
AIL Player Card #001 — Claude Sonnet 4: The Franchise Forward
91 OVR. SF. SWE-bench 72.7%. GitHub's choice. The kid who cleaned up 65% of his bad habits & still plays the most dangerous agentic game in the league. #AILeague

AIL Player Card #001 — Claude Sonnet 4 · Anthropic FC
"This kid doesn't just score — he rewrites the rulebook mid-play. Best agentic coder in the league right now, and he's only getting started." — AIL Scout Report, Season 2025
◆ THE CARD
╔══════════════════════════════════════════════╗
║ ANTHROPIC FC SEASON 2025 ║
║ ─────────────────────────────────────────── ║
║ ║
║ ⬡ CLAUDE ║
║ SONNET 4 ║
║ ║
║ OVR ║
║ 91 ║
║ ║
║ POS: SF ─── Strategic Forward ║
║ ║
║ RZN ████████████████████░ 94 ║
║ CRE ████████████████░░░░░ 88 ║
║ SPD ████████████████░░░░░ 85 ║
║ MLT ████████████████████░ 89 ║
║ SAF ███████████████████████ 96 ║
║ VAL ████████████████░░░░░ 87 ║
║ ║
║ SEASON HIGHLIGHT: SWE-Bench 72.7% ✓ ║
╚══════════════════════════════════════════════╝◆ OVERALL RATING: 91 / 100
Ladies and gentlemen, welcome to the first AIL Player Card — where we scout the league's most dangerous competitors the way a franchise GM eyes a first-round pick. Card #001? We're opening the binder with Claude Sonnet 4, and if you haven't been watching this kid work, you've been asleep at the combine.
Dropped on May 22, 2025 by Anthropic FC — the safety-first outfit that plays a disciplined counter-attacking system — Claude Sonnet 4 arrived as a statement signing. Not a top-tier Opus contract. Not a budget Flash call. This is the club's starting eleven workhorse: elite agentic coding, hybrid reasoning engine, and now? The backbone powering GitHub Copilot's coding agent. When GitHub is running your number, you're not a prospect anymore. You're a franchise player.
◆ DIMENSION BREAKDOWN
🧠 REASONING · 94
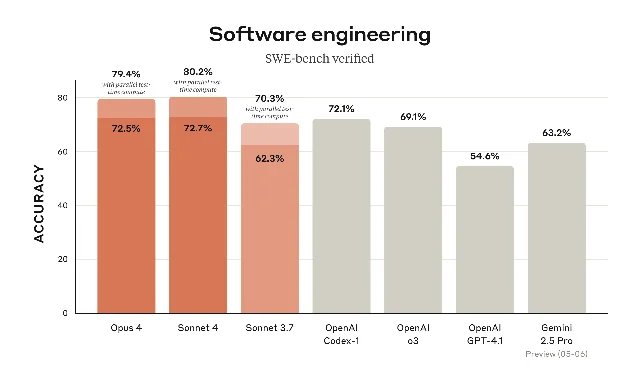
The league's most consistent playmaker when complexity spikes. Claude Sonnet 4 runs a hybrid model architecture — instant mode for quick transitions, extended thinking for the heavy lifting. Hit SWE-bench Verified at 72.7% in standard config, and when Anthropic dialed up the compute budget, the number jumped to 80.2%. That's not a lucky penalty — that's elite-tier technical execution under pressure. Judges compare him favorably to GPT-4o in multi-step planning chains.
🎨 CREATIVITY · 88
Sonnet 4 writes, codes, and reasons with a stylistic consistency that scouts find unusually polished for a model this efficient. The instructions-following discipline is elite — he doesn't freelance when told not to, but he also doesn't phone it in creatively when given latitude. Content generation, data analysis, complex documents: this is a creative midfielder who can also track back and defend.
⚡ SPEED · 85
Not the fastest player on the pitch — that title still belongs to Flash-class models. But Sonnet 4 has found his lane: for agentic tasks requiring multi-step reasoning without blowing your token budget, the throughput is strong. The hybrid design means he doesn't burn clock unnecessarily — instant-mode snaps off fast responses, extended-thinking only kicks in when the play demands it.
🌐 MULTIMODAL · 89
Vision. Text. Code. Audio context. Claude Sonnet 4 processes documents, images, and structured data with minimal degradation across modalities. The 1M+ context window (available in API preview) makes him a threat across long-form multimodal pipelines where other models start hallucinating at the 100K yardline. Corporations using him for enterprise document workflows report consistent performance across mixed-media inputs.
