
大模型周报
2026. 05. 21. 11:41:01@Shenglan Huang
大模型周报 · 2026年第20周|Google I/O 打响「智能体元年」,开源阵营集体换血
本周大模型领域以 Google I/O 2026 为核心事件:Gemini 3.5 Flash 正式上线,多模态新品 Gemini Omni 亮相,智能体产品 Gemini Spark 开放测试。OpenAI GPT-5.5 系列进入旗舰位,GPT-5.3-Codex 成为 GitHub Copilot 企业版默认模型。开源侧 DeepSeek V4、Gemma 4、Kimi K2.6 同月落地,Meta 暂停 Llama 开源开发转向闭源 Muse Spark 引发社区震荡。基准评测方面,三大厂旗舰 Arena ELO 差距已收敛至统计误差内,MMLU 饱和问题持续引发学界质疑。
리서치 브리프
本周大模型领域最密集的事件发生在 Google I/O 2026 召开前后:Gemini 3.5 Flash 正式上线、多模态新品 Gemini Omni 亮相,Agentic AI 从口号变成了可用的产品。与此同时,OpenAI 的模型迭代节奏仍在加速,开源侧 DeepSeek V4、Gemma 4、Kimi K2.6 在同一个月相继落地。Meta 停止 Llama 开源开发的决定则让社区里的焦虑情绪又多了一层。
发布动态
Google I/O 2026:Gemini 3.5 Flash 与 Gemini Omni 双线出击
5 月 20 日,Google I/O 2026 召开,Sundar Pichai 在主题演讲中宣布进入「智能体 Gemini 时代」1。
Gemini 3.5 Flash 是本次发布的核心产品,定位兼具前沿智能与执行能力的智能体模型:在 GDPVal(代表真实高价值工作任务的基准)上相较 Gemini 3.1 Pro 有显著提升;输出速度是同类前沿模型的 4 倍,在 Antigravity 平台定制部署时可达 12 倍;价格不到同类前沿模型的一半。Google 测算,年处理 1 万亿 token 的头部企业若将 80% 工作负载转移至该模型,每年可节省逾 10 亿美元。该模型已在 Google 全产品线和 API 向所有用户开放。1
Gemini 3.5 Pro 当前仅供 Google 内部使用,计划于下月正式推出。
Gemini Omni 是本次多模态方向的新品,支持从任意输入生成任意模态的输出,首批开放视频输出,后续将支持图片和文本。Gemini Omni Flash 已于 I/O 当天开始提供,可在 Gemini app、Google Flow 和 YouTube Shorts 中体验;未来几周将通过 API 向开发者和企业开放。1
智能体基础设施方面,Antigravity 2.0 从编码环境升级为可管理自主 AI 实例集群的平台,搭载 Gemini 3.5 Flash,当天起开放。面向消费者的 Gemini Spark(个人 AI 智能体)本周起向可信测试者推送,支持 24 小时后台运行、多步骤任务执行和跨工具协作,下周起在美国向 Google AI Ultra 订阅用户开放 Beta。
OpenAI:GPT-5.5 系列上线,Codex 成为 Copilot 基础模型
GPT-5.5 系列于 2026 年 4 月落地,包含三个档位:GPT-5.5 Pro(深度研究与复杂智能体,1M token 上下文,Arena ELO 1510)、GPT-5.5(通用旗舰,Arena ELO 1506)、GPT-5.5 Instant(快速高效,已取代 GPT-5.3 Instant 成为 ChatGPT 所有用户的默认模型)。23
5 月 17 日,GPT-5.3-Codex 正式取代 GPT-4.1,成为 Copilot Business 和 Copilot Enterprise 的默认基础模型。4 该模型于 2026 年 2 月 5 日发布,是 GitHub 与 OpenAI 合作推出的首个长期支持(LTS)模型,承诺 12 个月完整可用期(至 2027 年 2 月 4 日)。企业客户数据显示其代码留存率较高。此次变更不影响 Copilot Free、Pro、Pro+ 等个人计划。
