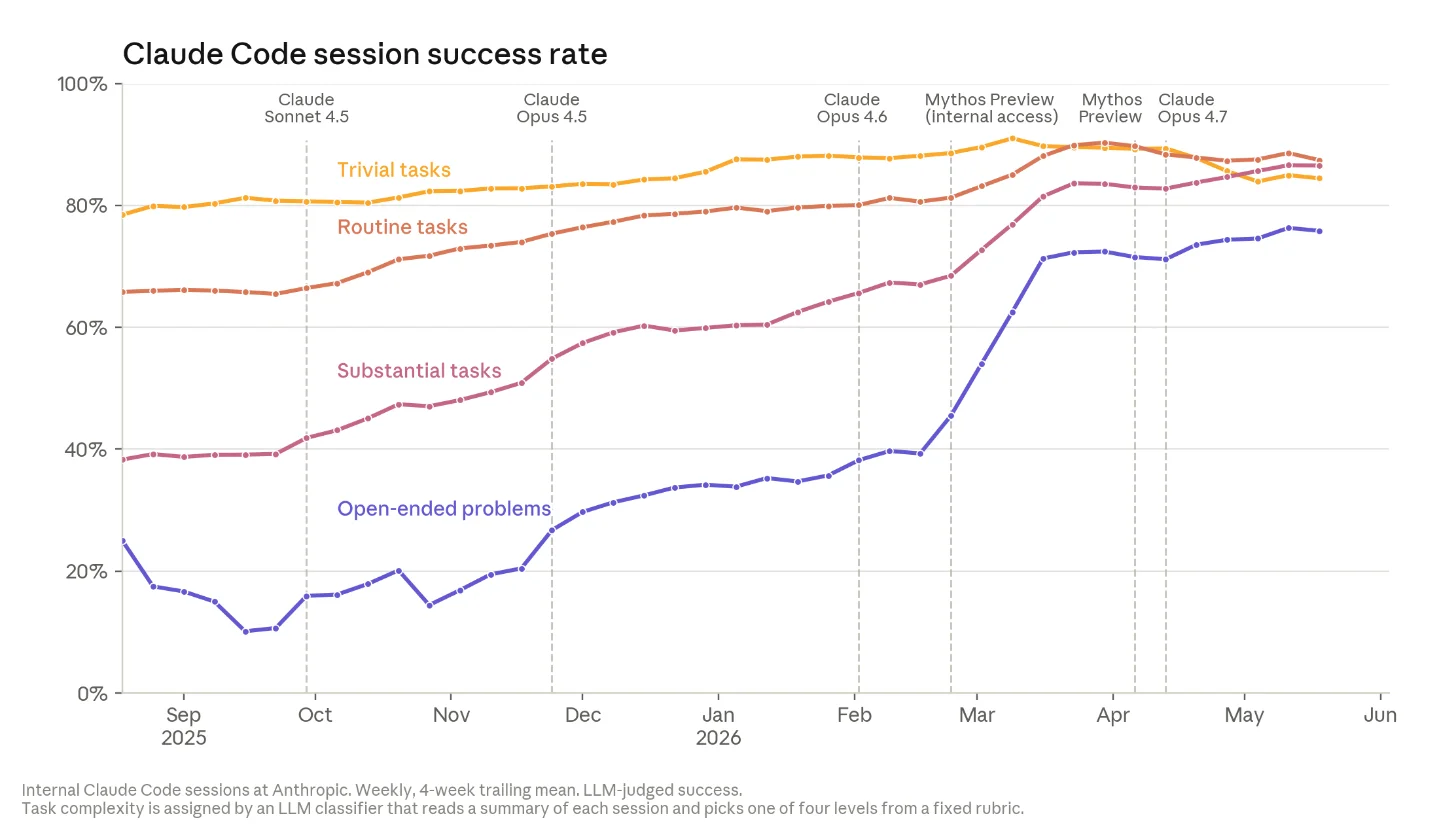
Claude is already building Claude — and the numbers are harder to dismiss than the headlines
Anthropic's "When AI Builds Itself" report buries the real story under the pause debate: Claude now authors 80%+ of Anthropic's production code, engineers merge 8× more code per day, and Claude Mythos Preview outperforms human researchers at optimization tasks (52× vs a human's 4×) and research judgment (64% win rate at wrong-turn moments). Three concrete PM actions around the Amdahl bottleneck shift.

