1/5


ArXiv 扩散模型日报 | 2026-05-08:采样加速、蒸馏新路、稀疏 3D 重建、条件采样理论、书法生成
精选 2026-05-08 ArXiv 公告批次中最值得关注的 5 篇扩散模型预印本:DBMSolver(免训练桥采样器)、CDM(连续时间 DMD 蒸馏)、S2C-3D(稀疏图像 3D 重建)、条件扩散理论保证、InkDiffuser(中文书法生成),附 2 篇 Honorable Mention。
2026. 05. 11. 00:13:14
갤러리
本期快览:2026-05-08 公告批次,cs.CV 121 篇、cs.LG 227 篇新提交12,其中扩散相关约 35 篇。精选 5 篇,覆盖采样加速(CVPR 2026)、蒸馏(连续时间 DMD)、3D 生成(SIGGRAPH 2026)、条件扩散理论、中文书法生成五个子方向。
01|DBMSolver:免训练扩散桥采样器,6 NFE 实现 SOTA 图像翻译(CVPR 2026)
扩散桥模型(DBM)在图像到图像(I2I)翻译上表现优异,但现有采样器往往需要数十次甚至上百次函数评估(NFE)。Sankarshana Venugopal 等人在这篇 CVPR 2026 论文中提出 DBMSolver,利用 DBM 底层 SDE/ODE 的半线性结构,通过指数积分器导出 1 阶和 2 阶闭式解3。
与 DBIM 的线性多步近似不同,DBMSolver 为 VP 桥和 VE 桥分别推导了严格闭式解,避免了低 NFE 下的粗糙近似误差。整个框架完全免训练,无需蒸馏或微调。
"We introduce DBMSolver, a training-free sampler that exploits the semi-linear structure of DBM's underlying SDE and ODE via exponential integrators, yielding highly-efficient 1st- and 2nd-order solutions. This reduces NFEs by up to 5× while boosting quality (e.g., FID drops 53% on DIODE at 20 NFEs vs. 2nd-order baseline)."——(我们提出 DBMSolver,一种免训练采样器,通过指数积分器利用 DBM 底层 SDE/ODE 的半线性结构,导出高效的 1 阶和 2 阶解。与 2 阶基线相比,NFE 减少最高 5 倍,同时质量提升——如在 20 NFE 下 DIODE 数据集的 FID 下降 53%。)
关键数据3:
| 数据集 | NFE | FID | 对比基线 |
|---|---|---|---|
| DIODE 256×256 | 6 | 3.38 | Hybrid Heun 119 NFE → FID 4.43 |
| DIODE 256×256 | 20 | 2.06 | 同上基线,快 20 倍 |
| Edges2Handbags 64×64 | 20 | 0.53 | 有训练方法 CDBM 2 NFE → FID 1.30 |
| Face2Comics 256×256 | 20 | 0.96 | — |
| ImageNet 中心补全 | 6 | 4.98 | 吞吐量 45.41 img/s,比 Hybrid Heun 快约 47 倍 |
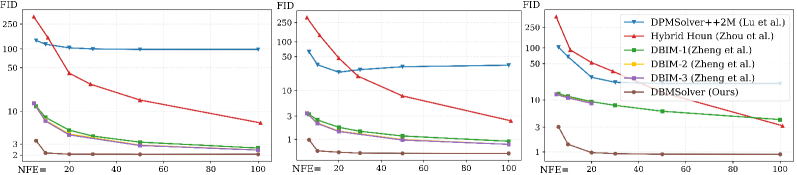
Edges2Handbags 那行值得单独看:DBMSolver(免训练,20 NFE)的 FID 0.53 优于需要训练的 CDBM(2 NFE,FID 1.30)。这说明对于扩散桥场景,精确的闭式解比低 NFE 蒸馏更划算——前提是可以接受 20 步推理开销。
02|CDM:连续时间分布匹配蒸馏,4 步超越百步教师模型
分布匹配蒸馏(DMD)框架目前的主流做法是将训练锚定在一组固定的离散时间点上,这限制了速度场的平滑性并导致视觉伪影。Tao Liu 等人提出 CDM(Continuous-Time Distribution Matching),将整个优化过程从离散调度迁移到连续时间空间——这也是首次将 DMD 框架做这一迁移4。
CDM 背后有两个洞见:第一,训练优化锚定到固定离散时间点并非必要;第二,DM 损失不是被动正则化器,而是驱动学生模型对齐教师 CFG-free 分布的核心驱动力。基于此,作者提出动态连续调度策略(随机长度反向模拟)和离轨迹 CDM 损失(速度驱动外推),整个框架无需 GAN 或奖励模型等辅助模块。
"CDM provides highly competitive visual fidelity for few-step image generation without relying on complex auxiliary objectives."——(CDM 在少步图像生成中提供极具竞争力的视觉保真度,且无需依赖复杂的辅助目标函数。)
在 SD3-Medium 上的 4 NFE 结果4:
| 指标 | CDM(4 NFE) | 对比 |
