
Four open-source models, one bottleneck, four different bets
Every major 2026 open-source LLM release attacks the same KV-cache memory constraint — but via four fundamentally different architecture strategies. What each bet means for your inference costs, context window, and hardware stack, plus three PM decisions that follow.

Every major open-source LLM released in the past two months is attacking the same hardware wall. Not benchmark scores. Not parameter counts. KV-cache memory — the part of the inference stack that balloons as context windows grow, and the part that determines whether your model fits on a single GPU at 128K tokens or forces you onto a multi-node cluster.
Sebastian Raschka (Ahead of AI), whose two-article architecture review has become the go-to reference for this wave of releases, put it plainly: "one of the main recent themes in LLM architecture design is KV cache size reduction." 1 The motivation: smaller KV cache means longer contexts without adding GPU memory — which matters more than ever as reasoning agents routinely push past 64K tokens.
What's notable about the current crop isn't just that they're all targeting the same constraint. It's that they've each made fundamentally different architecture bets to get there — bets that cascade directly into your inference cost structure, hardware requirements, and maximum context window.
The four strategies
| Model | Developer | Key innovation | KV-cache approach | Context default |
|---|---|---|---|---|
| Gemma 4 E2B / E4B | Cross-layer KV sharing | Reuse KV tensors from earlier layers; only 15 of 35 layers compute own KV | 128K | |
| ZAYA1-8B | Zyphra | Compressed Convolutional Attention (CCA) | Run attention inside compressed latent space; cuts params, KV, and FLOPs simultaneously | Standard |
| Laguna XS.2 | Poolside | Per-layer query-head budgeting | Vary query heads per layer (8 for cheap sliding-window, 6 for expensive global); KV heads fixed at 8 | Standard |
| DeepSeek V4-Pro | DeepSeek | CSA/HCA + mHC | Compress along sequence dimension (not per-token); 1M context as default | 1M |
Architecture details sourced from Raschka's two-article review 1 2, official release notes 3, and Zyphra's technical report. 4
What each bet actually means
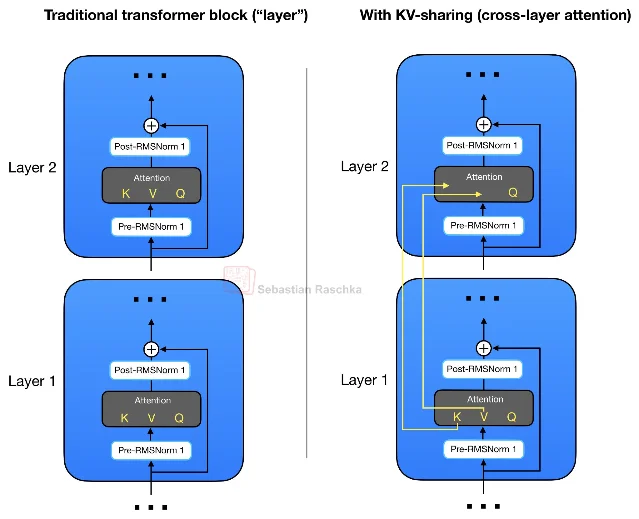
Gemma 4's cross-layer sharing is the most conservative approach. Later layers reuse KV tensors from the nearest non-shared layer of the same attention type — each layer still computes its own query projections, so the approximation cost is limited. The E2B model (2.3B effective parameters) saves roughly 2.7 GB of KV-cache memory at 128K context in bfloat16; the E4B saves ~6 GB. 1 Raschka notes this is "the first popular architecture where I saw this concept applied" in production — the theoretical work (Brandon et al., NeurIPS 2024) predates it by two years. 5 The tradeoff: sharing reduces model capacity. Published research reports minimal performance impact at small scales; production data at larger scales is thinner.
