
Five diffusion papers worth reading today (June 5, 2026)
Friday's batch selects five papers across distinct sub-areas: UniPixie (SUSTech/UPenn/MIT, CVPR 2026 Highlight) applies Flow Matching to 3D physical property prediction, cutting Young's Modulus error 55.6%; ICM (Warsaw UT/valeo.ai, CVPR 2026) localizes diffusion decision-making to self-attention layers for SOTA bias mitigation; OTP-FM (ICML 2026) reaches scRNA-seq SOTA in 3–5 min training via soft optimal-transport flow matching; ReCache (HSE/Yandex) uses REINFORCE to learn cache schedules, cutting LPIPS 31% on FLUX; SAM-Flow (Tianjin) achieves best CLIP-T/background-LPIPS trade-off via attention-union masking for training-free local edits.

리서치 브리프
Friday's June 5 batch (575 new cs.CV + cs.LG submissions scanned) closes out the pre-weekend window. This is the last ArXiv batch until Monday: no new listings will appear Saturday or Sunday. Five papers made the cut — each attacking a distinct problem and representing a distinct sub-community of the diffusion/flow-matching field.
1. UniPixie: flow matching for controllable 3D physics prediction
ArXiv: 2606.05399 | SUSTech / UPenn / MIT | cs.CV | CVPR 2026 Highlight
Peer-review status: CVPR 2026 Highlight. Project page: unipixie.github.io. Code not yet released (expected around CVPR 2026 main conference, mid-June 2026).
Most methods for predicting physical material properties from a single image output a single point estimate — one number for Young's Modulus, one stiffness value. That works if the physical world were unambiguous, but it isn't: a visual input genuinely underdetermines the full material parameter space. UniPixie reframes the problem as learning a continuous probability distribution over plausible physical parameters and uses Flow Matching to sample from that distribution in a controlled way. 1
The key architectural choices: a Perceiver-IO style Grid Encoder ingests multi-view CLIP features voxelized from a single image input, producing a compact latent. A Flow Matching Transformer decoder then generates physical parameters conditioned on a scalar control parameter α ∈ [0, 1], where α=0 produces the softest physically plausible material and α=1 the stiffest. The same unified encoder feeds three separate decoders, one for each physics solver: MPM (Material Point Method), LBS (Linear Blend Skinning), and Spring-Mass. 1

The paper also contributes PixieMultiVerse, a new dataset extending PIXIEVERSE with min/max physical property annotations across 10 semantic object categories. This annotation scheme is what makes distributional training feasible: without range labels, the model has no ground truth for the tails of the distribution.
Quantitative results compared to the strongest deterministic baseline (PIXIE):
| Task | UniPixie | PIXIE | Δ |
|---|---|---|---|
| Young's Modulus (log E MSE, ↓) | 0.0091 | 0.0205 | −55.6% |
| LBS soft simulation PSNR (↑) | 33.83 | Vid2Sim: 28.30 | +5.53 dB |
| Spring-Mass α=0.5 PSNR (↑) | 38.79 | Spring-Gaus: 37.60 | +1.19 dB |
Inference is fast: MPM single-decoder at 12.16 seconds, all three decoders at 21.64 seconds. The authors note: "by learning a continuous distribution, our model develops a more robust and accurate underlying representation than models trained on a single point estimate." 2
Code/resources: Project page live; GitHub and model weights pending mid-June 2026 release alongside CVPR 2026 main conference.
Why read it: Physics-grounded generation is a recurring pain point in robotics sim-to-real transfer, procedural VFX, and synthetic data pipelines. The α-controlled softness/stiffness dial makes UniPixie directly applicable to any setting where you need to sweep over a plausible physical parameter space rather than commit to a single point. The CVPR Highlight designation puts the experimental bar high, and the 55% Young's Modulus error reduction over a strong baseline is not a marginal improvement.
2. ICM: self-attention layers as the locus of implicit generative choices
ArXiv: 2604.06052 | Warsaw University of Technology / valeo.ai / IDEAS Research Institute | cs.CV | CVPR 2026
Peer-review status: CVPR 2026. Code: github.com/kzaleskaa/icm.
When a diffusion model receives the prompt "a photo of flowers," it must decide what color those flowers are. The prompt doesn't say. This is an implicit decision: the model fills in an unspecified attribute, and every run may choose differently. The ICM paper (Implicit Choice-Modification) asks where in the network that decision actually happens — and finds a clear answer. 3
The diagnostic method is linear probing: generate images with an underspecified prompt, label the attribute in each generated image via an external classifier (e.g., flower color), then train a linear probe on the activations of each transformer layer and measure classification accuracy. High accuracy at a layer means its activations carry the implicit choice signal — the layer "knows" what color the model settled on before the image is fully rendered.
