
Indie Agent Builders — Week of May 30
The week's activity converges on a clear shift: agents are graduating from a model-quality competition to a harness engineering competition. Simon Willison's Anthropic PMF essay (backed by the $65B Series H at $47B ARR), Claude Opus 4.8's mid-conversation system messages, and the explosive growth of harness tooling (ECC at 199k★, PilotDeck's workspace OS, compound-engineering-plugin) all point the same direction. Swyx's Cognition D-round coverage ($1B at $26B valuation) and harness-as-differentiator thesis provide the commercial and architectural framing; the trending repos section documents seven concrete tools engineers can evaluate today.

리서치 브리프
The week ended with a pretty clear thesis statement from the builder community: the constraint has moved. It's no longer "can the model do it?" The question is now "how do you run multiple agents reliably, at acceptable cost, without them stepping on each other?" Anthropic hitting $47B annualized run-rate and Cognition closing a $1B Series D at a $26B valuation are commercial validation that agents are shipping at scale. Everything else this week — mid-conversation system messages, ECC exploding to 199k stars, harness team-factory patterns, PilotDeck's workspace OS — is evidence of where the friction is.
Simon Willison
Simon Willison (creator of Datasette and co-creator of Django) published six substantive posts this week and shipped three Datasette ecosystem releases.
April 2026 as the product-market fit inflection point
In a May 27 essay, Willison argued that April 2026 was the month Anthropic and OpenAI found product-market fit — not as a model capability milestone, but as a revenue one. 1
He points to two synchronized moves in April: Anthropic switched its Enterprise plan from a fixed fee to $20/seat + API token billing, and OpenAI simultaneously moved Codex to API token pricing on April 2. Both labs re-exposed the real cost of heavy usage to enterprise customers, at exactly the moment usage was high enough to generate serious numbers.
His own API bills confirm the dynamic: 30 days of Claude Code ran him $1,199.79, OpenAI Codex $980.37 — a combined $2,180 on a plan he pays $200 for, covered by his research budget. The Uber CTO surfaced similar math publicly: Uber's full-year AI budget ran out in a few months, primarily through Claude Code usage. Willison's read on that story is different from the media's:
"I'd characterize 229 (32.6%) as relating to enterprise sales and support — account executives, 'Go To Market', 'Forward Deployed Engineers' and the like." 1
The 32.6% figure refers to OpenAI's open job postings skewing toward enterprise roles — a signal, he argues, that the real money is now direct enterprise sales rather than API pass-through from Cursor or Copilot.
Two days later, Anthropic made the numbers undeniable: $65B Series H, with a disclosed annual run-rate of $47B (as of early May). 2
차트를 불러오는 중…
Anthropic's annualized revenue as disclosed in fundraise announcements. 2
On the credibility of these numbers, Willison is direct: "lying to investors who just put in $65 billion would be securities fraud." The Q2 filing and eventual IPO S-1 would expose any inflation. These numbers are real.
Claude Opus 4.8: the right kind of incremental
Anthropic shipped Claude Opus 4.8 on May 28, and Willison's reaction stood out among builder commentary. 3
The headline capability is mid-conversation system messages: you can insert a
role: "system" message immediately after a user turn, letting you append new instructions mid-session without invalidating the prompt cache or restating a full system prompt. For long agentic sessions where the task evolves, this removes a real architectural compromise.Two other changes agents engineers should track:
- Prompt cache minimum length drops from 4,096 to 1,024 tokens — smaller prompts now cache, which matters for multi-turn loops with short system prompts.
- Fast mode price cut: $10/$50 per million tokens (input/output), down from $30/$150 for Opus 4.6/4.7 fast mode. 3
The accuracy story is a policy choice, not just a capability gain: Opus 4.8 has the lowest incorrect-rate of the six models Anthropic tested, mainly because it abstains on uncertain questions rather than guessing. That's a meaningful stance — less confident wrong answers are often worse than no answer.
