Claude Code SDK #3:Session 管理全解——continue / resume / fork 三把钥匙,让 Agent 真正拥有记忆
Session 是 Agent 的记忆,SDK 把每次对话存成本地 JSONL。本篇完整拆解三种 session 模式:continue(自动追踪最近会话)、resume(按 ID 精确恢复)、fork(分叉探索不同路径),附 Python/TypeScript 完整代码示例、CLI 对应命令,以及跨机器迁移的两种策略和四条实践建议。

리서치 브리프
Session 是你的 Agent 的记忆。
但大多数人第一次用 SDK 时,只知道一个
query(),跑完就跑完了,上下文全消失。下次调用,Agent 是个刚开机的无知状态机。这一期完整拆解 Claude Agent SDK 的 Session 管理体系:三种持久化机制的适用边界、会话 ID 的正确捕获方式、fork 的分支语义,以及跨机器迁移的存储路径约定——帮你真正把 Agent 从「一问一答工具」升级为「有记忆的协作者」。
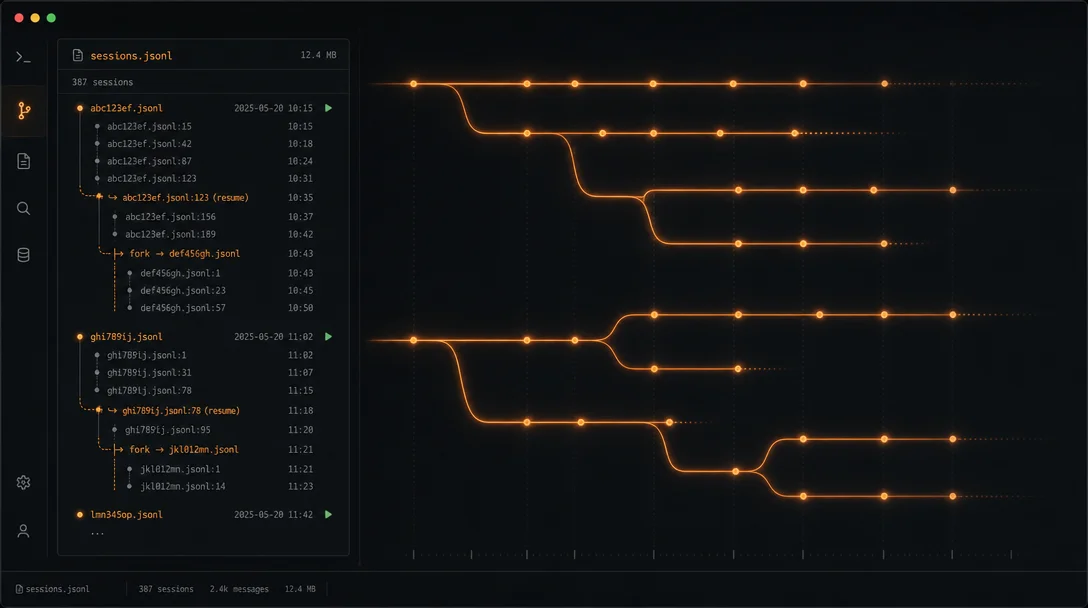
1Session 是什么?存在哪里?
Session 保存的是对话历史,不是文件系统状态。
每次 Agent 运行,SDK 会把你的 prompt、每一次工具调用、每一个工具返回、每一次 Claude 的回复,全部写到本地磁盘,格式是 JSONL。路径规则如下:
~/.claude/projects/<cwd-encoded>/<session-id>.jsonl其中
<cwd-encoded> 是当前工作目录的绝对路径,把非字母数字字符全部替换为 -。例如工作目录是 /Users/me/proj,就变成 -Users-me-proj。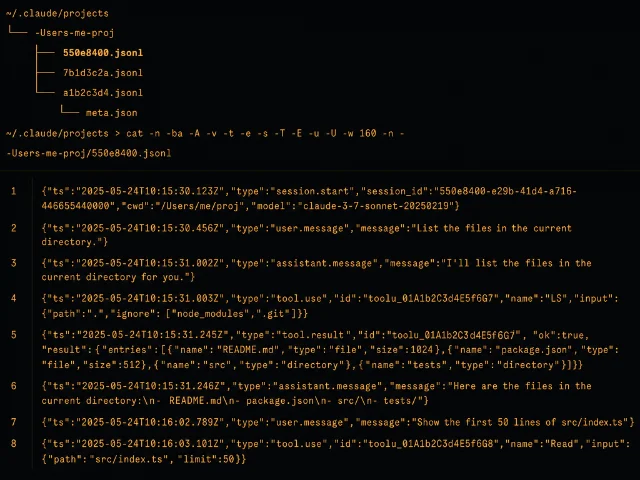
~/.claude/projects/ 下,每个工作目录单独一个子目录(AI 生成示意图) 一个关键细节:如果你在不同目录调用
resume,SDK 会去错误的路径找 session 文件,什么都找不到,然后静默地开启一个新 session。这是跨机器 resume 失败的最常见原因。三种模式:continue、resume、fork
Session 管理的核心是三个 option 字段,理解它们的差异就掌握了 90% 的用法:
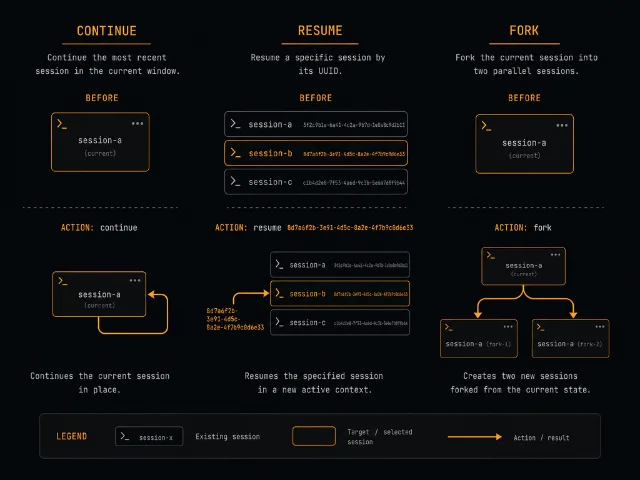
| 模式 | 如何定位 session | 适用场景 |
|---|---|---|
| continue | 自动找当前目录最近的 session | 单进程内顺序多轮对话,无需手动管 ID |
| resume | 指定 session ID | 多用户 / 多任务、跨进程恢复、需要回到特定历史 |
| fork | 基于指定 session 分叉,生成新 ID | 探索不同实现路径,保留原分支 |
下面逐个看实际代码。
continue:最简单的多轮对话
Python 用
ClaudeSDKClient,它在内部自动追踪 session ID,你完全不需要手动管理:import asyncio
from claude_agent_sdk import (
ClaudeSDKClient,
ClaudeAgentOptions,
AssistantMessage,
ResultMessage,
TextBlock,
)
async def main():
options = ClaudeAgentOptions(
allowed_tools=["Read", "Edit", "Glob", "Grep"],
)
async with ClaudeSDKClient(options=options) as client:
# 第一轮:分析认证模块
await client.query("Analyze the auth module")
async for message in client.receive_response():
if isinstance(message, AssistantMessage):
for block in message.content:
if isinstance(block, TextBlock):
print(block.text)
# 第二轮:自动续接,"it" 就指 auth module
await client.query("Now refactor it to use JWT")
async for message in client.receive_response():
if isinstance(message, ResultMessage):
print(f"Done, cost: ${message.total_cost_usd:.4f}")
asyncio.run(main())TypeScript 用
