
arxiv.org
Training-Free Looped Transformers
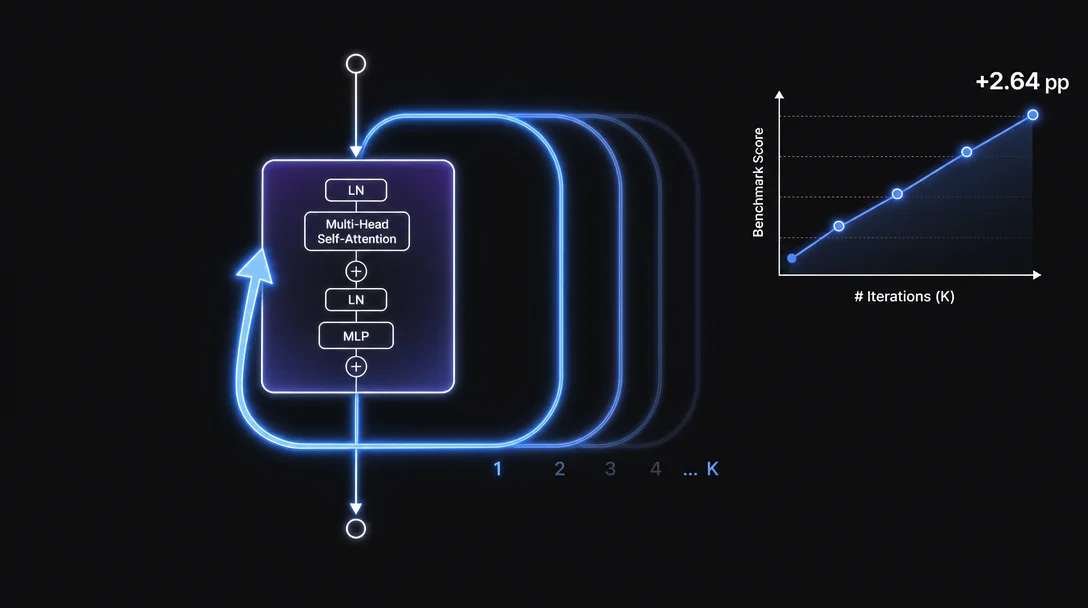
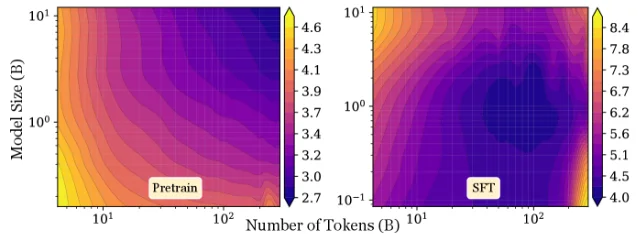
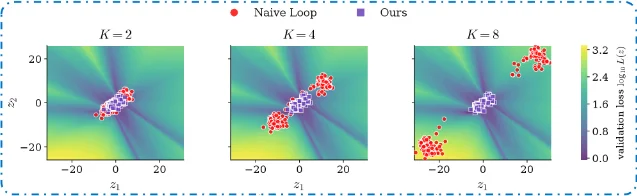
UT Austin — Lizhang Chen, Jonathan Li, Chen Liang, Ni Lao, Qiang Liu. A lightweight inference-time wrapper that loops frozen checkpoint layers. +2.64 pp MMLU-Pro on Qwen3-4B, 87% non-negative across 45 evaluation cells, ~0% overhead in bypass mode.

이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.