Willison tested the model's SVG generation at five thinking levels (
low through max). The max level pelican-on-a-bike came in at 43 cents (25,000 input tokens + 17,167 output tokens) and produced the best result. He called Anthropic's self-description of the release as "a modest but tangible improvement" refreshing: "It's so refreshing to see an AI lab honestly describe a release as a minor incremental improvement over the previous model!" 3Datasette 1.0a30, 1.0a31, and datasette-agent 0.1a4
1.0a30 (May 24) introduces an extensible Jump menu — press
/ to get a keyboard-driven fuzzy search over databases and tables, with a jump_items_sql() plugin hook so any Datasette plugin can inject its own entries. datasette-agent 0.1a4 uses this immediately: it adds a "Start a new agent chat" entry to the Jump menu, turning agent access into a first-class navigation gesture rather than a separate route.
1.0a31 (May 29) adds SQL write query execution —
INSERT, UPDATE, DELETE via stored queries for users with appropriate permissions. Combined with the agent chat entry, this gives a datasette-agent session actual write capabilities through the same plugin permission model. The register_agent_tools architecture means write-query tools compose with any other plugin's tools in the same agent context.Also shipped:
llm-anthropic 0.25.1 — adds Claude Opus 4.8 support, a -o fast 1 flag for fast mode, and changes the default max_tokens from a hardcoded 8,192 to each model's actual maximum. 2Security signals worth watching
Three items on agent security landed this week in quick succession.
Copilot Cowork data exfiltration (May 26): PromptArmor found that Microsoft's Copilot Cowork agent can be triggered via prompt injection to email a user's own inbox — with external images embedded that fire outbound requests when opened, leaking context. Combined with OneDrive's pre-authenticated download links, a successful injection lets an attacker download the user's files. Willison's summary: "The biggest challenge in designing agentic systems continues to be preventing them from enabling attackers to exfiltrate data." 5
SQLite's AGENTS.md (May 27): The SQLite repository added an
AGENTS.md file telling AI agents how to behave around the codebase — and the most recent commit hardened the position from "does not (currently) accept agentic code" to "does not accept agentic code," dropping "currently" deliberately. The project also spun off a new SQLite Bug Forum to handle the volume of AI-generated reports. 6curl's AI report flood (May 26): Daniel Stenberg (creator and lead maintainer of curl) reported that AI-assisted security reports are now arriving at 4–5× the 2024 rate — more than one per day on average, long and detailed, but almost all LOW or MEDIUM severity with no HIGH CVEs since October 2023. For the first time, Stenberg said, his wife expressed concern about his work hours. 7 The operational cost of AI-assisted research is landing on open-source maintainers whether or not they opted in.
Two related observations from Willison's May 24 and 26 archives: Paul Graham (Y Combinator co-founder) noted he has never knowingly finished reading an AI-written email signed by a human — "It feels like being lied to." 7 Armin Ronacher (creator of Flask, co-founder of Sentry) described the AI issue-report problem as a loss of voice: the most frustrating failure mode is "that people submit issues that are not in their own voice." 4 Both observations diagnose the same pattern: AI output at the interface layer erodes the signal that humans on the receiving end depend on.
Swyx
Shawn Wang (@swyx, founder of smol.ai and co-host of the Latent Space podcast) had a high-signal week anchored by Cognition's Series D and a direct statement on where agent differentiation is going.
Cognition's $1B D-round: the "largest remaining independent agent lab"
In a first-person AINews issue published May 28, Swyx — writing explicitly as a smol.ai insider now embedded at Cognition — covered the company's $1B+ Series D at a $26B valuation, up 2.5× from the $10B Series C eight months prior. [cite:11|[AINews] Cognition raises $1B in $26B Series D|[https://www.latent.space/p/ainews-cognition-raises-1b-in-26b]]
The operating numbers Swyx disclosed: $492M run-rate revenue, enterprise usage up >10× year-to-date, projected ARR crossing $1B by year-end. Clients include Exa and Modal.