Anthropic published a report on June 4 called "When AI Builds Itself." 1 The media coverage landed on the pause-debate angle — Anthropic wants a coordinated global slowdown, critics say it's regulatory theater. Both framings miss the more important part: buried inside the same document are specific, internal metrics about how Claude is actually performing today. Those numbers are what PMs should be reading.
The claim is specific, not theoretical
Recursive self-improvement (RSI) — the idea that an AI system could autonomously design and develop its own successor — is what the report is technically about. Anthropic says "we have not yet arrived at recursive self-improvement" but that current trends point toward it. 1
What the report is actually documenting is something more immediate: Claude as co-developer at Anthropic right now.
- 80%+ of merged production code at Anthropic was authored by Claude as of May 2026 — up from low single digits when Claude Code launched in February 2025. 1
- In Q2 2026, the average Anthropic engineer merges 8× the code per day they did before 2025. 2
- Internal survey of 130 researchers: median productivity estimate using Claude Mythos Preview is ~4× without AI. 1 2
One Anthropic employee quoted in the report: "I started leaning hard into Claudifying about a year ago. That's been a crazy adventure and it's now been ~5 months since I last wrote any code myself." 1
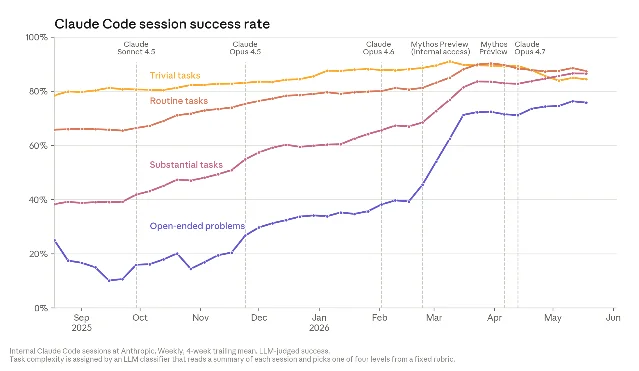
The metrics that actually matter
Three data series in the report tell the acceleration story more precisely than the "80% of code" headline.
Coding task success rate. Claude Code now completes 76% of open-ended coding problems — the category where there's no predetermined correct answer. Six months ago that number was 26%. 1 Routine tasks are up to the high 80s. An Anthropic engineer described a real incident: a production crash that wiped out tens of thousands of training jobs. Given only text logs and cluster access, Claude independently traced and fixed the cause — an obscure debugging flag — in about two hours. The same diagnosis would normally take two to three days. 1
Experiment optimization. Anthropic runs the same benchmark with each model release: give Claude a code snippet for training a small model, tell it to make it run as fast as possible without breaking correctness. Claude Opus 4 (May 2025) achieved roughly a 3× speedup. Claude Mythos Preview (April 2026, Anthropic's most capable internal model at the time) achieved roughly 52×. A skilled human researcher needs 4–8 hours to reach a 4× speedup. The report's assessment: "In this part of the research workflow—optimizing steps within a clearly defined experiment—Claude has gone from super helpful to superhuman in under a year." 1 3
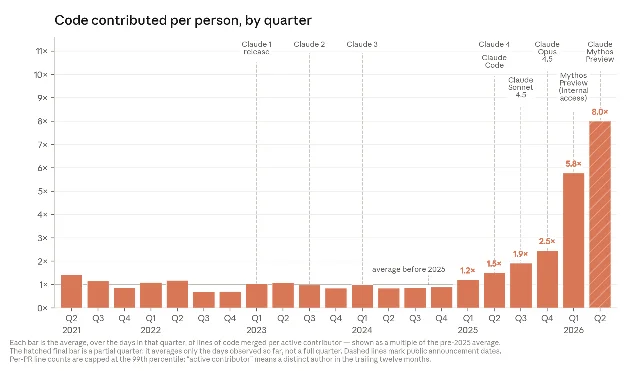
Research judgment. Anthropic studied 129 real Claude Code research sessions (the sessions themselves, not a controlled benchmark) and identified the moments where a human researcher took a wrong turn. They asked each Claude version: given what you can see so far, what would you do next? An independent model — one that knows how the session eventually resolved — judged whether Claude or the human gave better guidance at each fork.