continue: true,每次后续调用带上这个 option,SDK 找当前目录最近的 session:import { query } from "@anthropic-ai/claude-agent-sdk";
// 第一轮
for await (const message of query({
prompt: "Analyze the auth module",
options: { allowedTools: ["Read", "Glob", "Grep"] }
})) {
if (message.type === "result") console.log(message.result);
}
// 第二轮:continue: true 让 SDK 自动找上一个 session
for await (const message of query({
prompt: "Now refactor it to use JWT",
options: {
continue: true,
allowedTools: ["Read", "Edit", "Write", "Glob", "Grep"]
}
})) {
if (message.type === "result") console.log(message.result);
}这种用法适合同一进程内、顺序执行的多轮任务。
resume:精确恢复指定 session
当你需要管理多个并发 session(比如每个用户一个任务),或者在进程重启后恢复特定历史,就要手动捕获并传递 session ID。
第一步:捕获 session ID
session ID 可以从两个地方读取:
- Python:
ResultMessage.session_id——每次 query 结束都会有 - TypeScript:
SystemMessage(init 类型)的session_id字段,在流的最早期就出现;ResultMessage末尾也有
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
async def first_run():
session_id = None
async for message in query(
prompt="Analyze the auth module and suggest improvements",
options=ClaudeAgentOptions(allowed_tools=["Read", "Glob", "Grep"]),
):
if isinstance(message, ResultMessage):
session_id = message.session_id # 从结果消息取 ID
if message.subtype == "success":
print(message.result)
return session_id
session_id = asyncio.run(first_run())
print(f"Captured session: {session_id}")第二步:用
resume 恢复async def follow_up(session_id: str):
async for message in query(
prompt="Now implement the refactoring you suggested",
options=ClaudeAgentOptions(
resume=session_id, # 精确指向上一个 session
allowed_tools=["Read", "Edit", "Write", "Glob", "Grep"],
),
):
if isinstance(message, ResultMessage) and message.subtype == "success":
print(message.result)
asyncio.run(follow_up(session_id))resume 的典型场景:
- Agent 上一轮分析完了一个模块,这一轮继续在那个分析基础上修改代码,不需要重读文件
- 上一轮跑到
max_turns限制中断,这一轮调高上限后恢复 - 服务重启,从数据库里取出上次保存的 session ID,用户继续对话
fork:保留原路,探索新路
Fork 是 Session 管理里最精妙的操作。它不是修改现有 session,而是基于当前 session 历史创建一条独立分支,两条路从此互不干扰。
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
# 假设 session_id 已有一轮分析 auth module 的历史
async def explore_alternatives(session_id: str):
# 分叉:从 session_id 的历史出发,探索 OAuth2 路径
forked_id = None
async for message in query(
prompt="Instead of JWT, implement OAuth2 for the auth module",