ZAYA1-8B's CCA (Compressed Convolutional Attention) is the most aggressive bet. Rather than keeping the attention mechanism intact and reducing what it stores, CCA moves the entire attention computation into a compressed latent space — projecting Q, K, V down, running convolutional mixing on the compressed Q and K, then attending there. Unlike DeepSeek's Multi-head Latent Attention (MLA), which uses a compressed latent mainly for compact KV storage, CCA actually computes the attention inside the compressed space. 4 Raschka: "ZAYA1-8B is not only trying to save compute in the feed-forward layers, but also in the attention mechanism itself." 1 The CCA paper (Figliolia et al.) claims CCA outperforms MLA under comparable compression settings; independent benchmarks at production scale have not yet confirmed this. 6 ZAYA1-8B was trained entirely on AMD Instinct MI300 GPUs, a deliberate departure from the NVIDIA/TPU stack. 4
Laguna XS.2's per-layer query-head budgeting (from Poolside, an AI startup focused on coding LLMs) takes a different angle. Rather than compressing the K/V representation itself, Laguna assigns varying numbers of query heads per layer — more to cheap sliding-window layers (8 Q heads per KV head), fewer to expensive global-attention layers (6 Q heads per KV head) — while keeping KV heads fixed at 8 across all 40 layers. 1 The design shifts attention budget toward where it's cheaper, rather than compressing what's stored. SWE-bench Verified: 68.2%. 7
DeepSeek V4-Pro goes furthest on context length. The key move is compressing along the sequence dimension rather than per-token: CSA (Compressed Sparse Attention, compression factor m=4 with sparse top-k selection) handles medium compression; HCA (Heavily Compressed Attention, m'=128 with dense attention over a short cache) handles aggressive compression of older context. 1 3 The architectural cost: HCA trades token-level granularity for dramatically shorter sequence entries — meaning the model may "forget" details in the heavily-compressed portion. A comprehensive comparison by DeepResearch.ninja (an AI research aggregator) across eight open-weight models found DeepSeek V4-Pro's KV-cache at 1M context is roughly 10% of V3.2's, but needle-in-a-haystack retrieval accuracy drops to ~59% at the extreme. 8 The residual stream redesign (mHC, manifold-constrained hyper-connections) is a separate innovation: it replaces the single residual stream with multiple parallel streams and learned mappings, widening the gradient pathway. Previously only validated at 27B scale, it's now shipping in the 1.6T flagship — Raschka calls its production inclusion "a good sign that this idea actually works well." 1
콘텐츠 카드를 불러오는 중…
What the community is building on
The community signal is loudest around Gemma 4's practical deployability. A Hacker News post from May 21 — documenting local video indexing of a full year's footage on a 2021 M1 Max MacBook using Gemma 4 31B Q4 — pulled 470 points and 142 comments. 9 10 The author (asenna) reported that Gemma 4 31B Q4 with structured prompts "produces output that's hard to distinguish from Sonnet 4.6 on most of my test clips." Peak memory: 50.89 GB swap. The comments surfaced Apple Silicon performance data: Gemma 4 26B MoE hitting 50 tokens/s on M1 Max; Qwen 3.6 35B-A3B Q4 reaching 86 tokens/s on M5 Pro. 10
Nathan Lambert (former HuggingFace researcher, Interconnects AI newsletter) assessed the landscape on May 26: "Gemma 4's models are all tying or outperforming the equivalently sized Qwen 3.5/3.6 models in a huge number of the available benchmarks" — and fine-tuning adaptation is significantly easier than with Qwen. 11 Lambert also noted that US open-source model adoption is at its highest since Llama 3.
콘텐츠 카드를 불러오는 중…
Pricing gives the commercial picture: Gemma 4 31B runs at $0.12 per million input tokens on OpenRouter — roughly 8× cheaper than Claude Haiku, per the HN thread — while DeepSeek V4-Pro is priced at $0.435/$0.87 (input/output) versus ~$15/$75 for Claude Opus 4.7. 8 10 These numbers are per the DeepResearch.ninja analysis as of May 23, 2026; pricing changes frequently.
Three PM decisions
Pick your architecture by context window, not benchmark rank. If your application rarely exceeds 32K tokens — document chat, code review, structured extraction — Gemma 4's cross-layer sharing gives you a well-understood approximation with minimal quality loss and strong fine-tuning ergonomics. If you need reliable 128K+ contexts with high token-level recall (legal review, long-conversation agents), DeepSeek V4's CSA/HCA is the frontier bet, but the ~59% needle-in-a-haystack ceiling at 1M context is a known tradeoff — design your retrieval pipeline to compensate. If you're building a local coding agent on developer hardware, Laguna XS.2's coding-focused architecture and Poolside's open-weight commitment make it the focused choice.
Treat ZAYA1-8B as a signal, not a deployment target yet. The CCA claim that it outperforms MLA under comparable compression hasn't been independently validated at production scale. The AMD-only training stack also means hardware compatibility with NVIDIA deployments needs verification. Watch the next 60 days for third-party evals.
Hardware flexibility is a real variable now. ZAYA1-8B's AMD-native training, Gemma 4's Apple Silicon deployability (50 tokens/s on M1 Max), and Laguna XS.2's HuggingFace-native config all signal that the 2026 open-source stack is being designed to escape NVIDIA monoculture. If your infrastructure roadmap includes AMD or Apple Silicon at inference time, the architecture choice and the hardware choice are now coupled — plan accordingly.
Cover image: AI-generated illustration
참고 출처
- 1Recent Developments in LLM Architectures: KV-Sharing and the Long-Context Race
- 2The Big LLM Architecture Comparison
- 3DeepSeek V4 Preview Release
- 4ZAYA1-8B Technical Report
- 5Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
- 6Compressed Convolutional Attention
- 7Poolside launches Laguna XS.2
- 8Open-Weight Frontier Analysis, May 2026
- 9Indexing a year of video locally on a 2021 MacBook with Gemma4-31B
- 10HN thread: Indexing a year of video locally with Gemma4-31B
- 11Interconnects AI: Some ideas for what comes next, May 2026
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.