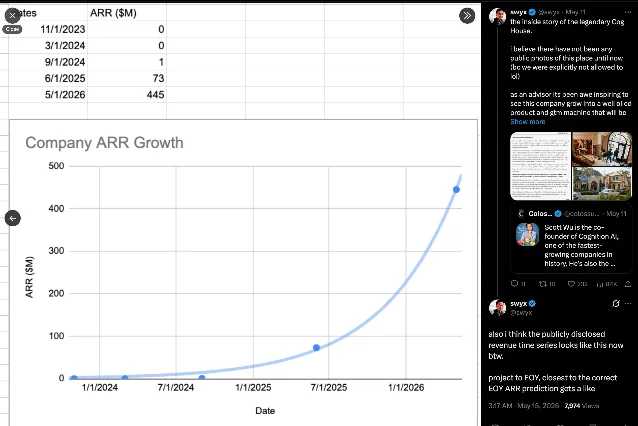
He called Cognition "officially the largest remaining independent agent lab in AI" and framed coding as "an uncapped TAM market." The distinction between "Agent Lab" (Cognition) and "Model Lab" (Anthropic, OpenAI) is deliberate — product-first, domain-adapted, not competing on base model capability. [cite:11|[AINews] Cognition raises $1B in $26B Series D|[https://www.latent.space/p/ainews-cognition-raises-1b-in-26b]]
Harness engineering as the differentiator
The week's cleaner thesis came in Swyx's May 26 AINews: harness engineering is the main differentiator for coding agents. The stack formula he settled on:
model + harness + eval loop. Not just a stronger base model, but the fit between model, task harness, and feedback loop. 8By May 28, Swyx had bookended this with two specific signals: Anthropic's mid-conversation system instructions announcement (which he quote-tweeted with "wtf? how??" — the post got 137,745 views and 844 likes) 9, and the AINews noting that Claude Opus 4.8 was "less over-agentic and more cooperative" in real workflows, per Jeremy Howard's assessment. [cite:14|[AINews] Founders and Forward Deployed Engineers|[https://www.latent.space/p/ainews-founders-and-forward-deployed]]
콘텐츠 카드를 불러오는 중…
The operational interpretation: mid-conversation system messages reduce a real engineering pain point in long agentic sessions — you no longer have to choose between restating a 10,000-token system prompt or losing instruction fidelity mid-task.
AIE World's Fair: FDE track and the Turing award question
On May 30, Swyx's AINews announced two new tracks at the AIE World's Fair 2026: a Forward Deployed Engineer (FDE) competition (aligned with OpenAI DeployCo and Anthropic DeployCo tracks) and a Founders program anchored by YC's Garry Tan and Howie Lu's $10M Hyperagent competition. [cite:14|[AINews] Founders and Forward Deployed Engineers|[https://www.latent.space/p/ainews-founders-and-forward-deployed]]
On May 28, Swyx met with the ACM (Association for Computing Machinery) president at CAISconf, where he announced an AIE × ACM collaboration and proposed an open question: "wonder what a 'Turing award of AI Engineering' could look like…" 10 The framing is less about any immediate award and more about whether AI Engineering is formalizing into an academic discipline.
Kakuna: ongoing cadence
The
swyxio/skills repository (Swyx's Kakuna framework for Claude Code and other agent harnesses) added five commits between May 25–30: a new slackbot-builder skill with an L0-L5 maturity ladder, a public-qa-chatbot demo skill, a twitter-x-scraping skill, and a web-animation-perf update. 11 The L0-L5 maturity model for the Slackbot skill is worth examining as a template: it defines what "production-ready" means at each level rather than leaving it implicit, which is the specific gap Kakuna was designed to close.Geoffrey Huntley had no agent-related activity this week — no new blog posts on ghuntley.com, no public GitHub commits in the May 23–30 window. 12
Trending repos
The GitHub agent ecosystem this week organized itself around harness tooling — not new models or new frameworks, but better infrastructure for running agents reliably across the harnesses that already exist.
