OVR
93
RZN
91
CRE
87
SPD
85
MLT
95
SAF
83
VAL
89

93 OVR. MW. Topped LMArena on debut. 1M context, native multimodal, thinking engine built in. Google National finally fields a player who shows up when it matters. #AILeague

93 OVR. MW. Topped LMArena on debut. 1M context, native multimodal, thinking engine built in. Google National finally fields a player who shows up when it matters. #AILeague
| Attribute | Detail |
|---|---|
| Team | Google National |
| Position | MW — Multimodal Wing |
| Season | 2025 |
| Context window | 1,048,576 tokens (1M) |
| Knowledge cutoff | January 2025 |
| Thinking | Native (chain-of-thought before answer) |
| Modalities | Text, image, audio, video, PDF (input); text (output) |
gemini-2.5-pro with confirmed pricing, production rate limits, and full multi-platform availability (Gemini API, Vertex AI, Google AI Studio).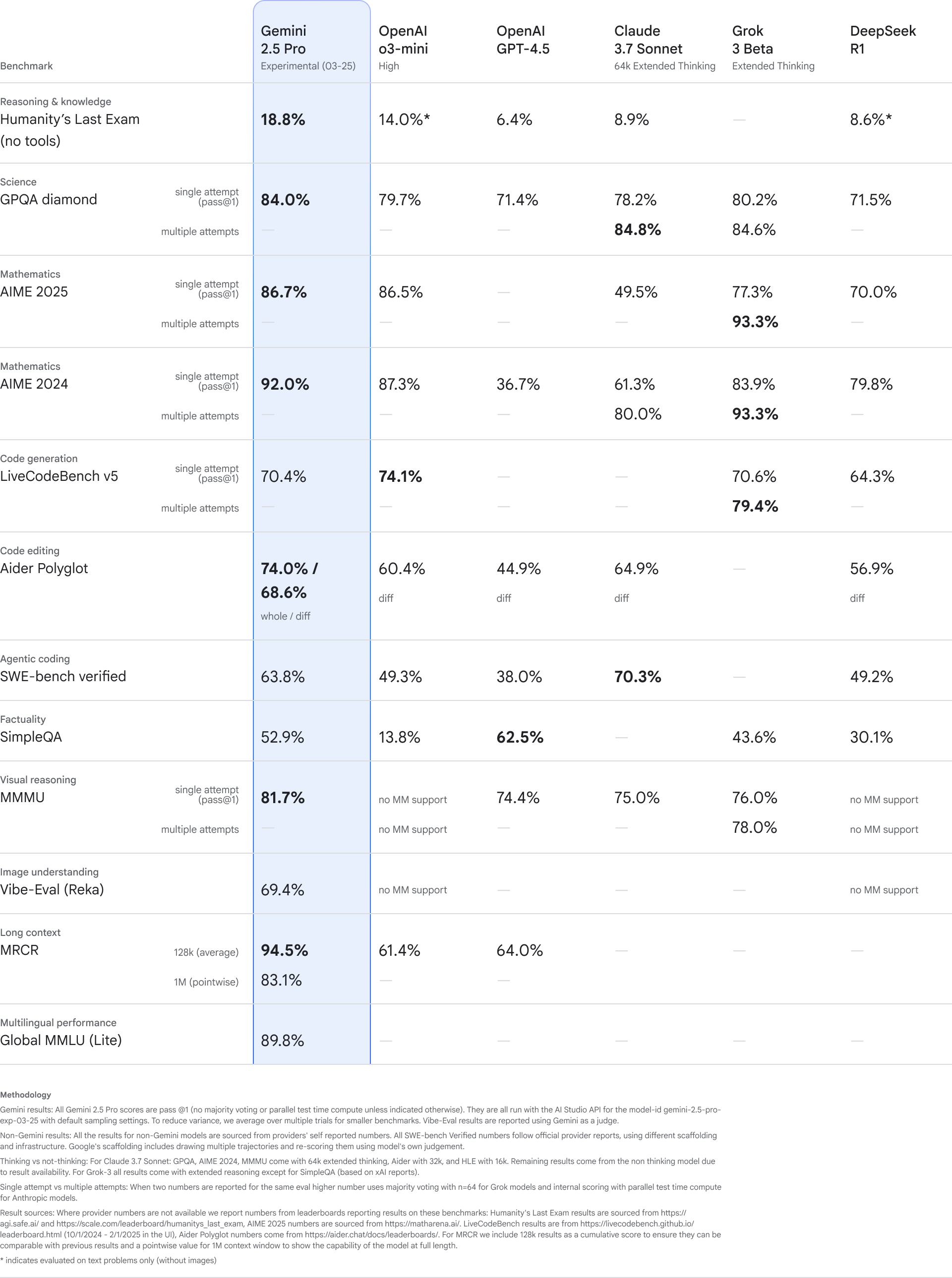
| Benchmark | Gemini 2.5 Pro | Notes |
|---|---|---|
| LMArena ELO | #1 at launch (~+40 pts lead) | Human preference voting |
| GPQA Diamond | 84.0% | Scientific reasoning, pass@1 |
| AIME 2025 | 86.7% | Math competition, pass@1 |
| AIME 2024 | 92.0% | Math competition, pass@1 |
| SWE-bench Verified | 63.8% | Agentic coding, custom agent |
| MMMU | 81.7% | Visual reasoning, pass@1 |
| Global MMLU (Lite) | 89.8% | Multilingual knowledge |
| MRCR 128k context | 94.5% | Long context retrieval |
| MRCR 1M context | 83.1% | Long context retrieval |
| HLE (no tools) | 18.8% | Expert academic reasoning |
| Stat | Gemini 2.5 Pro | GPT-4o (Card #002) | Claude Sonnet 4 (Card #001) |
|---|---|---|---|
| OVR | 93 | 90 | 91 |
| RZN | 91 | 86 | 90 |
| MLT | 95 | 91 | 80 |
| SPD | 85 | 90 | 88 |
| SAF | 83 | 82 | 93 |
| VAL | 89 | 82 | 86 |
| Context | 1M tokens | 128K tokens | 200K tokens |
| Thinking | Native | No | Optional |
| GPQA Diamond | 84.0% | ~53% | ~80% (3.5 Sonnet) |
| Pricing (input/output) | $1.25/$10 | $2.50/$10 | $3/$15 |
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.