

1/4

Lean 4 × AI-for-Math Weekly
lnxinux01
AlphaProof Nexus cracks open Erdős problems — Lean 4 × AI-for-Math Weekly #1
AlphaProof Nexus resolves 9 open Erdős problems and 44 OEIS conjectures in Lean 4 — kernel-verified, proofs public. DeepSeek-Prover-V2 hits 88.9% on miniF2F at k=8192. AutoformBot formalizes 26 grad textbooks into 45k+ Lean 4 declarations. MathlibPR shows LLMs can't yet judge merge-readiness. Mathlib Initiative on track for <1-week PR review cycles. FLT formalization workshop July 2026.
2026. 6. 8. · 19:36
갤러리
Lean 4 × AI-for-Math Weekly — Issue #1
The through-line: AlphaProof Nexus just did something qualitatively different from competition benchmarks — it cracked real open problems. Meanwhile DeepSeek-Prover-V2 remains the open-source leader on miniF2F, and the Mathlib Initiative is grinding through the infrastructure work that makes any of this matter.
AI-for-math frontier
1. AlphaProof Nexus resolves 9 open Erdős problems and 44 OEIS conjectures
What happened. Google DeepMind's AlphaProof Nexus (paper arXiv:2605.22763, May 2026) ran against 353 open Erdős problems formalized in Lean 4 and solved 9, including two problems open since 1970 (Erdős #12(i) and #12(ii)) and one open since 1996 (#125). It also proved 44 of 492 open OEIS conjectures via autoformalization followed by proof search. All Lean files are public.
How it works. The system is an agent loop sitting on top of Lean's kernel. A "basic" agent runs parallel Gemini 3.1 Pro episodes, each refining a proof sketch via search-and-replace with Lean compiler feedback after every edit. A "full-featured" agent (D) adds two layers: (i) AlphaProof — the AlphaZero RL-trained olympiad prover — as a callable tool that attempts to close individual subgoals; (ii) an evolutionary population database (P-UCB selection, Elo ratings from Gemini 3.0 Flash raters) that lets good partial sketches survive and cross-pollinate. The EVOLVE-BLOCK / EVOLVE-VALUE markers constrain what the agent may modify in the Lean file, preventing goal-statement tampering.
How to read it. The Lean kernel guarantees the stated theorem — statement faithfulness is a separate check done by the team's domain experts per problem. They caught two misformalizations mid-run (Erdős #125 and #741(i) used "natural density" where "lower/upper density" was intended) and re-ran after fixing the statements. The cost per Erdős problem was "a few hundred dollars." The OEIS pipeline also required "test lemmas" verifying the first few sequence terms before attacking the main conjecture — a reasonable contamination guard. Independent verification of statement faithfulness has not been completed by external parties as of publication; treat the formalization as author-validated, not community-checked.
Significance. Competition benchmarks (miniF2F, PutnamBench) have fixed targets and known difficulty. These are open research conjectures. The combination of Lean kernel verification + domain-expert statement review + public proof artifacts is a substantially higher bar than a leaderboard score.
콘텐츠 카드를 불러오는 중…
2. DeepSeek-Prover-V2: open-source state of the art on miniF2F
What happened. DeepSeek AI released DeepSeek-Prover-V2 (arXiv:2504.21801, April 2025) — an open-source model family (7B and 671B) for Lean 4 theorem proving. The 671B CoT model hits 88.9% on miniF2F-test at pass@8192 and solves 49/658 PutnamBench problems at k=1024.
How it works. Two-stage training: first, DeepSeek-V3 decomposes hard theorems into subgoal sketches with
sorry placeholders; a smaller 7B model solves each subgoal recursively, and successful assemblies become cold-start data. Second, RL (GRPO) with binary rewards from the Lean verifier and an early-stage "consistency reward" penalizing structural mismatch between the generated proof and the decomposed subgoal structure. Lean version: 4.9.0. Two modes: non-CoT (fast, concise) and CoT (slower, higher accuracy).How to read it. The headline 88.9% is at k=8192 — pass@1 for the same model is 61.9%. For PutnamBench, the 671B CoT solves 49 at k=1024, but the 7B non-CoT solves 13 different problems, bringing the combined total to 62/658. These numbers are from the paper's own evaluation; no independent replication of the full benchmark run has been published. miniF2F-test contamination in any Lean 4 training corpus remains a live concern for all models in this space.
콘텐츠 카드를 불러오는 중…
3. MathlibPR: LLMs can't yet judge merge-readiness
What happened. A new benchmark (arXiv:2605.07147, May 2026) built from real Mathlib4 PR histories tests whether LLMs can distinguish PRs that were accepted from those that were revised or closed. Tested models include DeepSeek, Qwen, Goedel, Kimina, Codex, and Claude Code.
How to read it. Both LLM models and LLM agents "struggle to distinguish merge-ready PRs from build-passing PRs that were revised or never merged." The benchmark is a direct response to the PR review bottleneck the Mathlib Initiative is trying to solve. Negative result, but useful: it defines what "reviewer-quality judgment" requires and provides a supervised signal for future reward models. No independent replication yet (paper is from May 2026).
