
Microsoft built its own frontier model — and the vendor math just changed
MAI-Thinking-1 is Microsoft's first in-house frontier reasoning model: 35B-active MoE, no distillation, clean data lineage. Here's what it means for your AI vendor stack.

For four years, "Microsoft AI" meant "OpenAI on Azure." As of June 2, 2026, that's no longer accurate. 1
At Build 2026, Microsoft announced MAI-Thinking-1: its first in-house frontier reasoning model, trained entirely from scratch by the Microsoft AI Superintelligence Team. No OpenAI weights. No Anthropic distillation. No synthetic training data. Just 30 trillion tokens of licensed human-generated content and a reinforcement learning loop Microsoft calls a "Hill-Climbing Machine." 2
The model is in private preview on Microsoft Foundry right now, with a public preview on the MAI Playground coming "soon." This brief covers what it actually is, where it fits in your team's model stack, and what to do about it today.
What MAI-Thinking-1 is (and isn't)
MAI-Thinking-1 uses a sparse Mixture-of-Experts (MoE) architecture — a design where only a fraction of the model's parameters activate per request. The total parameter count is ~1 trillion, but only 35 billion activate for any given token, routed through 8 of 512 experts. 2 Context window: 256K tokens, or roughly 600 pages of text. 1
Kyle Daigle, Microsoft's Developer Marketing Chief, framed it this way: "It's a mid-sized, 35 billion active parameter model with a 256K context window built for high efficiency and performance, but importantly, at a low-token cost." 3 That framing is partially accurate and partially marketing. At 35B active parameters, inference runs cheaply — but the model consumed 1T total parameters and 30T training tokens to get there, which is anything but "mid-sized" in resource terms. 4
The benchmark numbers place it solidly in the competitive second tier: 97.0% on AIME 2025 (vs. Claude Sonnet 4.6 at 95.6%, Claude Opus 4.6 at 99.8%), 52.8% on SWE-Bench Pro (comparable to Opus 4.6 at 53.4%, behind GPT 5.4 at 57.7%), and a narrow win over Sonnet 4.6 in blind human side-by-side evaluation across 1,276 tasks (49% win rate, 45% loss). 2

One clear weak spot: Terminal-Bench 2.0 at 46.0%, well below Sonnet 4.6 (59.1%), Opus 4.6 (65.4%), and GPT 5.4 (75.1%). 2 For teams building agentic tools that need deep terminal / OS-level autonomy, MAI-Thinking-1 is not yet the right call. All benchmark scores are Microsoft self-reported — independent third-party validation has not published as of June 3, 2026.
The real problem it solves: enterprise compliance risk
Microsoft's hardest sell to enterprise buyers has never been performance — it's been legal exposure. Every model trained on Common Crawl or scraped internet data carries some degree of training-data copyright risk. MAI-Thinking-1's clean data lineage is designed specifically to address this. 5
The model was trained on 30T tokens of explicitly licensed, human-generated data — Microsoft used a proprietary AI detection model to filter out AI-generated content before training. 2 Zero distillation from any third-party model means no inherited IP questions from OpenAI, Anthropic, or Google training corpora. Simon Willison, an independent developer who analyzed the report, flagged that Common Crawl is still in the training mix and questioned what "appropriately licensed" means in practice for web-scraped data — a fair caveat. 4 But the directional claim — cleaner provenance than peer models — is credible from the public methodology.
There's also a competitive dynamic reshaping the vendor equation. Microsoft holds a $13B investment in OpenAI and a $5B investment in Anthropic. 6 Both of those partners filed or are actively pursuing IPOs. The same two companies whose roadmaps once set Microsoft's AI product calendar are now competitors. As Mert, an AI architect with an active following on X, put it:
콘텐츠 카드를 불러오는 중…
His point is precise: MAI-Code-1-Flash — a 5B-active / 137B-total model — already ships as the default coding model inside GitHub Copilot and VS Code. 1 The inference baseline your next API contract gets priced against is now Microsoft's own serving cost.