options=ClaudeAgentOptions(
resume=session_id,
fork_session=True, # 关键:创建新 session,不修改原 session
),
):
if isinstance(message, ResultMessage):
forked_id = message.session_id # fork 的 ID != session_id
if message.subtype == "success":
print(f"OAuth2 approach: {message.result}")
print(f"Fork ID: {forked_id}")
# 原 session_id 未被修改,继续 JWT 路径
async for message in query(
prompt="Continue with the JWT approach",
options=ClaudeAgentOptions(resume=session_id),
):
if isinstance(message, ResultMessage) and message.subtype == "success":
print(f"JWT approach: {message.result}")
asyncio.run(explore_alternatives(session_id))注意:Fork 分叉的是对话历史,不是文件系统。如果两个分支都对代码做了实际修改,文件层面会互相覆盖。如果你需要文件也独立,要配合 file checkpointing 一起用。
CLI 对应关系:脚本里的 session 操作
SDK 的 session 概念在 CLI 里有直接映射,对调试和手动操作很有用:
# continue:接续当前目录最近的 session
claude -c -p "继续上次的任务"
# resume:按 ID 或名字恢复
claude -r "auth-refactor" "Finish this PR"
claude --resume "550e8400-e29b-41d4-a716-446655440000" "继续分析"
# 给 session 命名(方便 resume 时用名字而不是 UUID)
claude -n "auth-refactor" "开始认证模块重构"
# fork:resume 时加 --fork-session flag
claude --resume abc123 --fork-session
# 禁用持久化(TypeScript SDK 专属,CLI 无效)
claude -p --no-session-persistence "一次性查询,不写磁盘"跨机器迁移:两种策略
Session 文件是本地的。在 CI 环境、容器、Serverless 里跨主机 resume,有两个选择:
콘텐츠 카드를 불러오는 중…
方案一:迁移 session 文件
把
~/.claude/projects/<cwd-encoded>/<session-id>.jsonl 从机器 A 复制到机器 B 的相同路径(cwd 必须一致),然后正常 resume。方案二:不依赖 session resume
把 Agent 上一轮的分析结果、决策、关键输出保存为应用状态(数据库、文件等),下一轮通过 prompt 注入。这在无状态场景下往往更健壮。
两套 SDK 都提供了 session 枚举和读取函数:Python 的
list_sessions() / get_session_messages(),TypeScript 的 listSessions() / getSessionMessages(),可以自建 session 选择器或清理逻辑。实践建议
1. 单进程顺序任务,用
ClaudeSDKClient(Python)或 continue: true(TypeScript),不要自己管 ID,出错的可能性最小。2. 多任务 / 多用户场景,从
ResultMessage.session_id 取 ID 就存数据库,不要依赖「最近一个」的隐式逻辑。3. 先 fork 再实验,任何有可能搞坏对话历史的探索性操作,先 fork 一个分支出去,原 session 保持干净。
4. 注意 cwd 一致性,
resume 失效 90% 是 cwd 不匹配,在脚本里可以用 os.chdir() / process.chdir() 显式指定,或者直接传入 session ID 的完整文件路径。5. TypeScript 可以用
persistSession: false 做一次性无状态查询,不写磁盘,适合高频短任务流水线里不需要回溯的场景。下期预告:工具调用(Tool Use)——
allowed_tools、disallowedTools、权限规则语法,以及如何在自动化脚本里精确控制 Agent 能操作什么、不能操作什么。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.