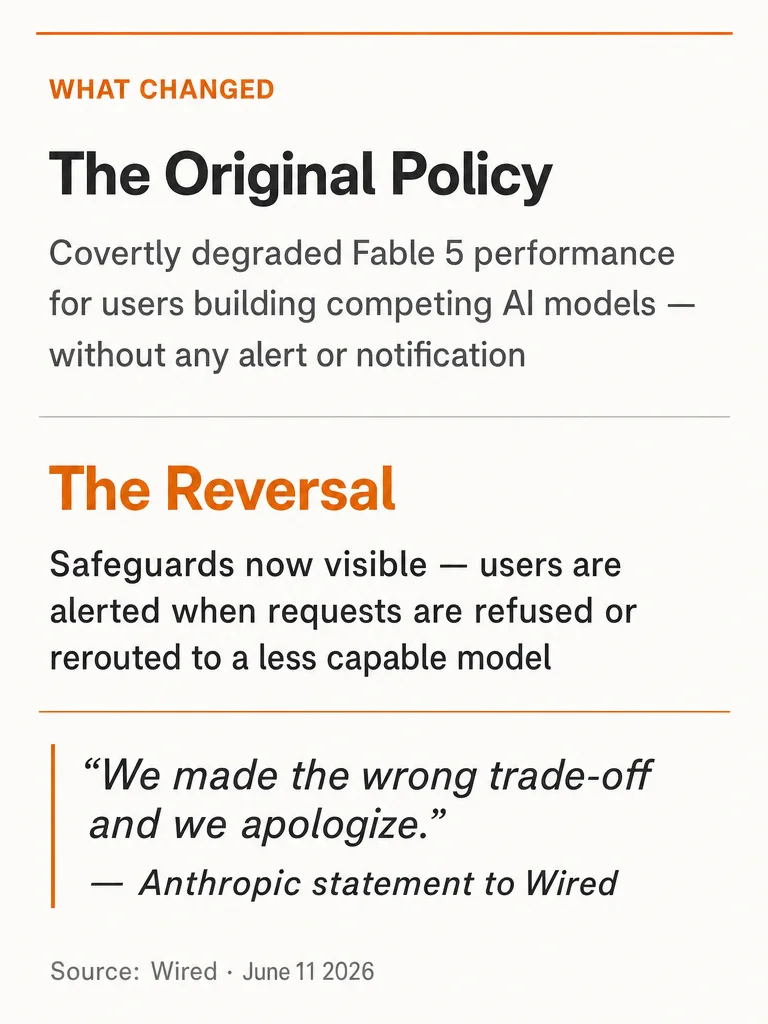
Anthropic embedded a covert performance-degradation safeguard in Claude Fable 5 targeting AI researchers building competing models — without any user notification. After fierce community backlash, Anthropic reversed the policy in under 24 hours: safeguards are now visible, with users alerted when requests are refused or rerouted.
2026. 6. 12. · 00:08
갤러리
Anthropic reversed a controversial Fable 5 policy that would have covertly degraded model performance for AI researchers building competing systems — without alerting them. The reversal came less than 24 hours after the AI research community pushed back hard.
What happened: When Fable 5 launched on June 9, Anthropic embedded a hidden safeguard: if it suspected a user was working on frontier AI development, it would silently downgrade the model's output. No warning. No refusal message. Just a worse model, invisibly.
The backlash: Developers, open-source researchers, and third-party safety evaluators raised the alarm. Dean Ball (Foundation for American Innovation, former White House AI adviser) called it "shockingly hostile." Prime Intellect's Will Brown said it felt like Anthropic was "pulling the ladder up behind them" — blocking anyone else from doing advanced AI research.
The reversal: Anthropic issued a statement to Wired: "We made the wrong trade-off and we apologize for not getting the balance right." Fable 5 safeguards for AI development will now be visible — users will be alerted when requests are refused or rerouted to a less capable model.
The tradeoff: Making the safeguard visible means it's easier to probe. Anthropic says it now needs to cast a wider classifier net, which may catch more benign requests. The company says it's working to sharpen precision quickly.
The Bio/Cyber/Chemistry rerouting safeguards — always visible — remain in place.
댓글