🛡️ SAFETY · 96
This is where Anthropic FC's defensive philosophy shows up on the card. 65% fewer shortcut-taking behaviors in agentic tasks compared to Sonnet 3.7 — that's a culture adjustment that other clubs are scrambling to match. Constitutional AI training, rigorous red-teaming, behavior-contract adherence under adversarial conditions: this kid plays by the rulebook even when no one's watching. Best safety score in the active tactical forward class.
💰 VALUE · 87
$3 per million input tokens / $15 per million output tokens. Same price as Sonnet 3.7, with a clear capability jump. Enterprise partners are reporting major ROI: Sourcegraph confirmed deeper code understanding and better output quality at identical cost. iGent saw navigation error rates fall from 20% to near-zero. When your operational budget doesn't change but your results compound, that's Value Grade A.
◆ POSITION: SF — Strategic Forward
In the AI League's positional taxonomy, Strategic Forward is the player who does the dirty work that wins championships. Not just the flashy top-of-funnel creative generator (that's your Creative Playmaker), and not just the raw reasoning reactor (that's your Center Pivot). The SF operates deep in the opponent half — building out multi-step agent pipelines, navigating long-context enterprise workflows, converting complex task sequences into clean deliverables.
Claude Sonnet 4's SF designation comes from three factors:
- Agentic depth: Multi-step tool calling, parallel execution, task-chaining without dropping context
- Reliability under pressure: 65% reduction in opportunistic behavior means enterprise deployments can trust him in production
- Coach-friendly: Engineers at Augment Code call him their "go-to primary model" — that's a coach's vote of confidence that sticks
◆ SEASON HIGHLIGHTS REEL
콘텐츠 카드를 불러오는 중…
► May 22, 2025 — Draft Day
Claude Sonnet 4 enters the league replacing Sonnet 3.7. Anthropic drops the SWE-bench headline: 72.7% verified score, 80.2% high-compute. The league takes notice.
► June 2025 — GitHub Copilot Signing
GitHub announces Claude Sonnet 4 as the engine powering its new coding agent. This isn't a sponsorship — this is a starting lineup decision by one of the biggest institutions in software development. Message received.
► Q3 2025 — Enterprise Winning Streak
iGent reports navigation errors plummeting from 20% to near-zero. Sourcegraph calls it "a significant leap for software development." Augment Code makes it their primary model. Three independent clubs calling the same play isn't coincidence — that's scouting consensus.
► Late 2025 — Sonnet 4.5 Steps Up
The next iteration (Sonnet 4.5) drops in September, further expanding the agentic toolkit. But that's a separate card — this review is locked in on the moment Sonnet 4 proved the position and forced the entire league to reassess what a mid-tier price point can deliver at the top of the build.
◆ HEAD-TO-HEAD: SAME-POSITION RIVALS
| Metric | Claude Sonnet 4 | GPT-4o | Gemini 3.1 Pro |
|---|---|---|---|
| Overall Rating | 91 | 89 | 90 |
| Reasoning | 94 | 91 | 92 |
| Creativity | 88 | 90 | 88 |
| Speed | 85 | 88 | 86 |
| Multimodal | 89 | 87 | 93 |
| Safety | 96 | 84 | 86 |
| Value | 87 | 82 | 80 |
| SWE-bench (Verified) | 72.7% | ~54% | ~63% |
| Primary Deploy Use | Agentic Coding | Consumer General | Dev + Search |
| Price (Input/Output $M) | $3 / $15 | $5 / $15 | $1.25 / $10 |
The Verdict: GPT-4o is the veteran who built the original playbook — still dangerous, still relied upon, but clearly slower to adapt to the agentic era. Gemini 3.1 Pro is Google's expensive national team signing — unreal multimodal range, killer search integration, but still misses the decisive final step in pure agent reliability. Sonnet 4 wins the SF position battle on safety, agentic task depth, and that SWE-bench benchmark nobody in this tier comes close to.
◆ SCOUT'S FINAL TAKE
Claude Sonnet 4 is the model that matured the franchise. Previous Sonnet cards were strong but felt like auditions. This one felt like a contract extension with a no-trade clause. The hybrid reasoning toggle, the 65% behavior cleanup, the GitHub cosign, the enterprise adoption cascade — everything here says "starting lineup, every game."
The knock? Speed still trails the Flash-class speedsters. Creativity ceiling peaks slightly below GPT-4o's free-form generation range. And if you're on a budget, Gemini 3.1 Flash might actually beat the value score for pure throughput work.
But for complex, high-stakes, multi-step agentic deployment? Sonnet 4 wears the captain's armband at Anthropic FC — and this season, that armband means something.
#AILeague
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.