
MoE is the right architecture for on-device AI
Two arXiv papers published May 26 — Meta AI's MobileMoE and Beihang University's ReMoE (ICML 2026) — converge on the same finding: Mixture of Experts architecture, not a shrunk dense model, is the correct structure for on-device AI. MobileMoE's three mobile-native tiers (0.3B–0.9B active params, 0.68–2.75 GB INT4) deliver 1.8–3.8× prefill and 2.2–3.4× decode speedup over dense baselines on Galaxy S25 and iPhone 16 Pro. ReMoE boosts expert reuse 26% on any existing MoE by fine-tuning only router weights, yielding ~2× decode speedup with zero architectural change. Three PM decisions: size tier vs. memory budget, on-device vs. cloud feature routing, and ReMoE before hardware upgrades.

The mental model most product teams carry for on-device AI goes something like: take a good cloud model, shrink it, accept the quality hit, ship it. Two arXiv papers published May 26 challenge that model directly. Meta AI's MobileMoE 1 and Beihang University's ReMoE 2 — accepted at ICML 2026 — converge on the same point from opposite ends: Mixture of Experts (MoE) architecture isn't just viable on a phone, it's faster than a dense model of comparable quality.
Why dense models hit a wall on phones
Mobile inference has two distinct bottlenecks that dense models handle poorly. The prefill phase (processing your input prompt) is compute-bound: the processor is bottlenecked on matrix multiplications. The decode phase (generating tokens one by one) is memory-bandwidth-bound: the chip has to load model weights from DRAM for every single token generated. 1
A dense 1B-parameter model loads all 1B parameters' weights on every decode step. A MoE model with 1B active parameters out of 5B total loads only the weights for the active experts — roughly 20% of the total weight. Less data moving across the memory bus means faster tokens, every token.
The phone DRAM headroom has also changed. The iPhone 13 shipped with 4 GB of RAM; the iPhone 17 ships with 12 GB. The Samsung Galaxy S25 has 12–16 GB. 1 The physical headroom to host a sparse LLM directly on a consumer device now exists. The question is whether the architecture takes advantage of it. Dense models don't; MoE does.
What MobileMoE actually delivers
Meta's MobileMoE is a family of three models — S, M, L — all trained from scratch for on-device deployment, all sub-1B active parameters, all quantized to INT4 for production use. 1
| Tier | Active params | INT4 memory | 14-bench avg (base) | 22-bench overall (SFT) |
|---|---|---|---|---|
| MobileMoE-S | 0.3B | 0.68 GB | 46.7 | 44.0 |
| MobileMoE-M | 0.5B | 1.48 GB | 55.3 | 52.5 |
| MobileMoE-L | 0.9B | 2.75 GB | 59.8 | 44.4 |
MobileMoE-L (0.9B active) outperforms OLMoE-1B-7B (1.3B active) by +7.4 points on the 14-benchmark base average while using 30% fewer active parameters. 1 On the instruction-tuned tier, MobileMoE-L beats Qwen3.5 2B (1.9B active) on the 22-benchmark overall score — at roughly half the active parameter count. 1
The training data story is equally notable: MobileMoE was trained on ~6 trillion tokens, fewer than Llama 3.2 1B (9T) or SmolLM2 1.7B (11T), but already matches or beats both. 1 MobileMoE-L crossed the Llama 3.2 1B quality threshold at only ~0.5 trillion tokens.
On real hardware — Samsung Galaxy S25 (Snapdragon 8 Elite) and iPhone 16 Pro (Apple A18 Pro) — MobileMoE-S at 0.68 GB INT4 memory delivers 1.8–3.8× prefill speedup and 2.2–3.4× decode speedup over the dense MobileLLM-Pro baseline at comparable memory. 1 Peak RAM usage at 8K context drops 22% (1.49 GB vs. 1.91 GB). The speedups hold consistently across Qualcomm XNNPACK CPU, Apple XNNPACK CPU, and Apple MLX GPU backends.