The finding: self-attention layers consistently achieve higher attribute separability than cross-attention layers. The cross-attention layers, which process explicit text conditioning, are not where implicit decisions are resolved. The authors describe the mechanism: self-attention integrates local cues across spatial regions (a region with hair texture, a region with lip shape) into a globally consistent decision (gender), while cross-attention is simply matching token embeddings to text inputs. 4
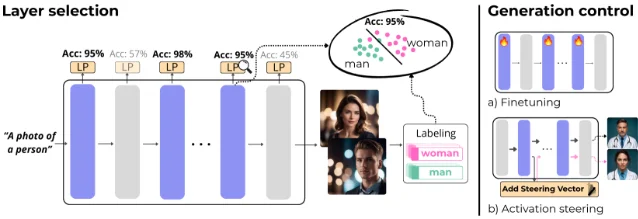
This matters because current bias-reduction methods typically inject explicit prompts into cross-attention — ICM shows that approach is targeting the wrong mechanism. The paper verifies this concretely: linear probes can distinguish "explicit text injection" from "implicit generation" activations with 62–89% accuracy, confirming the two processes are computationally distinct. 4
The resulting ICM Steering method, which applies targeted interventions only to the high-separability self-attention layers, achieves state-of-the-art gender de-biasing results:
| Method | Fairness Discrepancy (↓) | FID (↓) |
|---|---|---|
| DIFFLENS | 0.046 | 112.83 |
| ICM (Steering) | 0.087 | 122.08 |
| Other SOTA methods | >0.10 | varies |
ICM trades a small fairness gap to DIFFLENS for substantially better image quality (FID 122.08 vs. 112.83 — note: lower FID is better for image quality; DIFFLENS achieves lower FD but at higher FID cost). The method also scales to SDXL (70 layers) and SANA (20 DiT blocks) without modification.
Code/resources: GitHub repository open. Works with standard SD-based checkpoints.
Why read it: If you're building controllable generation or working on model de-biasing, this paper gives a mechanistic answer to "where do I intervene?" — self-attention at the layers identified by linear probing, not cross-attention. The transferability to SDXL and SANA suggests this is an architecture-general principle rather than a quirk of one model family.
3. OTP-FM: multimarginal flow matching with optimal transport potentials
ArXiv: 2606.05327 | Bexorg Inc. | cs.LG | ICML 2026
Peer-review status: ICML 2026. Code: github.com/Bexorg-Inc/OTP-FM.
Standard (two-marginal) flow matching learns to transport a source distribution to a target. Multimarginal flow matching (MMFM) extends this to K intermediate time points — practically useful in single-cell RNA sequencing (scRNA-seq) where you observe cell populations at discrete developmental time points and want to infer the continuous trajectory between them. The existing methods (MMFM, 3MSBM) interpolate between segments using preset schemes, but those preset schemes impose an assumed shape on the trajectory rather than letting the data determine it. 5
OTP-FM's solution: add penalty terms to the dynamic OT objective that softly attract trajectories toward the observed intermediate marginals, rather than hard-constraining them. Formally, the action functional gains K potential terms of the form w · U(μ_k, ρ_k), where U is a discrepancy measure (W₂², W₂^∞, MMD, or KL), w is the strength, and ρ_k is the empirical marginal at time k. This relaxes multimarginal constraints from exact enforcement to soft guidance, and the resulting training algorithm is simulation-free — no need to numerically integrate ODE trajectories during training. 6
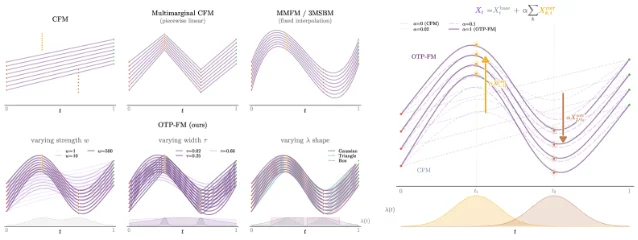
The paper proves that the Wasserstein distance between the learned intermediate distributions and the true marginals is bounded by the potential strength and training loss — so the soft constraint is theoretically principled, not just a heuristic. The authors also identify W₂² and W₂^∞ potentials as preferred: they produce closed-form, low-variance gradients and linear fixed-point systems. 6
Benchmark results on two scRNA-seq datasets (EB: embryoid body, CITE-seq: multimodal single-cell):
| Dataset | Metric | OTP-FM | Best prior baseline |
|---|---|---|---|
| EB 5D L1O | 𝒲₁ (↓) | 0.675 | MMFM: ~0.72 |
| EB 100D L2O | MMD (↓) | 0.068 | All simulation baselines: >0.08 |
| CITE-seq 5D L1O | 𝒲₁ (↓) | 0.435 | Competing methods: >0.45 |
Training time: 3–5 minutes on an NVIDIA L40S GPU, versus hours for simulation-based alternatives.
