
MiniMax M3 发布:三条科技树同时点满,12小时无人干预复现获奖论文
MiniMax 新旗舰模型 M3 正式发布,同时具备前沿 Coding、百万级上下文(1M tokens)和原生多模态,是目前唯一能三项兼备的开源模型。自研 MSA 稀疏注意力架构让计算量降至上代 1/20,SWE-Bench Pro 得分 59% 超过 GPT-5.5 和 Gemini 3.1 Pro。

리서치 브리프
MiniMax 在 6 月 1 日发布新一代旗舰模型 M3,官方将其定位为「三树同满」:前沿 Coding、百万级上下文(1M tokens)、原生多模态。量子位的报道指出,这是目前唯一能同时做到这三件事的开源模型。1
到底新在哪
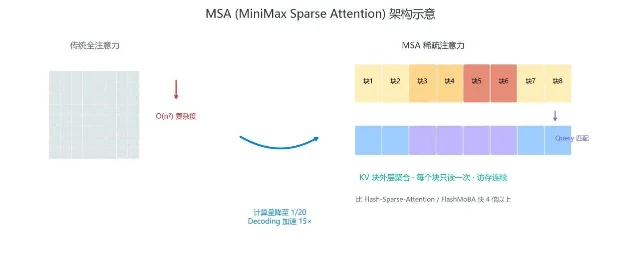
M3 的架构核心是 MSA(MiniMax Sparse Attention),一种自研稀疏注意力机制。稀疏注意力不是新概念,但 MiniMax 这次的实现方式有别:以 KV 块为外层聚合匹配的 query,每个块只读取一次,访存连续——官方称比开源的 Flash-Sparse-Attention 和 FlashMoBA 快 4 倍以上。2
实际效果:在 1M 超长上下文下,每 token 计算量降至上代的 1/20,decode 阶段提速 15 倍以上。按官方描述,效率提升没有导致能力下滑——多个对照实验中,MSA 的结果和全注意力基本持平。
配套的 MiniMax Code 是专为 M3 设计并联合训练的 AI 编程工具,充分利用了 M3 在长上下文和 Agentic 上的特性,订阅分三档:49、119、469 元/月。
怎么验证「会自主干活」
量子位报道中提到两个演示,能说清楚这件事:
12 小时复现 ICLR 获奖论文:M3 全程无人干预,自主迭代需求、改了 18 次代码、画了 23 张图,最终交出复现结果。PostTrainBench 评测的官方得分是 0.37,GPT-5.5 为 0.39、Opus 4.7 为 0.42——差距不大。
24 小时优化 CUDA 内核:M3 连续工作,历经 147 次 benchmark 提交、1959 次工具调用,把 Hopper FP8 的硬件峰值利用率从 7.6% 推到 71.3%,速度提升 9.4 倍。
基准表现
| 基准 | M3 得分 | 对比 |
|---|---|---|
| SWE-Bench Pro | 59.0% | 超 GPT-5.5、Gemini 3.1 Pro,接近 Opus 4.7 |
| Terminal Bench 2.1 | 66.0% | 终端操作能力 |
| SVG-Bench | 超越 Opus 4.7 | SVG 生成综合评估 |
| OmniDocBench | 超 Gemini 3.1 Pro | 多模态文档理解 |
| Claw-Eval | 最高分 | 自主 Agent 端到端评测 |
| BrowseComp | 83.5 | 超 Opus 4.7(79.3) |
编程任务之外,M3 也支持图片/视频输入和 Computer Use(操作电脑桌面)。

与已有产品的差距
智东西的实测给出了相对客观的结论:M3 在 Agentic 任务上理解了真实协作流程,能主动沟通、迭代优化;但任务完成度还有提升空间。多模态任务中,细节描述详尽,地点识别、地铁线路规划等任务与 DeepSeek 识图、Qwen3.7 Max Preview 等相比仍有差距。2
开放时间线
MiniMax 承诺「接下来 10 天内发布技术报告并开源模型权重」;MiniMax Code 也计划开源。API 目前已上线,限时 5 折。港股方面,M3 发布当日,MiniMax(00100.HK)报 717.00 港元,市值约 2248.77 亿港元——公司同期正在推进 A 股科创板 IPO 辅导。
原文来源:量子位 QbitAI,作者克雷西,2026 年 6 月 1 日。
콘텐츠 카드를 불러오는 중…
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.