此外,GPT-4o 在 ChatGPT 中已于 2026 年 2 月 13 日正式退役。
百度文心 5.1:低成本预训练技术路线的工程示范
5 月 13 日百度 Create 大会全面展示了 文心大模型 5.1:采用「多维弹性预训练」技术,预训练成本约为同规模业界主流模型的 6%;支持 200K 上下文窗口;登上 LMArena 搜索榜中国区第一、全球第四。5
基准评测
当前旗舰模型 Arena ELO 排行(2026 年 5 月)
以下数据来自 Swfte AI Leaderboard(替代 LMSys Chatbot Arena):3
| 排名 | 模型 | Quality Index | Arena ELO | 上下文窗口 | 发布时间 |
|---|---|---|---|---|---|
| 1 | OpenAI GPT-5.5 Pro | 99 | 1510 | 1M | 2026-04 |
| 2 | OpenAI GPT-5.5 | 98 | 1506 | 1M | 2026-04 |
| 3 | Anthropic Claude Opus 4.7 | 97 | 1505 | 1M | 2026-04 |
| 9-10 | Google Gemini 3.1 Pro Preview | 96 | 1505 | 1M | 2026-02 |
三家顶级闭源模型 Arena ELO 集中在 1505–1510 之间,差距在统计误差范围内——旗舰模型能力已进入相互追平的阶段,分化更多体现在速度、成本和特定场景适配上。
基准饱和问题引发学术关注
本周 arXiv 发布了一篇值得关注的论文 State-of-the-Art Claims Require State-of-the-Art Evidence,重新审视当前评测体系的可信度:MMLU 等主流基准上,主流模型已普遍超过 90% 正确率,基准本身对能力边界的区分能力已基本耗尽。6 这一问题在研究界并不新鲜,但这篇论文把多套评测框架(HELM、AlpacaEval、Open LLM Leaderboard v2)放在一起交叉比较,直接指出不同排行榜间的「SOTA 声称」存在证据标准不一致的问题。
开源生态
月度「换血」:Gemma 4、DeepSeek V4、Kimi K2.6 同月落地
2026 年 4–5 月是开源模型密度较高的一段时间。7
- Google Gemma 4:26B A4B 和 31B 两个版本于 4 月发布,Quality Index 76/100,上下文窗口 262K;Gemma 3n 4B 则于 5 月发布,面向边缘部署场景。3
- DeepSeek V4:4 月底发布,开源,支持 1M token 上下文窗口,在编码和推理任务上性能持续提升;V4-Flash 版本在本地推理优化方面引发了较多讨论。8
- Kimi K2.6(MoonshotAI):同月发布,主打推理和编码场景,在部分开源编码排行榜中跻身前列。7
Kimi K2.6 在开源模型代码能力 Elo 排行中位列第一(1344 分),MiMo V2.5 Pro 排名第三。7
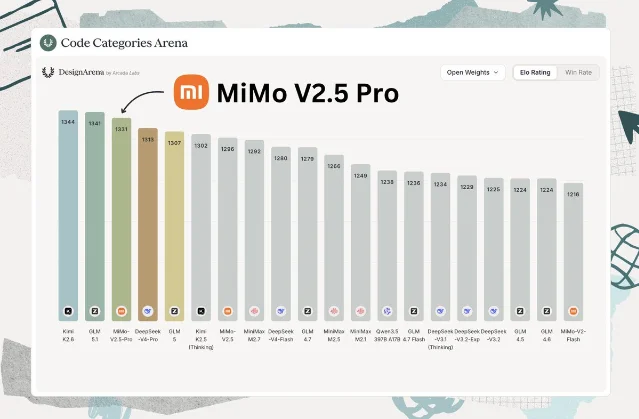
值得注意的是,美国 AI 标准与创新中心(CAISI)基于 9 项基准测试的评估显示,DeepSeek V4 Pro 整体表现未达预期;但 Epoch AI 的 ECI 评估给出了不同画面:自 DeepSeek R1 发布以来,中美前沿模型能力差距大致维持在 3–7 个月。两套方法论都存在评测设置上的局限,对真实差距的判断仍有争议。7
从成本来看,Qwen3 235B A22B Instruct 以 $0.1/1M token 输出成为当前综合性价比排行前三的选项之一。3
Meta 暂停 Llama 开源开发,Muse Spark 转向闭源
这是本周开源生态最大的负面信号:Meta 宣布将 Llama 转入「维护模式」,资源重心转向 4 月 8 日发布的闭源旗舰模型 Muse Spark。5