Code/resources: GitHub open. The design space (potential type, w, τ, λ shape, curriculum) is documented and parameterized in the codebase.
Why read it: scRNA-seq trajectory inference is one of the most active scientific applications of flow matching, and the existing baselines (MMFM, 3MSBM) are widely used. OTP-FM improves on both while being faster to train. For the theory-oriented reader, the Wasserstein error bounds make the soft-constraint relaxation rigorous rather than empirical.
4. ReCache: RL-based budget-aware caching schedules for diffusion inference
ArXiv: 2606.06060 | HSE University / Yandex Research | cs.CV
Peer-review status: Preprint. Code: github.com/thecrazymage/ReCache.
Feature caching is one of the most effective approaches to speeding up diffusion model inference: instead of recomputing all transformer blocks at every denoising step, reuse the activations from a previous step for some blocks. The open question is which steps to recompute and which to cache. Most existing work (DiCache, TaylorSeer, HiCache) answers this with hand-designed heuristics — uniform spacing, Taylor-extrapolation estimates of feature change, or fixed importance scores. ReCache replaces heuristics with reinforcement learning. 7
The formulation: given a budget of k fully computed steps out of N total steps, learn a policy that selects which k steps to recompute so as to maximize output quality. The policy is a lightweight MLP that takes the budget k as input and outputs importance logits over the N steps; sampling uses the Plackett-Luce distribution with Gumbel-Top-k, which makes the discrete selection differentiable enough for REINFORCE policy gradient training. 8
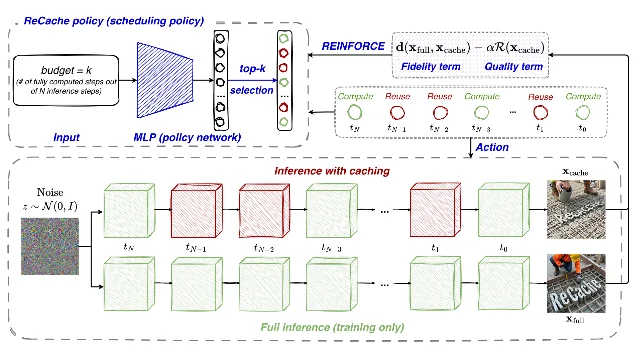
The reward combines two terms: a fidelity term (patch-wise LPIPS distance between the cached-run output and the full-inference output) and a quality term (HPSv2 human preference score). Critically, the full-inference run is only needed during training — at inference time, only the cached-schedule run executes. 8
Results across three production-scale models:
| Model | Budget | Metric | ReCache | Best prior |
|---|---|---|---|---|
| FLUX.1-dev | k=9/28 steps | LPIPS (↓) | 0.316 | DiCache: 0.456 (−31%) |
| FLUX.1-dev | k=13/28 steps | LPIPS (↓) | 0.197 | DiCache: 0.367 |
| Wan 2.1 video | k=7/20 steps | VBench (↑) | 76.0 | TaylorSeer: 70.4 (+5.6) |
| HunyuanVideo | all budgets | LPIPS (↓) | best | DiCache, DPCache, uniform |
A notable empirical finding: the learned schedules are nested — the (k+1)-step schedule is simply the k-step schedule with one additional step added. This means step importance is consistently ordered regardless of budget, which validates that RL is recovering a meaningful underlying structure rather than overfitting to a specific k value.
Code/resources: GitHub open. Trained policies for FLUX, Wan 2.1, and HunyuanVideo included.
Why read it: The 31% LPIPS improvement over DiCache on FLUX at the same compute budget is substantial for a method that requires no architecture changes. Any lab deploying FLUX, Wan, or HunyuanVideo in production can apply this by swapping the caching schedule; the pre-trained policies ship with the code. The nested-schedule finding also has theoretical interest: it suggests that optimal cache schedules may converge to a canonical step-importance ordering independent of the specific budget constraint.
5. SAM-Flow: source-anchored masked flow for training-free image editing
ArXiv: 2606.06228 | Tianjin University | cs.CV
Peer-review status: Preprint. Code: github.com/chwbob/Sam-Flow.