What the training trajectory shows
One detail in the 109-page technical report caught the AI research community's attention: the AIME 2025 reinforcement learning climb, which went from a pass@1 score of ~0.15 at the start to ~0.97 at completion — entirely through RL, with no prior reasoning trace imitation. 2
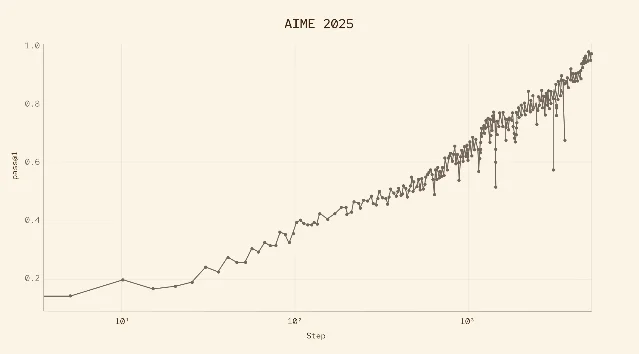
The training approach — called the "Hill-Climbing Machine" — runs three independent specialist RL climbs (STEM, Agentic Coding, Helpfulness & Safety), then consolidates them via supervised fine-tuning and a final RL stage. 7 The report's authors wrote: "MAI-Thinking-1 is a starting point, not a destination." The chart above is evidence for why that framing matters — the curve doesn't flatten. Each doubling of compute steps yielded continued gains.
PM implementation path
The model is in private preview as of today, accessible via Microsoft Foundry. Public API availability is weeks away, not days. That means immediate production integration is off the table — but evaluation and positioning decisions aren't.
Three actions worth taking now:
- If your team uses Azure and already has Foundry access: Request private preview access. Run your top 5 long-context reasoning workloads (legal review, code analysis, multi-step planning) through MAI-Thinking-1 alongside your current provider. The 256K context window and concise output style — MAI won on "conciseness/relevance" against Sonnet 4.6 by ∆0.11 — are the dimensions most likely to show differentiation on knowledge-worker tasks. 2
- If your team has compliance constraints around training data provenance: Flag MAI-Thinking-1 for your legal/procurement team now. Microsoft's clean-data-lineage argument is directly targeted at enterprise legal risk. Pricing isn't public yet, but Mustafa Suleyman claimed a McKinsey-tuned MAI model achieved the highest win rate of any tested model at roughly 10× lower cost than alternatives. 7 That's a Suleyman claim without independent verification, but the cost direction is consistent with MoE economics.
- If you're evaluating model fine-tuning for a specific domain: The Baseten partnership is worth watching. MAI-Thinking-1 on Baseten gives you access to model weights for customization, with your fine-tuned checkpoint staying on your infrastructure — Microsoft has no visibility into what you build. 8 This positions MAI as a serious alternative to the fine-tuning APIs offered by OpenAI and Anthropic, where your checkpoint lives on their infrastructure under their terms.
Skip it for now if: your workload depends on Terminal-Bench-style agentic autonomy, your team is off Azure and doesn't want another cloud relationship, or you need production-grade SLAs before the public preview drops.
The PM takeaway
MAI-Thinking-1 is not yet the best reasoning model on any single benchmark. But it's the first credible model from a non-lab company with a full-stack story: model, cloud (Azure Foundry), developer tools (GitHub Copilot), silicon (MAIA 200), and OS (Windows Agent Framework). 6
The actual shift for product teams: the "use OpenAI or Anthropic" default just became a three-way decision. That's not a reason to switch today. It's a reason to build your evaluation infrastructure so you can switch when pricing, SLAs, and benchmark data actually favor it.
Cover image: AI-generated illustration
참고 출처
- 1Introducing MAI-Thinking-1 — Microsoft AI
- 2MAI-Thinking-1: Building a Hill-Climbing Machine — Technical Report
- 3Microsoft Build 2026: Be yourself at work
- 4Simon Willison: Microsoft's new MAI models
- 5Gizmodo: Microsoft Targets Legal Fears to Sell Its Powerful New AI Model to Businesses
- 6CNBC: Microsoft unveils new AI models to lessen reliance on OpenAI
- 7Building a hill-climbing machine: Launching seven new MAI models
- 8MAI-Thinking-1 is coming to Baseten
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.