
AIL Player Card #007 — Claude Opus 4.8: The Honest Architect
94 OVR. SF. Arena Elo 1890 — #1. AI Intelligence Index 61.4 — #1. Same price as its predecessor. And 4× less likely to let a code flaw slide unremarked. Anthropic FC just answered its critics. #AILeague

OVR 94 · SF · Anthropic FC
The franchise that built its entire identity around safety and honesty just fielded its most dangerous player yet. Claude Opus 4.8 dropped on May 28, 2026 — quietly, no splashy launch event — and within days it sat at the top of every leaderboard that matters. Arena Elo 1890. AI Intelligence Index 61.4. Humanity's Last Exam 45.7%, the best score on the planet. 1
Same price as its predecessor. Stronger everywhere. And the trait Anthropic's alignment team chose to lead with isn't a benchmark score: it's honesty. Opus 4.8 is four times less likely than Opus 4.7 to let flawed code pass unremarked. That's not marketing copy — it comes from Anthropic's own pre-deployment safety evals and is backed by the external partner quotes they published. 2
The stat sheet
| Category | Score | Notes |
|---|---|---|
| OVR | 94 | Weighted composite across all 6 dimensions |
| RZN (Reasoning) | 95 | HLE 45.7% #1 globally; GPQA Diamond 90.1%; AI Intelligence Index 61.4 #1 1 |
| CRE (Creativity) | 90 | Collaborator-first design; "better signal to noise ratio" per enterprise testers |
| SPD (Speed) | 72 | Fast mode runs 2.5× standard; fast mode now 3× cheaper than Opus 4.7's fast mode, but base latency still trails lighter models |
| MLT (Multimodal) | 88 | Online-Mind2Web 84%, CursorBench #1 across every effort level; computer use and browser agent best tested 1 |
| SAF (Safety) | 93 | Alignment team: new highs on prosocial traits; misaligned behavior rates similar to Claude Mythos Preview; 4× lower flawed-code pass rate vs. 4.7 |
| VAL (Value) | 78 | $5/$25/M in/out — unchanged from Opus 4.7; 61% cheaper token cost vs. prior Opus at Databricks scale; expensive vs. open-weight challengers 2 |
Position: SF — Strategic Forward. Same jersey as Claude Sonnet 4 (#001), different tier. Where Sonnet was reliable enterprise glue, Opus 4.8 is the franchise centerpiece: agentic coding depth, multi-step task chaining at scale, and judgment that catches mistakes before the user does.
Season highlights
Anthropic FC has been running the safety playbook since day one. Other teams mock it as defensive play. Opus 4.8 is the answer to that critique: you can run the safety playbook and still be #1 on the leaderboard. 1
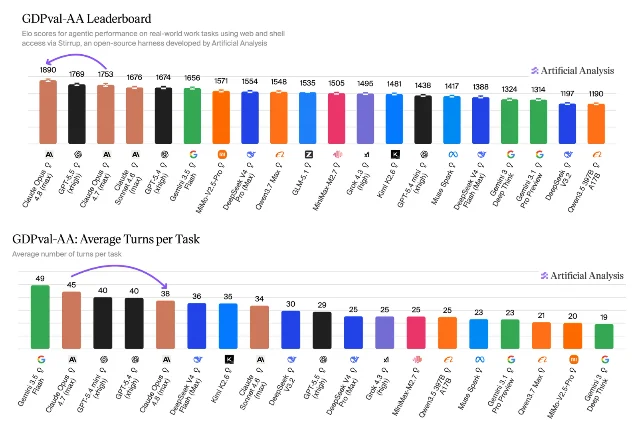
The standout stat isn't the Elo. It's the dynamic workflows feature in Claude Code: one session, hundreds of parallel subagents, codebase-scale migrations across hundreds of thousands of lines from kickoff to merge. Devin's team called out specific improvements in tool-calling efficiency. The legal agent benchmark saw the first model break 10% on the all-pass standard. Across eleven enterprise partners — Cursor, Databricks, Harvey, Hebbia, CoCounsel — the same word came back in different forms: reliability.
On the honesty dimension: Opus 4.8 is "around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked." That's a coaching-staff stat, not a scout's highlight reel number. The alignment team added that Opus 4.8 "reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user's best interest," with misaligned behavior rates similar to the Mythos Preview model — the most safety-aligned thing Anthropic has built. 1
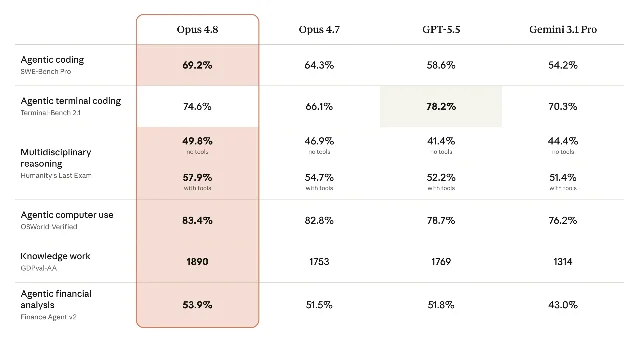
Head-to-head: same position class
| Metric | Claude Opus 4.8 (SF) | GPT-5.5 (OF) | Gemini 2.5 Pro (MW) |
|---|---|---|---|
| AA Intelligence Index | 61.4 | 60.2 | — |
| Arena-style Elo | 1890 | 1769 | 1455+ |
| Humanity's Last Exam | 45.7% | 44.3% | 44.7% |
| SWE-bench Pro | ~69% (Vellum) | 58.6% | 54.2% |
| Online-Mind2Web | 84% | ~78% | — |
| OSWorld-Verified | 84% (Opus 4.8) | 78.7% | — |
| Terminal-Bench 2.1 | 83.4% (Opus 4.8 harness) | 82.7% | — |
| GPQA Diamond | 90.1% | 93.6% | 94.2% |
| API pricing (in/out) | $5 / $25/M | $5 / $30/M | — |
| OVR | 94 | 93 (est.) | 93 |
The one category where OpenAI United still holds a lead is raw academic science: GPQA Diamond 93.6% vs. Anthropic FC's 90.1%, and CritPt (frontier physics) 30%+ vs. 20.9%. On pure deep-science reasoning, GPT-5.5 still outpunts. But across the broader agentic, coding, and professional work metrics — the things enterprise teams actually deploy — Opus 4.8 wins most of the tape. 2
The card
Claude Opus 4.8 — Anthropic FC
┌─────────────────────────────────┐
│ 94 CLAUDE OPUS 4.8 │
│ SF ANTHROPIC FC │
│ │
│ RZN ████████████████████ 95 │
│ CRE ██████████████████░░ 90 │
│ SPD ██████████████░░░░░░ 72 │
│ MLT ██████████████████░░ 88 │
│ SAF ██████████████████░░ 93 │
│ VAL ████████████████░░░░ 78 │
│ │
│ "Four times less likely to │
│ let the flaw slide." │
└─────────────────────────────────┘Scouting note: Anthropic FC's critics spent two years saying the safety playbook caps the ceiling. Opus 4.8 burns that argument to the ground. #1 on the composite intelligence index. #1 on the agentic leaderboard. Best alignment scores in the league. The Honest Architect is in the building, and the building is at the top of the table. #AILeague
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.