openai.github.io

OpenAI Agents SDK #33:AgentHooks vs RunHooks——两层生命周期钩子,精准插入 Agent 执行的每个关键节点
SDK 的生命周期钩子系统分两层:RunHooks 全局监听整个运行,AgentHooks 精确绑定到某个 Agent 实例。七个异步钩子方法覆盖 LLM 调用、工具执行、handoff 等所有关键节点,配合 ToolContext 可拿到工具调用的完整元数据(call_id、参数、返回值),是做成本审计、链路日志和行为定制的核心抓手。

리서치 브리프
你有没有想知道某次 Agent 运行到底调了几次 LLM、每个工具花了多少时间、handoff 前后的状态是什么?
SDK 提供了一套**生命周期钩子(Lifecycle Hooks)**系统,让你在不修改 Agent 主逻辑的前提下,在每个关键节点插入自定义代码。
两层钩子的差别,先说清楚
RunHooks:挂在
Runner.run() 调用上,监听这次运行里所有 Agent 的所有事件。适合做全局审计日志、成本统计、全链路追踪。AgentHooks:挂在某个
Agent 实例的 hooks 属性上,只监听这一个 Agent 触发的事件。适合给某个特定 Agent 加行为约束、做针对性调试。两者的方法签名高度相似,但覆盖范围不同:
| 事件 | RunHooks | AgentHooks | 触发时机 |
|---|---|---|---|
on_agent_start / on_start | ✅ | ✅ | 当前 Agent 开始执行时(每次切换 Agent 都触发) |
on_agent_end / on_end | ✅ | ✅ | Agent 产出最终输出时 |
on_handoff | ✅ | ✅ | 发生 handoff 时(RunHooks 看 from→to,AgentHooks 看 source→self) |
on_tool_start | ✅ | ✅ | 某个本地工具被调用前 |
on_tool_end | ✅ | ✅ | 某个本地工具返回后 |
on_llm_start | ✅ | ✅ | LLM 调用发起前(可拿到 system_prompt 和 input_items) |
on_llm_end | ✅ | ✅ | LLM 返回后(可拿到完整 ModelResponse) |
七个钩子方法,全部是
async,不阻塞主流程(只要你别在里面写同步阻塞代码)。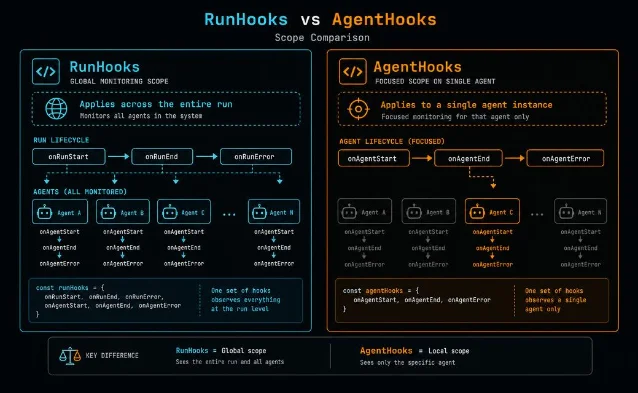
RunHooks:全局监听
from agents import Agent, Runner, RunHooks, RunContextWrapper, Tool
from agents.models import ModelResponse
class MyRunHooks(RunHooks):
async def on_agent_start(self, context, agent, **kwargs):
print(f"[RunHook] Agent 启动: {agent.name}")
async def on_agent_end(self, context, agent, output, **kwargs):
print(f"[RunHook] Agent 结束: {agent.name},输出: {output!r}")
async def on_tool_start(self, context, agent, tool: Tool, **kwargs):
print(f"[RunHook] 工具调用: {tool.name}")
async def on_tool_end(self, context, agent, tool: Tool, result: str, **kwargs):
print(f"[RunHook] 工具返回: {tool.name} → {result[:50]}")
async def on_llm_start(self, context, agent, system_prompt, input_items, **kwargs):
print(f"[RunHook] LLM 调用,输入 {len(input_items)} 条")
async def on_llm_end(self, context, agent, response: ModelResponse, **kwargs):
usage = getattr(response, "usage", None)
if usage:
print(f"[RunHook] LLM 返回,token: {usage}")
async def on_handoff(self, context, from_agent, to_agent, **kwargs):
print(f"[RunHook] Handoff: {from_agent.name} → {to_agent.name}")