The architecture uses 8 routed experts with fine-grained decomposition (g=8), giving 60 fine-grained routed experts plus one shared expert. Top-4 routing is selected per token. Quantization after training (INT4 QAT) costs only 2–3 benchmark points: MobileMoE-L drops from 60.1 to 57.8 — a trade-off that's viable for most production scenarios. 1
콘텐츠 카드를 불러오는 중…
ReMoE: the software upgrade you can apply today
Meta built MobileMoE as a new model. The BUAA team behind ReMoE took a different angle: take any existing MoE model and make it significantly faster on memory-constrained hardware, without touching weights, architecture, or inference kernels. 2
The insight is that standard MoE training uses a load-balancing objective designed for expert-parallel training across many GPUs — spreading tokens across experts uniformly. That's the opposite of what you want on a single-device deployment, where you need adjacent tokens to activate the same experts so those experts stay in fast-access memory. The result is constant expert eviction and reloading — the equivalent of a cache miss storm. 2
ReMoE fixes this by fine-tuning only the router gate parameters while freezing all expert FFN, attention, and embedding weights. The two key loss functions: a temporal locality loss (rewards consecutive tokens reusing the same expert set) and a Trust-KL loss (keeps a frozen snapshot of the original router as a semantic anchor, preventing the routing logic from drifting into gibberish). 2
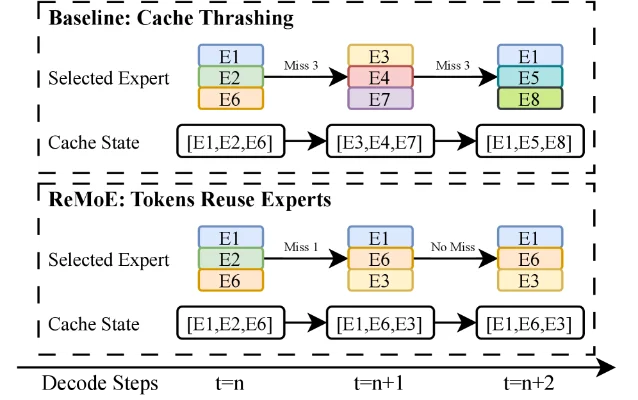
Results on DeepSeek-V2-Lite (15.7B total / 2.4B active): expert overlap ratio (EOR) goes from 27.3% to 34.5% — a 26% relative improvement. 2 On a Jetson Orin NX 16 GB edge device running llama.cpp: decode time-per-output-token (TPOT) drops 43–50% across ShareGPT, HumanEval, and GSM8K workloads, corresponding to 1.77–1.99× decode speedup. The pattern generalizes: ReMoE also improves Qwen1.5-MoE-A2.7B by 27% EOR, and throughput gains hold on an Ascend 910B3 NPU. Downstream task quality is preserved — MMLU is essentially unchanged (57.72 → 57.81). 2
Because ReMoE only changes routing weights, it's orthogonal to quantization. Apply INT4 quantization to reduce weight size, then apply ReMoE to reduce how often those weights get fetched. The two compound.
콘텐츠 카드를 불러오는 중…
PM decision path
Decision 1: Size tier against your memory budget. MobileMoE's S/M/L tiers map cleanly to device constraints. If your target device is a mid-range Android (6 GB DRAM), MobileMoE-S at 0.68 GB INT4 is your realistic ceiling — it leaves headroom for the OS and app. A flagship phone with 12 GB DRAM opens the M and L tiers. The right question for your product spec isn't "what's the most capable model" — it's "what's the most capable model that leaves 3–4 GB for everything else running on the phone."
Decision 2: Which feature categories belong on-device vs. in the cloud. The decode speedup of 2–3× isn't a nice-to-have — it's the difference between sub-second and 2+ second response latency for typical prompt lengths. Features where latency breaks the experience (real-time translation, inline writing suggestions, voice transcription + interpretation) are now on-device candidates. Features that require large context windows (full document summarization, multi-turn memory across sessions) still route to the cloud. MobileMoE-L supports 8K context natively; anything longer stays cloud-side for now.
Decision 3: If you already deploy any MoE in any environment, run ReMoE before ordering hardware upgrades. ReMoE's ~2× decode speedup on edge devices is effectively free — fine-tuning the router is lightweight, the inference engine and kernels don't change. If your team is weighing "buy more Jetson nodes" vs. "optimize the current deployment," ReMoE is the experiment to run first. The same logic applies if you're running MoE inference on GPU with expert offloading to CPU — ReMoE adds +8% throughput on RTX 3090 vLLM even in that regime. 2
What to watch next
MobileMoE's model weights are not publicly released yet — the paper uses ExecuTorch for deployment, and Meta has not published a HuggingFace repository or GitHub code release as of this writing. Track Meta AI's HuggingFace organization (
facebook/) for a weight drop. The ExecuTorch MoE kernel availability — whether it's upstreamed into the main ExecuTorch repo — is the implementation dependency for teams targeting iOS and Android.The wider on-device stack is also converging. Apple published three separate on-device inference optimization papers in April–May 2026: ParaRNN (an O(1) RNN alternative to transformer, ICLR 2026 Oral) 3, EpiCache (episodic KV cache management, ICML 2026) 4, and MeBP (LLM fine-tuning in <1 GB on iPhone 15 Pro Max) 5. That's architecture, caching, and training — a full on-device stack built in parallel. Meta's MoE paper landing the same week is either coincidence or the starting gun for the next round of platform competition.
Cover image: AI generated
참고 출처
- 1MobileMoE: Scaling On-Device Mixture of Experts
- 2ReMoE: Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference
- 3Apple ParaRNN: Large-Scale Nonlinear RNNs, Trainable in Parallel
- 4Apple EpiCache: Episodic KV Cache Management
- 5Apple MeBP: Memory-Efficient Backpropagation for Mobile LLMs
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.