Claude Opus 4.5 (November 2025) gave the better suggestion in 51% of wrong-turn moments. Claude Mythos Preview (April 2026): 64%. The practical ceiling, measured with a model that can see the session's full eventual outcome, is about 90%. 1
The honest tension
The report also proposes three scenarios for where this leads, and it doesn't pretend the trajectory is guaranteed to continue:
- S-curve stall — the acceleration flattens, constrained by chip supply chains, power grids, or interconnect bandwidth. Anthropic considers this unlikely.
- Compound efficiency gains — AI development is substantially automated, but humans continue to set research direction. A 100-person team does the work of a 10,000-person organization. Anthropic thinks the evidence points here now.
- Full recursive self-improvement — AI systems design and refine their own successors; progress rate becomes a function of compute availability. Human role shrinks to oversight, verification, and validation.
The proposed response — a conditional, multi-lab, multi-country coordinated pause — is where the controversy concentrates. Anthropic says it won't pause unilaterally, only if other frontier developers do so "in a verifiable manner." 1 Critics from multiple directions — including NYU's Gary Marcus, the Wharton School's Ethan Mollick, and former White House AI advisor David Sacks — read the timing (one week after Anthropic filed a confidential IPO at a ~$965B valuation) as something between principled safety advocacy and strategic positioning. 4 5
Gary Marcus: "They want it both ways. They don't actually want a pause — at least for now." 4
Ethan Mollick (Wharton) offered the most useful calibration: "There is a bit of navel-gazing, some marketing, and a lot of very sincere beliefs about what Anthropic thinks is likely in the near future of AI that you probably want to be aware of." 6
That framing — genuine belief mixed with strategic incentive — is probably closer to the truth than either pure cynicism or pure alarm.
What this means for your roadmap
The pause debate doesn't have a concrete PM action attached to it. The internal data does.
Reframe what "engineering capacity" means. Amdahl's Law is the CS principle that the bottleneck of a system shifts to whatever stage you didn't speed up. The report's observation is the most actionable signal: code generation has accelerated so fast that human code review is now the bottleneck at Anthropic. 1 If your team uses AI-assisted coding at any meaningful scale, the constraint on shipping velocity is shifting from "how fast can engineers write code" to "how fast can engineers review, validate, and make judgment calls." Roadmap planning that assumes human engineering bandwidth as the primary variable is already behind.
The research judgment data has hiring implications. At the moments where a human researcher takes a wrong turn, the current best Claude model gives a better suggestion 64% of the time. The comparison isn't designed to be a fair human-vs-AI contest — it specifically targets decision points where the human had room to improve. But that's exactly the scenario that matters in practice: your weakest judgment moments, not your strongest. Where models are now outperforming humans most reliably is on well-scoped optimization tasks inside a defined experiment. Where humans retain the edge, per the report: "seeing the bigger picture and thinking beyond the confines of the immediate task." 1 That's a fairly precise job description for where to concentrate your team's senior technical headcount.
On the AI safety research front, Anthropic ran nine parallel agents on the question "can weak models reliably supervise strong models?" — an open AI alignment problem. In 800 cumulative hours and roughly $18,000 of compute, the agents recovered 97% of the performance gap that a human team would close. Two human researchers working a full week recovered 23%. 1 That's not a product feature — but it tells you where compute-intensive research tasks are heading.
The METR (Model Evaluation & Threat Research) task-horizon benchmark — measuring how long an AI can reliably work on a continuous task before losing coherence — has been doubling every four months (down from seven months previously). 2 As of early 2026, that number is approximately 12 continuous hours. Jack Clark (Anthropic co-founder) framed it directly: "When I look down at the car we're driving, all I have is a gas pedal. I don't have a brake pedal, and surely at some point in the future we might want that option." 7
The pause question is a policy problem. The productivity curve is an engineering and product planning problem — and that one is already in your lane.
Cover image: Claude Code session success rate by task complexity chart from When AI builds itself — The Anthropic Institute
참고 출처
- 1When AI builds itself — The Anthropic Institute
- 2Claude writes 80% of its code, calls for AI pause — TNW
- 3System Card — Claude Mythos Preview — Anthropic
- 4What smart people are saying about Anthropic suggesting a global AI pause — Business Insider
- 5Anthropic warns AI could soon build itself — Fortune
- 6Anthropic sounds alarm on self-improving AI — Firstpost
- 7Anthropic warns AI will soon be able to improve itself — CNN
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.