
Microsoft Build, NVIDIA's Open Monster, and JetBrains' Fast Tiny Model — AI Digest for June 8, 2026
This issue covers Microsoft Build 2026's new reasoning model and GitHub Copilot agent app, NVIDIA's open 550B Nemotron 3 Ultra model with 5x faster inference, JetBrains' Mellum2 open-source lightweight model for AI workflows, Meta's continued delays on Llama 4 Behemoth, and the GitHub Copilot billing shift.

This week was unusually dense. Microsoft held its annual Build conference and shipped a new reasoning model, an image model, and a completely revamped GitHub Copilot desktop app. NVIDIA quietly released what may be the most capable open-weight model available right now. JetBrains open-sourced a small, fast model designed specifically for the kind of plumbing work developers actually need. And Meta's flagship model is still sitting on the shelf. Here's what happened and what it means if you build things.
Microsoft Build 2026: agents, tools, and a new reasoning model
Microsoft used Build to announce a wave of products across its AI stack — enough that it's worth pulling out the pieces most relevant to developers.
MAI-Thinking-1 is Microsoft's first reasoning model, trained from scratch on commercially licensed data. It has 35 billion active parameters, a 256K context window, and is currently in private preview on Azure Foundry. Microsoft claims it outperforms Claude Sonnet 4.6 in blind evaluations and matches Opus 4.6 on SWE Bench Pro for coding tasks.1 That's a notable bar if the numbers hold up under independent testing, though they haven't been replicated yet.
MAI-Code-1, a lighter coding-focused variant, is already live in GitHub Copilot and VS Code. It's built for inference efficiency rather than raw capability — useful for the kind of autocomplete and quick refactor work that happens dozens of times per hour in an IDE.
The bigger news for day-to-day developer workflows is the GitHub Copilot app, a new desktop client that puts agent management front and center.2 The key difference from the existing IDE plugin: you can run multiple agents in parallel, each operating in an isolated git worktree, and watch their progress in a shared "Canvas" view alongside the chat window. A new Agent Merge feature handles the CI and review loop — it monitors test results, tracks required reviewers, and can auto-merge when conditions are met. Available now in technical preview for Copilot Pro, Pro+, Business, and Enterprise users.
콘텐츠 카드를 불러오는 중…
Microsoft also shipped a GitHub Copilot SDK supporting Node.js/TypeScript, Python, Go, .NET, Rust, and Java — so teams can build internal tools (code analysis scripts, changelog generators, custom workflow agents) that run on the same runtime as Copilot itself.
One other piece worth flagging for infrastructure-minded builders: Azure HorizonDB, a managed PostgreSQL service that Microsoft claims delivers 3x the throughput of self-hosted PostgreSQL in internal tests, is now in preview. If you're building agent-heavy apps that need fast database reads, it's worth watching.
NVIDIA Nemotron 3 Ultra: the open-weight model built for long-running agents
On June 4, NVIDIA released Nemotron 3 Ultra, a 550-billion-parameter open model — though only 55 billion parameters are active at any given time thanks to its Mixture-of-Experts architecture.3 The design is built around a hybrid Mamba-Transformer layer structure: Mamba layers handle long sequences efficiently, while Transformer layers preserve precise recall from large context windows. Supported context length: 1 million tokens.
The practical claim that stands out: 5x higher throughput compared to other open models in its class, at the same level of interactivity on Blackwell GPUs. On SWE Bench Verified it scores 65–70.4%, and it cuts cost-to-task-completion by 30% on the same benchmark compared to comparable open models. It's not best-in-class on every benchmark — GLM 5.1 beats it on coding (Terminal-Bench 2.0: 64% vs. 54%) and long-horizon planning — but the throughput and cost numbers make it a serious candidate for anything running agent loops.
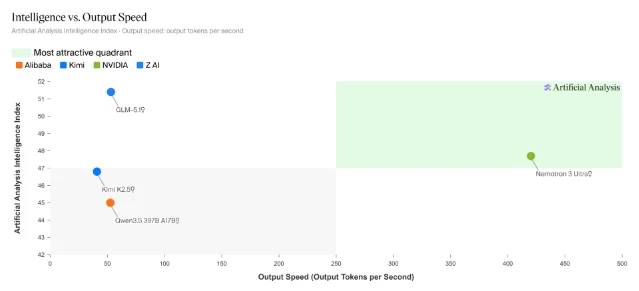
Weights, training data pipeline, and recipes are all released under the permissive OpenMDW-1.1 license. The model is available for download on Hugging Face, and already supported on Ollama cloud, vLLM, SGLang, and TRT-LLM for self-hosting, as well as hosted on Perplexity Pro, OpenRouter, Amazon SageMaker JumpStart, Microsoft Foundry, and Google Cloud.
JetBrains open-sources Mellum2: small, fast, and designed for plumbing
JetBrains released Mellum2 under Apache 2.0 this week — a 12-billion-parameter model with a Mixture-of-Experts design that activates only 2.5 billion parameters per token.4 The pitch is not capability at the frontier, but speed and deployment efficiency: JetBrains says inference time is less than half that of comparable models at the same size.
The intended use cases are the kinds of tasks that sit between the big reasoning calls in an agent pipeline:
- Routing: decide which model or tool should handle a given prompt
- RAG summarization: retrieve context and summarize it quickly before passing to a larger model
- Sub-agent tasks: handle fast, scoped steps in a multi-step workflow without invoking something heavier
It supports local or self-hosted deployment — relevant if you're building on sensitive code or proprietary data. The model is available on Hugging Face at JetBrains/Mellum-2.
콘텐츠 카드를 불러오는 중…
Meta's Llama 4 Behemoth is still delayed
Meta was supposed to launch Llama 4 Behemoth — its largest model — but has held it back citing capability concerns, according to the Wall Street Journal.5 The smaller Llama 4 release earlier this year disappointed some investors, and the delay compounds that.
Separately, Meta launched a model called Muse Spark in April but has repeatedly postponed the developer API that would let people build on it. Zuckerberg has responded to the pressure by spending aggressively: a reported $14 billion acquihire of Scale AI brought CEO Alexandr Wang in as Meta's chief AI officer. The company is also reportedly exploring a Meta cloud computing platform to help offset AI infrastructure costs.
The situation is less about any single model delay and more about the gap between Meta's AI spending pace and what it has shipped publicly so far. The four biggest US tech companies are collectively expected to spend over $720 billion on AI infrastructure in 2026.
One more open-source note: GitHub Copilot billing changed
Starting June 1, GitHub Copilot switched from a flat subscription to metered, token-based billing.6 This isn't a model or tool release, but it affects how developers budget for AI-assisted coding. Heavy Copilot users building agent-heavy workflows should check their usage before the next billing cycle. The flat-rate Free and Student plans remain, but active developer accounts on paid tiers should review the new cost model.
Sources checked as of June 8, 2026. Model benchmarks and availability details are from official release posts — independent replications of benchmark claims had not been published at time of writing.
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.