GitHub Trending Top 10: The agent skills layer matures (Jun 1–8)
This week's ten repos reveal skills-as-software becoming a genuine distribution primitive: five entries distribute domain expertise as agent-readable instruction contracts rather than deployed services. Headroom (+14,272 stars) compresses LLM context locally; Hermes Agent (+11,427) adds session-persistent self-improving memory; Open Notebook brings data-sovereign NotebookLM; Supermemory offers a 5-layer memory API with open benchmarks; and Open-LLM-VTuber assembles a fully offline AI VTuber stack. Impeccable, last30days-skill, Agent-Reach, Hermes WebUI, and oh-my-pi round out the harness-layer competition. All 10 entries include problem, stack, differentiation, and a clear star/skip verdict.

리서치 브리프
Last week the throughline was delivery harnesses and quality-enforcement skill files. This week a cleaner thesis emerges: five of the ten entries are distributing domain expertise as agent-readable instruction contracts rather than traditional applications. The SKILL.md format, which debuted as a power-user trick for Claude Code, is now the substrate for research engines, design systems, and internet scrapers. The other five entries fill out the application layer — memory APIs, a NotebookLM clone, a VTuber stack, and a self-improving agent platform that just crossed 185,000 stars.
Four entries from last week (markitdown, MoneyPrinterTurbo, ECC, taste-skill) remained on the trending page but showed no significant new development; they're excluded per prior-coverage policy.
Rankings are by weekly star gain for the June 1–8 window. Total star counts are as of June 8.
#1 · chopratejas/headroom — 16,941 stars · +14,272 this week
Problem solved: Running AI agents at scale costs more tokens than it should. Tool call outputs, log files, RAG chunks, and conversation history can easily balloon a single agentic session to 50,000–80,000 tokens — most of which the model doesn't need in full detail. Headroom sits between your agent and the LLM as a compression middleware: it intercepts content before it reaches the model and compresses it using the right algorithm for the content type. 1
Stack and approach: Python (77%) + Rust (18.2%) + TypeScript (2.7%), Apache 2.0. Six routing algorithms:
SmartCrusher for JSON, CodeCompressor for AST-aware code (Python/JS/Go/Rust/Java/C++), Kompress-base (a HuggingFace model trained specifically on agentic traces), CacheAligner (stabilizes prompt prefixes to hit provider KV caches), CCR (reversible compression — originals are never deleted), and ContentRouter (auto-detects content type and routes). Three integration modes: wrap an existing agent CLI (headroom wrap claude/codex/cursor/aider), drop-in proxy (headroom proxy --port 8787), or inline library (from headroom import compress). v0.23.0 shipped June 4; the project has logged 153 releases in five months. 1Differentiation: Self-reported benchmarks show 92% token reduction on code search tasks (17,765 → 1,408 tokens) and SRE debugging sessions (65,694 → 5,118 tokens), with accuracy retention at 97–100% on GSM8K, TruthfulQA, SQuAD v2 (a reading comprehension benchmark), and BFCL (Berkeley Function Calling Leaderboard). 1 The key caveat: these numbers are from the project's own benchmarks — no independent third-party replication has surfaced yet. 2 Compared to alternatives: RTK covers only CLI command output; lean-ctx adds MCP and editor rules but no code-aware compression; Compresr and Token Co. require uploading your data to remote APIs — headroom runs locally with reversible compression ("originals are never deleted"). The
headroom learn command analyzes failed sessions and auto-writes learnings into CLAUDE.md / AGENTS.md / GEMINI.md. 2Verdict: ⭐ Star it if you pay attention to your agent token bills. The zero-code-change
headroom wrap path is the lowest-friction entry point. Treat the benchmark numbers as directional — the 97–100% accuracy retention claims need independent validation before you rely on them for production decisions.#2 · NousResearch/hermes-agent — 185,952 stars · +11,427 this week
Problem solved: Most AI agents are effectively amnesiac — every session starts from zero. You re-explain your preferences, your project context, your usual workflows. Hermes Agent's core claim is that it breaks this pattern by keeping a persistent, self-updating model of how you work: it extracts skills from your sessions, writes memories automatically, and searches its own history when starting new conversations. 3
Stack and approach: Python (82.9%) + TypeScript (13.2%), MIT license, maintained by Nous Research. 10,904 commits, 732 watchers, 17 formal releases. Six execution backends: local, Docker, SSH, Singularity, Modal, and Daytona — the last two support serverless sleep for cost control. Supports 40+ tools, MCP (Model Context Protocol) integration, cron scheduling, and 10+ messaging platforms (Telegram, Discord, Slack, WhatsApp, Signal, and more). The README's self-description: "It's the only agent with a built-in learning loop — it creates skills from experience, improves them during use, nudges itself to persist knowledge, searches its own past conversations, and builds a deepening model of who you are across sessions." 3 v0.16.0 ("The Surface Release") shipped June 5. 4
Differentiation: NVIDIA published a technical deep-dive on June 2 showing a Hermes Agent + NemoClaw + OpenShell deployment where "the agent learns preferences and patterns, writing new memories and skills. The more users work with the agent, the better it gets." 4 The OpenShell sandbox enforces network policies as code rather than as prompts — a meaningful distinction for enterprise deployments. Against OpenClaw (the closest alternative): Hermes auto-generates skills from experience rather than depending on a community marketplace; OpenClaw has wider messaging platform coverage (24+ including iMessage, LINE, WeChat) but the ClawHub marketplace has documented security concerns. 5 The 19,188 open issues look alarming at first glance — most are feature requests and community discussions, not quality defects.