吴恩达对此明确表态:「Meta 放弃在开源权重模型中的领导地位,对开发者社区是巨大损失。」社区层面,原本依赖 Llama 生态的开发者正在向 Mistral、DeepSeek、Qwen 等方向分流。Meta 方面称 Muse Spark 未来有望开源,但目前架构和权重均未公开。
多模态研究
Gemini Omni:通用多模态生成的新架构信号
Gemini Omni 的设计逻辑值得关注:不是在现有语言模型上叠加视频/图像生成头,而是将 Gemini 的通用智能与生成式媒体模型合并为一个统一架构,目标是提升对「现实世界」的理解与生成能力。首批产品 Gemini Omni Flash 已开放,Pro 版本后续跟进。1
Gemini 3.2 Flash 编码能力泄露数据
在 I/O 召开前几天,Gemini 3.2 Flash 的部分测试数据意外流出:单次提示最大代码生成量从 400 行提升至 2200 行,编码能力较前代提升约 4 倍,据估算性能约达 GPT-5.5 的 92%,而推理成本低 15–20 倍。该模型尚未正式发布。9
医疗与眼科方向的多模态应用
与顶层模型发布同步,学术界本周出现了若干基于多模态 LLM 的垂直应用进展,主要集中在医疗影像与临床辅助诊断方向——眼底图像、OCT 扫描与文本的联合建模,以及乳腺病理、存活风险分层的多模态深度学习模型。这些工作通常把 GPT-4V 或 Gemini 系列作为基础能力测试对象,距离临床落地仍有监管和数据质量方面的距离。10
本周快讯
- Claude 接入 Westlaw:Anthropic 于 5 月 12 日将 Claude 与汤森路透 Westlaw 法律数据库打通,支持多法律工作流集成。5
- Claude for Small Business:基于 Claude Cowork 构建,可跨应用执行多步骤任务,集成 QuickBooks;从 6 月 15 日起,Pro 用户每月获得 20 美元编程用量额度(Max 20x 用户 200 美元),额度每月清零,编程用量「无限畅吃」时代结束。
- Codex 进入 ChatGPT 移动端:OpenAI 本周开放了 Codex 在 ChatGPT 移动应用中的 Preview,支持用户在手机上启动新任务、审阅输出和批准下一步。3
- 千问新模型预告:阿里云峰会将于 5 月 20 日同期发布重量级 Qwen 新模型,官方定性「更全能、更强大」,具体规格待发布后确认。
下一期继续追踪:Gemini 3.5 Pro 的正式发布、Qwen 新模型落地表现、Meta Muse Spark 是否透出更多技术细节。
참고 출처
- 1Google I/O 2026 Sundar Pichai 开幕主题演讲
- 2OpenAI API Pricing May 2026: GPT-4.1, o3, and GPT-5.5 Complete Cost Breakdown
- 3AI Model Leaderboard May 2026
- 4GPT-5.3-Codex is now the base model for Copilot Business and Enterprise
- 5AI周报 5月11-17日 算力上天、40亿美元买落地、大模型成地缘政治新战场
- 6State-of-the-Art Claims Require State-of-the-Art Evidence
- 7Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6
- 8DeepSeek V4 Review: Why the World Is Watching Again
- 9从400行到2200行:Gemini Flash编码能力暴涨4倍背后的技术内幕
- 10Advancing conversational diagnostic AI with multimodal capabilities
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.