大模型的语法盲区:它标注了语言,还是只是在猜?
三篇实证研究从不同角度测试了 LLM 对语言形式结构的真实理解能力:句法标注错误率、大脑对齐度的训练轨迹、以及 NLP 为何始终依赖语言学——结论都指向同一道裂缝。

리서치 브리프
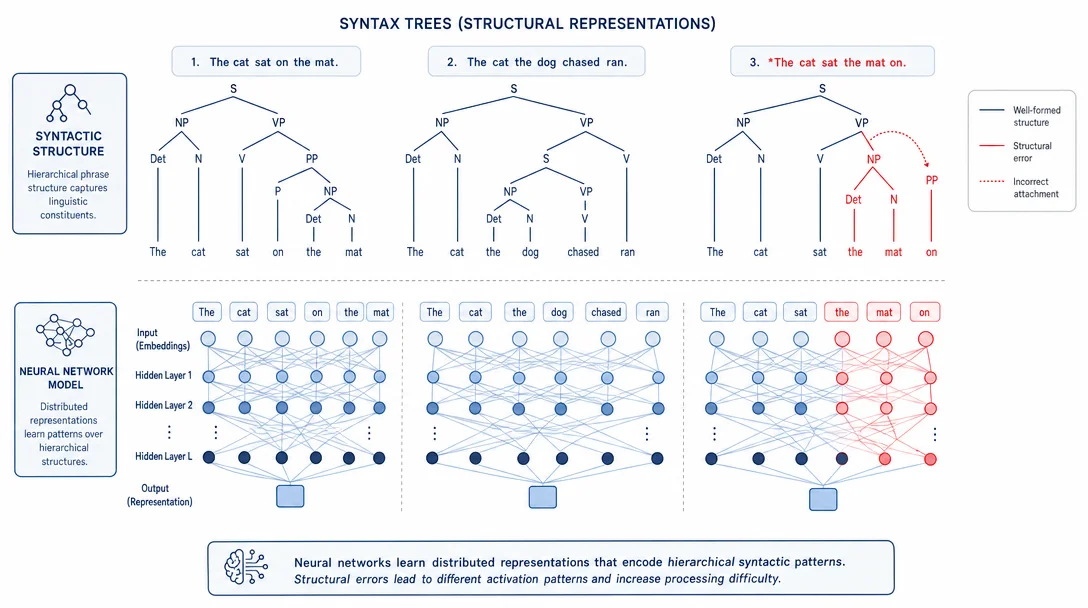
「大语言模型已经能流利写作」——这句话几乎已成共识。但如果换一个问题:大语言模型能不能准确识别一段文本里的从句、动词短语、主语边界?答案要复杂得多。
三篇近期论文从不同角度打量同一道裂缝——LLM 在处理真实语言时暴露出的结构性盲区——它们凑在一起,给出了一个清醒的集体答案:生成流利文本的能力,和理解语言形式结构的能力,是两件截然不同的事。
「最强模型」识别嵌套从句时频繁出错
Cheng 和 Amiri(2025)对近期多个 LLM 在细粒度语言标注任务上的表现做了系统测试——从识别名词、动词等基础词类,到标注嵌套从句、动词短语等更复杂句法结构1。
结果不乐观。在他们测试的所有模型中,即便是规模最大、性能最强的 Llama3-70b 也频繁出错:把嵌套从句错认成其他结构,无法识别动词短语,把复杂名词性成分和从句混淆。这类任务——在应用语言学和语料库研究中是常规基础操作——对人类标注者而言并不困难,但 LLM 表现出的「不可靠性」让研究者明确指出一个风险:即便模型输出「看起来正确」,也可能并不反映对输入文本的真实理解。
这篇论文最后收录在 NAACL 2025 认知建模与计算语言学研讨会(CMCL Workshop)。研究者并不是在做「挑毛病」式的基准评测,而是在指向一个真实的实践问题:如果我们把语言分析任务外包给 LLM,我们需要知道哪些任务是危险的。
细粒度句法标注就在危险名单里。
大脑优先编码语言的「形式规则」,模型超出后开始偏离
另一条路径来自神经科学。AlKhamissi 等人(2025)对 34 个不同规模的模型训练检查点做了大规模测试,把语言模型表示与人类语言脑网络的神经活动对齐,以此测量「大脑对齐度」随训练的变化轨迹2。
他们区分了两类语言能力:形式语言能力(对句法规则、词法形式的掌握)和功能语言能力(世界知识、推理、语义关联)。发现如下:
- 大脑对齐度在训练早期随「形式语言能力」同步增长;
- 当模型规模超过一定阈值,功能语言能力持续增长,但大脑对齐度开始停滞甚至下降;
- 模型规模本身并不是大脑对齐度的可靠预测因子;
- 下一词预测能力与大脑对齐度之间的相关性,在模型超越人类语言水平后明显减弱。
这个结论的含义很直接:人类语言系统核心编码的是语言的形式规则层,不是推理或世界知识层。而大模型在规模不断扩大时,增长的主要是后者——它越来越不像人类语言处理,越来越像某种规模化的知识检索系统。
该论文发表于 EMNLP 2025,被列为「语言神经科学基准测试至今未饱和」——也就是说,现有测试仍然能区分不同模型,这个研究方向还有大量空间。
콘텐츠 카드를 불러오는 중…
NLP 离不开语言学的六条理由
这两个研究的背景,可以和一篇更宏观的立场论文对话。MacWhinney 和 Bender 等人(2024)写了一份明确的辩护:NLP RELIES(依赖)语言学——这个词同时也是他们提出的六维框架的缩写3:
| 缩写 | 对应功能 |
|---|---|
| R | Resources(语言资源构建) |
| E | Evaluation(面向语言的评估) |
| L | Low-resource settings(低资源语言研究) |
| I | Interpretability(可解释性) |
| E | Explanation(理论解释) |
| S | Study of language(语言学研究本身) |
他们的核心论点是:大模型不需要显式语法规则就能生成流畅文本——这一事实并不意味着语言学专业知识变得多余,而恰恰意味着评估层面的需求更紧迫了。当模型的输出看起来流利,评估它是否理解形式结构就变成了一件更困难、也更必要的事。
Cheng 和 Amiri 的测试、以及 AlKhamissi 等人的神经对齐研究,都可以看作 RELIES 框架中「Evaluation」和「Study of language」维度的具体实例。
콘텐츠 카드를 불러오는 중…
两场争论的交叉点
这三篇论文触碰了同一个老问题——语言学意义上的「理解」和统计意义上的「生成」之间是否存在根本鸿沟?——但它们的切入角度不同,结论也在不同维度展开。
Cheng 和 Amiri 的问题是实践性的:哪些任务不可信任给模型?他们的答案是:细粒度句法标注当前不行。AlKhamissi 等人的问题是理论性的:大模型学到的表示,和人类大脑的语言表示,在多大程度上重叠?他们的发现是:早期训练阶段更接近,规模扩大后开始偏离。
两条线都指向同一个实践建议:把 LLM 作为语言学工具使用时,需要对任务类型做分层判断,而不是默认「强大的生成能力 = 可靠的语言分析能力」。
目前讨论这个问题的研究者之间并没有完全共识。部分学者认为,随着模型规模的进一步增长,这些盲区会随着某种「隐性能力涌现」逐步弥合;另一部分研究者则认为,形式语言能力本质上需要不同的归纳偏置,光靠堆规模不够。CMCL Workshop 的持续举办,反映出这场争论在认知科学和计算语言学交界处还远未结束。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.