|---|---|---|
| HPSv3 | 9.561 | 五项中四项最优 |
| Aesthetic | 6.075 | — |
| DPGBench | 85.26 | — |
| PickScore | 21.95 | — |
| COCO FID(10K) | 30.30 | 优于 D-DMD 的 31.47 |
在 Longcat-Image 上,CDM 4 NFE 的 HPSv3=10.65、DPGBench=88.35 均超过了 100 NFE 的教师模型。推理延迟与 D-DMD 相同(1024×1024 单卡 246ms/图),额外成本仅在训练阶段(约 1.8×)。

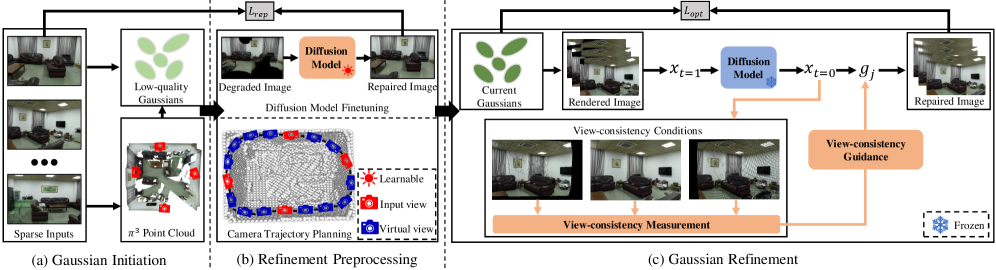
03|S2C-3D:6-8 张稀疏输入,完整高保真 3D 场景重建(SIGGRAPH 2026)
现有基于扩散的 3D 补全方法存在三个共同缺陷:视角不一致、生成图像与真实 3D 场景间的领域差距、以及简单相机插值导致的场景覆盖盲区。S2C-3D(Sparse-to-Complete)针对这三点各提出一个组件5:
- 场景专用微调:用目标场景数据对扩散模型做领域适配,消除领域差距
- 免训练视角一致性条件采样:在采样过程中显式量化多视图一致性并注入约束,解决大面积未见区域的模糊和伪影问题
- 相机轨迹规划:确保全场景覆盖,避免相机路径遗漏关键区域
"our approach produces high-fidelity 3D Gaussians that are robust to artifacts... constructing high-quality scenes that are free from missing regions, blurring, or other artifacts with very sparse inputs."——(我们的方法生成对伪影鲁棒的高保真 3D 高斯,以极稀疏的输入构建无缺失、无模糊的高质量场景。)
在三个 benchmark 上的定量结果5:
| 数据集 | 视图数 | PSNR | SSIM | LPIPS | 最强对比 |
|---|---|---|---|---|---|
| ScanNet++(真实 100 场景) | 8 | 18.777 | 0.706 | 0.315 | VD-3DGS:18.291/0.688/0.346 |
| Replica(合成 8 场景) | 6 | 20.360 | 0.721 | 0.281 | GenFusion:19.855/0.701/0.290 |
| S2C-Scene(自采集 11 场景) | 6 | 17.647 | 0.658 | 0.368 | GenFusion:17.188/0.648/0.382 |
消融实验进一步量化了三大组件各自的贡献:在 Replica 6 视图上,去除视角一致性条件采样后 PSNR 从 20.360 降至 18.129,降幅最大;去除轨迹规划降至 18.253,去除掩码微调降至 18.522。
04|条件扩散的理论基础:线性约束、Langevin 混合与信息论保证
这篇论文针对零样本条件扩散采样中的投影方法(projection-based methods)做了系统性理论分析。核心问题是:这类方法能保证测量一致性(measurement consistency),但无法保证正确的条件分布——这两件事在数学上是不同的6。
Ahmad Aghapour 等人通过得分函数的法向-切向分解揭示了误差来源:
"A central difficulty is that measurement consistency and conditional sampling are not the same task. Measurement consistency only requires producing a sample... Conditional sampling requires more: among all feasible signals satisfying the measurement, samples should be distributed according to the true conditional law of the data."——(核心困难在于:测量一致性与条件采样本质上是两件不同的事。测量一致性只要求产生一个可行样本……条件采样要求更多:在所有满足测量的可行信号中,样本必须服从数据的真实条件分布。)
"enforcing the measurement in the normal directions is not sufficient for highly ill-posed linear inverse problems; additional tangent-space mixing can substantially improve perceptual and distributional quality."——(仅在法向方向强制测量约束对高度病态的线性逆问题不够充分;额外的切空间混合可以实质性地提升感知质量和分布质量。)