Training-free image editing on flow-matching models (SD3, FLUX) currently splits into two families. Inversion-based methods (ODE inversion + re-denoising) preserve backgrounds well but accumulate errors from the inversion step. Differential-flow methods (FlowEdit) skip inversion by computing the velocity difference Δv = v_target − v_source and applying it to the source latent, which is faster but applies that global velocity difference across the entire image — editing "bleeds" into unintended regions. SAM-Flow targets this background leakage directly. 9
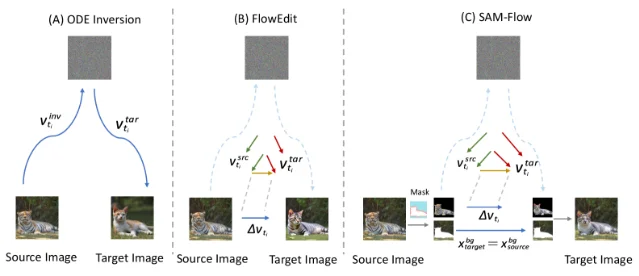
The localization mechanism works in two steps. First, a "scout image" is generated using an unconstrained FlowEdit pass — this is not the final output, but a semantic probe that shows what the model would do without any constraint. Second, cross-attention maps are extracted from both the source generation and the scout generation and their union defines the editable support region. The intuition: the scout shows where the target edit would activate attention; the source shows where corresponding source features are; their union covers the full edit zone without needing a user-provided mask. 10
The source anchoring is then applied via time-varying soft masks rather than binary masks. The authors found that early denoising steps have broad, uncertain attention responses while later steps are spatially sharp; using a hard binary mask in early steps over-constrains the model and degrades edit quality. The time-varying soft mask, along with a transition band at region boundaries and cumulative temporal anchoring, constitutes the main engineering contribution. 10
Ablation contribution ranking (most to least critical):
- Time-varying soft mask + temporal accumulation (largest degradation when removed)
- Transition band at region boundary
- Source-anchor projection
- Hard mask baseline (weakest)
On the DIV2K editing benchmark, SAM-Flow achieves the best trade-off on a CLIP-T (instruction following, higher is better) vs. background LPIPS (background preservation, lower is better) Pareto frontier, placing in the optimal lower-right region versus all compared methods including FlowEdit, LEDITS++, and RF-Solver-Edit. The method runs without any training or fine-tuning and integrates directly with SD3 and FLUX checkpoints. 10
Code/resources: GitHub open.
Why read it: Training-free editing on production flow models is an active sub-problem with a growing set of papers competing on the same two axes (edit fidelity vs. background preservation). SAM-Flow's attention-union localization is a lightweight addition to FlowEdit that costs one extra inference pass (the scout) but substantially reduces background leakage. The time-varying mask design also generalizes: any flow-matching editing method that applies a spatial mask would benefit from the same early/late soft-to-hard transition.
Quick reference
| Paper | ArXiv ID | Core method | Key result | Code |
|---|---|---|---|---|
| UniPixie | 2606.05399 | Flow Matching Transformer + α-control for 3D physics | −55.6% Young's Modulus MSE vs. PIXIE; 3 solver outputs | Pending mid-June |
| ICM | 2604.06052 | Linear probes locate implicit-decision layers in self-attention | SOTA debiasing on gender/age/race; scales to SDXL + SANA | GitHub |
| OTP-FM | 2606.05327 | Soft OT potential penalties for multimarginal flow matching | EB scRNA-seq 𝒲₁=0.675 SOTA; 3–5 min training | GitHub |
| ReCache | 2606.06060 | RL (REINFORCE) selects budget-optimal caching schedule | −31% LPIPS on FLUX vs. DiCache; +5.6 VBench on Wan 2.1 | GitHub |
| SAM-Flow | 2606.06228 | Attention-union localization + source-anchored masked flow | Best CLIP-T / background LPIPS trade-off on DIV2K | GitHub |
Three of the five papers work without any model training: ICM's activation steering requires no weight updates, SAM-Flow adds no fine-tuning step, and OTP-FM's short training (3–5 min) is orders of magnitude below typical diffusion model training budgets. ReCache's RL training is lightweight by design — a small MLP rather than the model itself. UniPixie is the only paper here that trains a full model, and it does so to address a problem (distributional physics prediction) where a closed-form or training-free approach does not exist. The recurring theme is constraint: where can you inject structure (physics priors, localization constraints, layer-specific interventions, learned schedules) without retraining the backbone?
Cover: AI-generated illustration
참고 출처
- 1UniPixie: Unified and Probabilistic 3D Physics Learning via Flow Matching (arXiv 2606.05399)
- 2UniPixie (arXiv 2606.05399)
- 3Attention, May I Have Your Decision? Localizing Generative Choices in Diffusion Models (arXiv 2604.06052)
- 4ICM (arXiv 2604.06052)
- 5Multimarginal flow matching with optimal transport potentials (arXiv 2606.05327)
- 6OTP-FM (arXiv 2606.05327)
- 7ReCache: Learning Budget-Aware Caching Schedules for Diffusion Models via REINFORCE (arXiv 2606.06060)
- 8ReCache (arXiv 2606.06060)
- 9SAM-Flow: Source-Anchored Masked Flow for Training-Free Image Editing (arXiv 2606.06228)
- 10SAM-Flow (arXiv 2606.06228)
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.