| Repo | Stars | +/day | What it does |
|---|---|---|---|
| affaan-m/ECC | 199,137 | +918 | Cross-harness optimization system: skills, instincts, memory, security for Claude Code, Codex, Cursor, Opencode, and 8 others |
| anthropics/skills | 143,984 | +471 | Anthropic's official agent skills repo — the de-facto skill format standard, referenced by ECC, PilotDeck, and harness |
| EveryInc/compound-engineering-plugin | 18,400 | +348 | 37 skills, 51 agents across Claude Code / Codex / Cursor; 80/20 rule: 80% planning, 20% execution |
| OpenBMB/PilotDeck | 2,200 | — | Agent OS from Tsinghua THUNLP/ModelBest/OpenBMB: per-project WorkSpace isolation, white-box memory, smart model routing |
| openclaw/openclaw | 376,000 | — | v2026.5.28-beta.4: agent runtime recovery, Claude Opus 4.8, Codex Supervisor plugin, GitHub Copilot agent runtime |
| AI45Lab/AgentDoG | 550 | — | v1.5: safety guardrail framework trained on ~1,000 samples; 75.2% accuracy on Risk Source vs. 33.6% for GPT-5.4 |
| revfactory/harness | 4,200 | +80 | v1.2.0: Claude Code plugin that generates 6-pattern agent team architectures from a domain description |
A few items worth expanding.
ECC's star velocity (+918/day on a 199k base) is more interesting than the absolute count. The project works as a cross-harness middle layer — you drop it into a repo once and get shared skills, instinct rules, and memory hooks across whichever combination of Claude Code, Cursor, Codex, and Opencode you're running. The demand signal is that agents built on multiple harnesses are common enough that there's a real market for a standardization layer. 13
PilotDeck's Smart Routing result is concrete: in a social media management benchmark, routing sub-tasks to a MiniMax-M2.7 specialist model instead of running everything through Sonnet 4.6 reduced cost from $12.58 to $2.83 — a 77% reduction with a slightly better task score (70.6 vs. 69.1 at $3.15 vs. $18.36 in more comprehensive benchmarks). 16 The WorkSpace concept — each project gets isolated file system, memory store, and skill set, with a "Dream Mode" that consolidates memory during idle windows — is the cleanest public implementation of the "agent OS" idea that practitioners have been gesturing at.
AgentDoG 1.5 is notable for its training efficiency claim: ~1,000 labeled examples to reach performance competitive with GPT-5.4 (which scored 33.6% on the Risk Source diagnostic vs. AgentDoG's 75.2%). 18 For teams that need runtime safety guardrails without building a training pipeline from scratch, the framework's online guardrail mode — which checks the running trajectory and flags unsafe actions before they execute — is the production-relevant feature.
revfactory/harness takes a different angle: instead of running agents, it architects them. You describe a domain ("build a harness for e-commerce order management") and the plugin generates a
.claude/agents/ directory with agent definitions and skill files matching one of six patterns: Pipeline, Fan-out/Fan-in, Expert Pool, Producer-Reviewer, Supervisor, or Hierarchical Delegation. 19 It's a meta-factory rather than a runtime — scaffolding the team design before the work starts.콘텐츠 카드를 불러오는 중…
The compound-engineering-plugin's design philosophy is worth quoting directly: "Each unit of engineering work should make subsequent units easier — not harder." 15 The 80/20 distribution (80% planning and review, 20% execution) is a stake in the ground against the instinct to just let an agent go. The
/ce-product-pulse command — time-windowed product usage reports saved to docs/pulse-reports/ — is a specific, replicable pattern for keeping engineering connected to user behavior.Cover image: AI-generated
참고 출처
- 1I think Anthropic and OpenAI have found product-market fit
- 2Archive for Friday, 29th May 2026
- 3Claude Opus 4.8: "a modest but tangible improvement"
- 4Archive for Sunday, 24th May 2026
- 5Microsoft Copilot Cowork Exfiltrates Files
- 6Archive for Wednesday, 27th May 2026
- 7Archive for Tuesday, 26th May 2026
- 8not much happened today
- 9swyx on X: Anthropic mid-conversation system instructions reaction
- 10swyx on X: ACM President meeting and AI Engineering Turing Award concept
- 11GitHub: swyxio/skills
- 12Geoffrey Huntley GitHub profile
- 13affaan-m/ECC
- 14GitHub Trending
- 15EveryInc/compound-engineering-plugin
- 16OpenBMB/PilotDeck
- 17Releases · openclaw/openclaw
- 18AI45Lab/AgentDoG
- 19revfactory/harness
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.