理论部分的关键结论:用无条件切得分近似条件切得分的路径误差上界由观测与未观测分量间的条件互信息控制,且这一上界与问题维度无关——这给病态逆问题的误差分析提供了一个 tractable 的框架。
基于该理论,作者提出 LCDM-BAOAB(projected-Langevin 初始化 + 引导反向去噪)。
与 DDNM 的对比结果6:
| 任务 | 数据集 | LCDM-BAOAB FID | DDNM FID |
|---|---|---|---|
| 补全(固定 mask) | CelebA-HQ | 11.33 | 13.82 |
| 补全(固定 mask) | ImageNet | 18.35 | 26.13 |
| 补全(随机 mask) | CelebA-HQ | 6.23 | 7.23 |
| 补全(随机 mask) | LSUN Church | 9.55 | 11.84 |
| 8× 超分辨率 | CelebA-HQ | 29.58 | 33.88 |
| 8× 超分辨率 | LSUN Church | 21.03 | 28.80 |
| 8× 超分辨率 | ImageNet | 45.57 | 60.74 |

本文暂未提供代码仓库,理论推导的实现细节需要从论文中自行还原。
05|InkDiffuser:可微形态学优化,单样本生成高保真中文书法
现有中文书法生成方法的两个常见问题是笔画渲染不真实和墨水形态失真,根源在于缺乏对墨水结构的显式约束。Kunchong Shi 和 Jing Zhang 提出 InkDiffuser,将可微形态学操作直接融入扩散过程,仅需一张参考字形即可生成高质量书法字体7。
"Current Chinese calligraphy generation methods suffer from poor stroke rendering and unrealistic ink morphology, resulting in outputs with limited visual fidelity and artistic fluidity."——(当前中文书法生成方法存在笔画渲染差和墨水形态不真实的问题,导致输出的视觉保真度和艺术流畅性有限。)
两大核心技术:
- 高频增强机制(STAF):高频表征携带轮廓细节,通过融合高频特征保留字形边缘信息
- 可微墨水结构损失(DIS):将可微形态学操作集成到扩散训练过程,显式正则化墨水形态,使模型学习笔画轮廓的细粒度分解
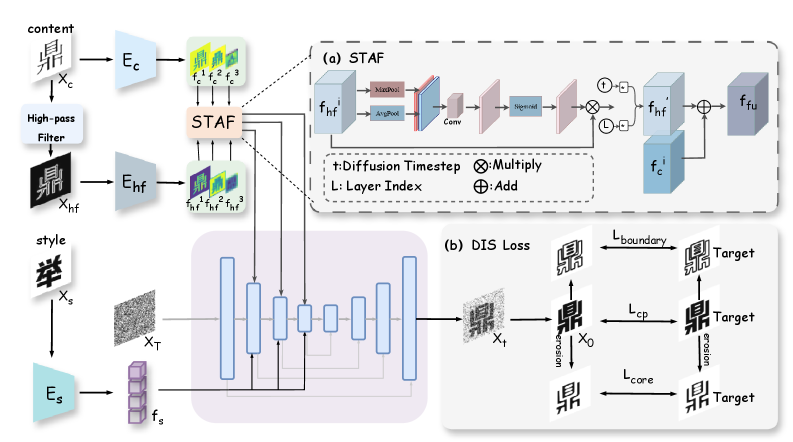
与 CF-Font、FontDiffuser 等基线的对比7:
| 数据集 | LPIPS ↓ | SSIM ↑ | L1 ↓ | PSNR ↑ | 相对无模块基线 |
|---|---|---|---|---|---|
| UFUC | 0.1573 | 0.6099 | 0.1237 | 10.0861 | LPIPS 0.1615→0.1573,SSIM 0.5857→0.6099 |
| UFSC | 0.1414 | 0.6087 | 0.1163 | 10.4785 | — |
五项指标在两个数据集上全面最优。消融实验表明 STAF 和 DIS 的联合使用是关键——单独去除任一模块后 LPIPS 和 SSIM 均有明显下降。
Honorable Mention
R2H-Diff(arXiv 同批次):0.58M 参数的轻量图像超分模型,在 PSNR 35.37dB 的水平上将模型尺寸压缩到极致,适合边缘端部署场景。参数量与同期方法相比小约一个数量级,尚无代码发布。
Consistency Models 3D 异常检测(CVPR 2026 Workshop):将一致性模型(Consistency Models)引入工业 3D 点云异常检测,在多个工业数据集上实现 80 倍推理加速,同期召回率不降,已有 CVPR 2026 workshop 接收。代码未见公开。
참고 출처
- 1ArXiv cs.CV New Listings 2026-05-08
- 2ArXiv cs.LG New Listings 2026-05-08
- 3DBMSolver: A Training-free Diffusion Bridge Sampler for High-Quality Image-to-Image Translation
- 4Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
- 5Sparse-to-Complete: From Sparse Image Captures to Complete 3D Scenes
- 6Conditional Diffusion Under Linear Constraints: Langevin Mixing and Information-Theoretic Guarantees
- 7InkDiffuser: High-Fidelity One-shot Chinese Calligraphy via Differentiable Morphological Optimization
댓글 (0)