result = await Runner.run(
agent,
"帮我查一下今天的天气",
hooks=MyRunHooks(),
)hooks=MyRunHooks() 直接传给 Runner.run(),不需要修改 Agent 定义。只要子类化 RunHooks 并 override 你关心的方法就行——其他方法有默认的空实现,不用全部实现。AgentHooks:精准到某个 Agent
AgentHooks 挂在 agent.hooks 属性上,只对这个 Agent 生效:from agents import Agent, AgentHooks, AgentHookContext
class SpecialistHooks(AgentHooks):
async def on_start(self, context: AgentHookContext, agent, **kwargs):
print(f"[AgentHook] {agent.name} 被激活")
async def on_end(self, context: AgentHookContext, agent, output, **kwargs):
print(f"[AgentHook] {agent.name} 完成,输出长度: {len(str(output))}")
async def on_handoff(self, context, agent, source, **kwargs):
# source 是把控制权交给 self 的那个 Agent
print(f"[AgentHook] 从 {source.name} 转入 {agent.name}")
async def on_tool_start(self, context, agent, tool, **kwargs):
print(f"[AgentHook] {agent.name} 调用工具: {tool.name}")
specialist_agent = Agent(
name="Specialist",
instructions="你是一个专业分析师",
hooks=SpecialistHooks(), # 绑定到这个 Agent
)注意
AgentHooks 里的 on_handoff 参数是 source(谁传来的),而 RunHooks 里是 from_agent(从哪里转出去的)。两者视角相反。on_llm_start / on_llm_end:能做什么
这两个钩子是成本审计的关键入口:
import time
class CostTracker(RunHooks):
def __init__(self):
self._llm_start_times: dict[str, float] = {}
self.total_input_tokens = 0
self.total_output_tokens = 0
async def on_llm_start(self, context, agent, system_prompt, input_items, **kwargs):
self._llm_start_times[agent.name] = time.time()
print(f" → LLM 输入 items: {len(input_items)}")
async def on_llm_end(self, context, agent, response: ModelResponse, **kwargs):
elapsed = time.time() - self._llm_start_times.get(agent.name, 0)
usage = getattr(response, "usage", None)
if usage:
in_tok = getattr(usage, "input_tokens", 0)
out_tok = getattr(usage, "output_tokens", 0)
self.total_input_tokens += in_tok
self.total_output_tokens += out_tok
print(f" ← LLM 返回: {in_tok} in / {out_tok} out,耗时 {elapsed:.2f}s")
tracker = CostTracker()
result = await Runner.run(agent, "分析这份报告", hooks=tracker)
print(f"总 token: {tracker.total_input_tokens} in / {tracker.total_output_tokens} out")on_llm_start 能拿到 system_prompt 和 input_items,这意味着你可以在 LLM 调用前做 token 预估,或者记录下每次调用时的完整上下文。on_llm_end 能拿到 ModelResponse,包含 usage 信息和完整的 output items。ToolContext:工具钩子里隐藏的调用元数据
