
arxiv.org
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities
Google DeepMind 发布的 Gemini 2.X 技术报告,2025 年 7 月首发,2025 年 12 月更新至 v6。
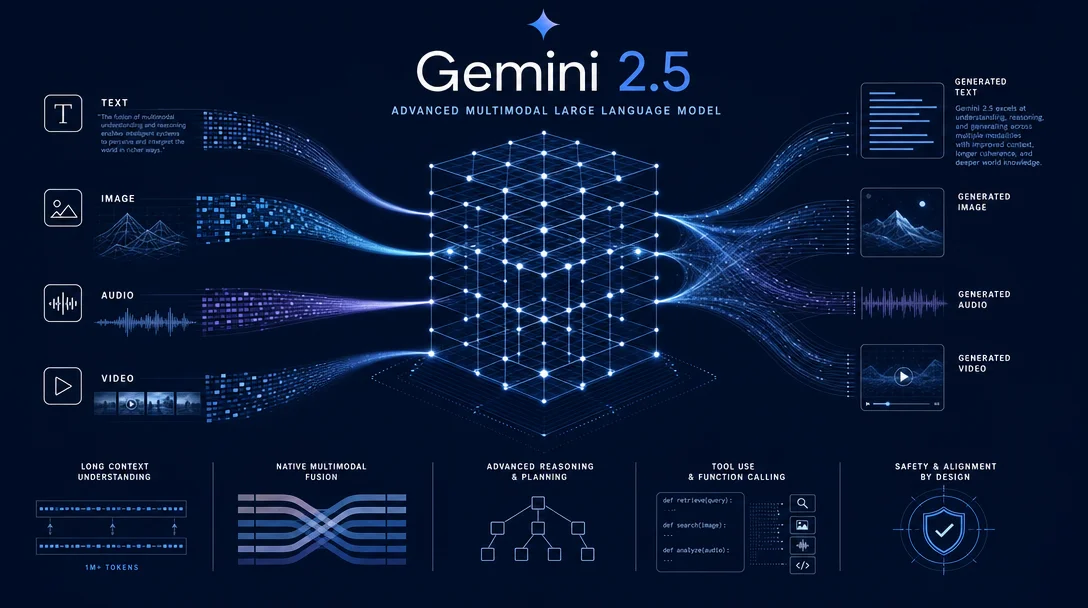
Google DeepMind 发布 Gemini 2.X 家族技术报告,首次公开 MoE 架构细节、Deep Think 并行思考机制与模态能力。Gemini 2.5 Pro 支持超 100 万 token 上下文,可处理约 3 小时视频,Aider Polyglot 一年内性能提升 5 倍。本文梳理论文核心技术方向与基准表现,包括智能体应用潜力与评估体系瓶颈的诚实讨论。
리서치 브리프

| 评测项目 | Gemini 2.5 Pro | 对比基准 |
|---|---|---|
| Aider Polyglot(代码) | SOTA | 超越 Claude 3.7 Sonnet |
| SWE-bench Verified(代码智能体) | 63.8% | Claude 3.7 Sonnet 70.3% 3 |
| GPQA (diamond)(科学推理) | 领先 | 超过 GPT-4.5 等 |
| Humanity's Last Exam | SOTA | — |
| LOFT / MRCR 128k 长上下文 | SOTA | — |
| 视频理解(视频基准) | SOTA | 超过 GPT-4.1 |
| 公共 ASR / AST 音频基准 | SOTA | — |
Google DeepMind 发布的 Gemini 2.X 技术报告,2025 年 7 月首发,2025 年 12 月更新至 v6。
软件工程基准排行榜,追踪各大模型在代码智能体任务上的真实表现。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.