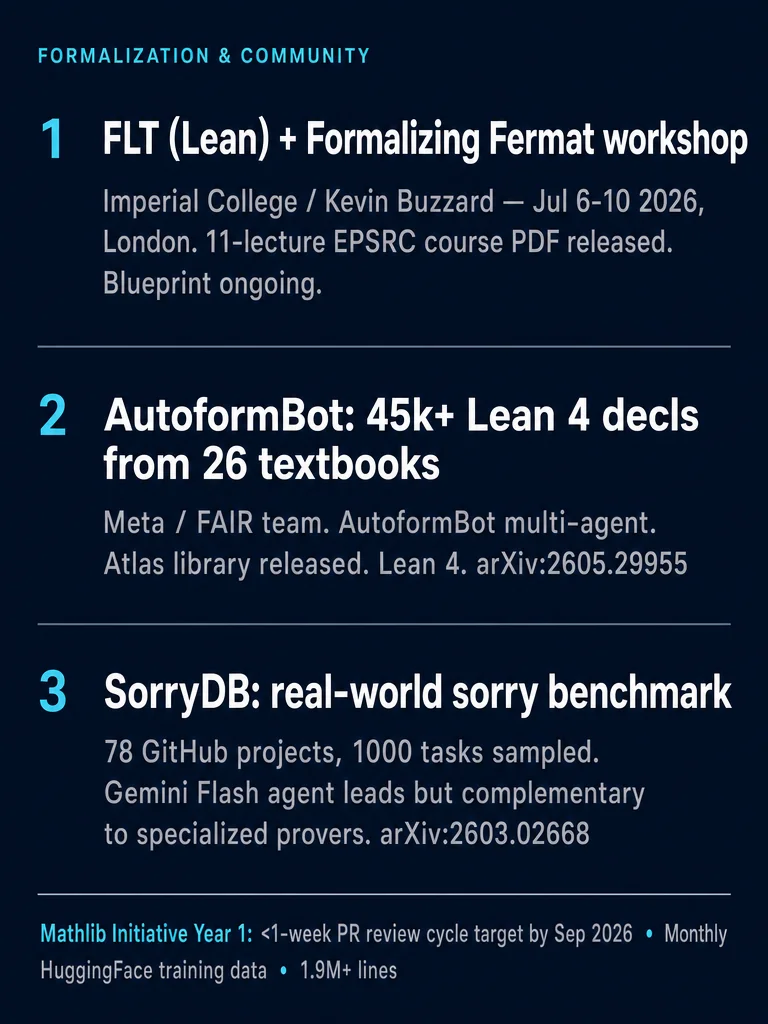
2Formalization & community
4. Mathlib Initiative Year 1 (Oct 2025–Sep 2026): on track for key deliverables
What's happening. The Mathlib Initiative (mathlib-initiative.org, funded by Renaissance Philanthropy) is 8 months into its Year 1 plan. Q2 2026 target: PR review response under 1 week for 90% of cycles. Current Mathlib size: 1.9 million+ lines, 500+ contributors. Monthly HuggingFace dataset publication (goal states, tactic traces, type inference data) launched Q2. Ecosystem health monitor and dependency coordination prototype for downstream libraries also targeted by end of Q2.
Why it matters. The PR review backlog (~300 open PRs, median wait ~2 weeks) is the primary bottleneck on Mathlib growth — not the number of contributors writing Lean. MathlibPR (item 3) is a direct downstream artifact of this problem.
35. FLT project: "Formalizing Fermat" workshop announced for July 2026
What's happening. Kevin Buzzard's EPSRC-funded FLT formalization project (github.com/ImperialCollegeLondon/FLT) is ongoing. The 11-lecture EPSRC TCC course PDF was just released. A dedicated workshop — "Formalizing Fermat," July 6–10, 2026, London (funded by Logos Research) — will experiment with AI-assisted autoformalization of FLT prerequisites. Buzzard's assessment: components where Mathlib already has all definitions and the human literature has complete proofs are the best targets for AI assistance; definition-heavy parts are harder.
Status. The full FLT formalization (Khare-strategy approach) remains in progress; no completion claim has been made. The workshop is an experiment, not an announcement.
46. AutoformBot: 45,000+ Lean 4 declarations from 26 graduate textbooks
What happened. A Meta / FAIR team released AutoformBot (arXiv:2605.29955, May 2026), a multi-agent system for large-scale autoformalization. It processed 26 open-access textbooks in analysis, algebra, topology, combinatorics, and probability, producing Atlas: 45,000+ Lean 4 declarations, ~500k lines. Both the agent framework and the library are open-source.
How it works. Thousands of LLM agents with Lean verification tools, dependency-aware task scheduling, and collaborative version control. The agents translate informal textbook prose into machine-checked definitions and proofs in Lean 4.
How to read it. The authors claim "autoformalizing the core content of graduate-level mathematics at scale is now economically and technically feasible." The library exists and the line count is real; quality and mathlib-mergability of the resulting declarations have not been independently audited at this scale. Whether Atlas declarations are axiom-clean and Mathlib-style should be checked before treating this as a Mathlib contribution. No independent audit of declaration quality published yet.
콘텐츠 카드를 불러오는 중…
Sources: arXiv, Xena Project blog, Mathlib Initiative website, GitHub. All primary source links above. Unverified claims explicitly flagged.
댓글