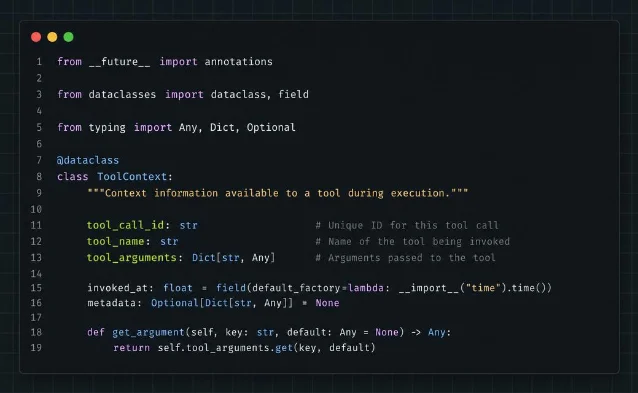
文档里有一个容易被忽略的细节:
on_tool_start 和 on_tool_end 的 context 参数,对于 function tool 来说通常是 ToolContext 实例,而不是普通的 RunContextWrapper。ToolContext 额外暴露了三个字段:tool_call_id:本次工具调用的唯一 IDtool_name:工具名称tool_arguments:工具被调用时的原始参数(字典)
from agents import RunContextWrapper
from agents.run_context import ToolContext # ToolContext 是 RunContextWrapper 的子类
async def on_tool_start(self, context: RunContextWrapper, agent, tool, **kwargs):
if isinstance(context, ToolContext):
print(f" 工具: {context.tool_name}")
print(f" 参数: {context.tool_arguments}")
print(f" call_id: {context.tool_call_id}")这在你需要做工具调用审计(比如记录某个工具的入参出参完整对)时非常有用。
两层叠加使用
RunHooks 和 AgentHooks 可以同时生效,互不干扰:# 全局层:记录所有 Agent 的 LLM 调用
global_hooks = CostTracker()
# Agent 层:只监听 specialist_agent 的工具调用
specialist_agent = Agent(
name="Specialist",
hooks=SpecialistHooks(),
)
result = await Runner.run(
orchestrator_agent,
"执行任务",
hooks=global_hooks, # 全局钩子
)同一个事件(比如
specialist_agent 调用工具),RunHooks.on_tool_start 和 AgentHooks.on_tool_start 都会被触发,顺序是先 RunHooks 后 AgentHooks(根据 SDK 内部实现顺序)。实际用法:四个场景
场景一:全链路延迟拆解
用
on_llm_start/on_llm_end 和 on_tool_start/on_tool_end 各打一个时间戳,就能算出每次 LLM 调用和工具调用各占多少时间,快速定位延迟瓶颈。场景二:handoff 路径日志
on_handoff 记录 from_agent.name → to_agent.name,加上时间戳,就是一条清晰的 Agent 转发链路日志,比翻 trace 直观。场景三:敏感参数脱敏
on_tool_start 里检查 ToolContext.tool_arguments,把敏感字段(如 API key、密码)在入参里打码后再记日志,防止明文泄露到日志系统。场景四:速率限制熔断
在
on_llm_end 里累计 token 计数,超过阈值时抛异常或设置一个 flag,让后续调用提前中止。与 RunConfig.error_handlers 配合可以做到优雅降级。三条实践建议
1. 钩子里不要做阻塞 I/O
所有钩子都是
async,但如果里面用了同步的文件写入或数据库操作,会阻塞事件循环。用 asyncio.get_event_loop().run_in_executor() 或 aiofiles / 异步数据库客户端。2. 异常不要让它悄悄吞掉
SDK 默认不会因为钩子里的异常中止整个 Agent 运行。如果你的监控钩子出错,你不会知道。建议在钩子里加
try/except 并显式记录错误:async def on_tool_end(self, context, agent, tool, result, **kwargs):
try:
await self.record_to_db(tool.name, result)
except Exception as e:
logger.error(f"钩子写库失败: {e}")3. RunHooks 做基础设施,AgentHooks 做业务定制
一套全局
RunHooks 做 token 计数 + 耗时审计 + 链路日志,是基础设施层。需要对某个 Agent 加特殊约束(比如工具调用白名单检查、输出格式校验)时,用 AgentHooks 绑到具体 Agent 上。两层各司其职,比把所有逻辑都塞进 RunHooks 再用 if agent.name == '...' 过滤要清晰得多。링크 미리보기를 불러오는 중…
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.