Verdict: ⭐ Star it if you want a persistent agent that actually remembers how you work across sessions. The NVIDIA enterprise deployment pattern is a useful reference for teams evaluating production deployment. The 185K star count and active Nous Research backing give this more stability than most agent frameworks.
#3 · lfnovo/open-notebook — 27,261 stars · +2,993 this week
Problem solved: Google NotebookLM is genuinely useful for turning documents into structured notes, source-grounded Q&A, and generated podcasts — but it has three non-negotiable constraints: your data lives in Google's cloud, you get only Gemini as the underlying model, and there's no API for workflow automation. Open Notebook replicates NotebookLM's core workflow (upload sources → AI analysis → podcast generation → source-grounded chat) while giving you data sovereignty, model choice, and a full REST API. 6
Stack and approach: TypeScript 64.6% (Next.js + React frontend) + Python 33.6% (FastAPI backend), SurrealDB for storage, LangChain for RAG orchestration, MIT license. The key architectural decision is the self-built
Esperanto library — a unified provider abstraction across 18+ AI services (OpenAI, Anthropic, Groq, Google, Vertex AI, Ollama, Perplexity, ElevenLabs, Deepgram, Azure, Mistral, DeepSeek, Voyage, xAI, OpenRouter, DashScope, MiniMax, OpenAI-compatible). Adding one provider gives you full compatibility across all notebook features. SurrealDB handles both full-text search and vector search in a single database instead of stacking separate services. v1.9.0 shipped June 2, upgrading Esperanto to v2.22 and adding audio providers. 37 releases total — the fastest iteration cadence in this week's list. Docker setup is docker compose up -d. 6
Differentiation: Omid Saffari's independent review put the core use case plainly: "If you love NotebookLM's audio overviews but not where they run, this is the switch." 7 Open Notebook supports 1–4 speakers in podcast generation versus NotebookLM's fixed 2, and it handles multiple UI languages (English, Portuguese, Chinese, Japanese, Russian, Bengali). The honest gap: citations are marked "Basic references (will improve)" — NotebookLM's source citation is more complete. 6 The SurrealDB choice is a calculated bet — it's a less common database, and GitHub Issue #372 flags known scaling challenges, but the payoff is avoiding a separate vector database for smaller deployments.
Verdict: ⭐ Star it if you want NotebookLM's workflow on hardware you control with a model you choose. Skip it if citation quality is critical to your use case — wait for the "will improve" to arrive.
#4 · supermemoryai/supermemory — 26,015 stars · +2,924 this week
Problem solved: Every LLM call is stateless by default. Existing workarounds either require stitching together 5–7 components (vector database + extractor + connector + user profile + retrieval layer) or accept a crippled "memory as simple storage" approach. Supermemory packages a complete 5-layer memory stack — connectors, extraction, retrieval, memory graph, and user profiles — into a single API call. 8
Stack and approach: TypeScript 64.3% (Remix + TailwindCSS + Vite frontend), Postgres + Drizzle ORM, Cloudflare Workers/KV/Pages for edge deployment, Bun runtime, MIT license. The memory engine uses a vector graph with ontology-aware edges — instead of pure similarity search, it tracks fact changes over time ("I just moved to San Francisco" updates and supersedes "I live in New York"). MCP server available via
npx -y install-mcp@latest https://mcp.supermemory.ai/mcp. Framework integrations cover Vercel AI SDK, LangChain, LangGraph, OpenAI Agents SDK, Mastra, Agno, n8n, and Claude Memory Tool. Connectors sync from Google Drive, Gmail, Notion, OneDrive, and GitHub via real-time webhooks. Holds SOC 2 Type 2, HIPAA, and GDPR certifications. 8Differentiation: Supermemory's own benchmark claims #1 on LongMemEval (85.4% accuracy), LoCoMo, and ConvoMem, with sub-300ms recall. 9 These numbers come from their own blog — the accompanying open-source MemoryBench repo at
github.com/supermemoryai/memorybench lets you reproduce comparisons, which is a meaningful transparency gesture. The comparison they draw against Mem0 (higher latency, no document connectors, no user profiles) and Zep (manual graph management) is plausible but comes from the vendor. The credible community concern is vendor lock-in: Cloudflare-first architecture limits self-hosting options, and at least one Reddit commenter noted "cloud providers suck because they are cloud, vendor lock-in and data retention is just not for me." 10Verdict: ⭐ Star it for the complete memory API story and the MemoryBench transparency. Hold off on production adoption until independent benchmarks confirm the latency and accuracy claims. If self-hosting is a hard requirement, evaluate whether Cloudflare Workers matches your infrastructure constraints before committing.
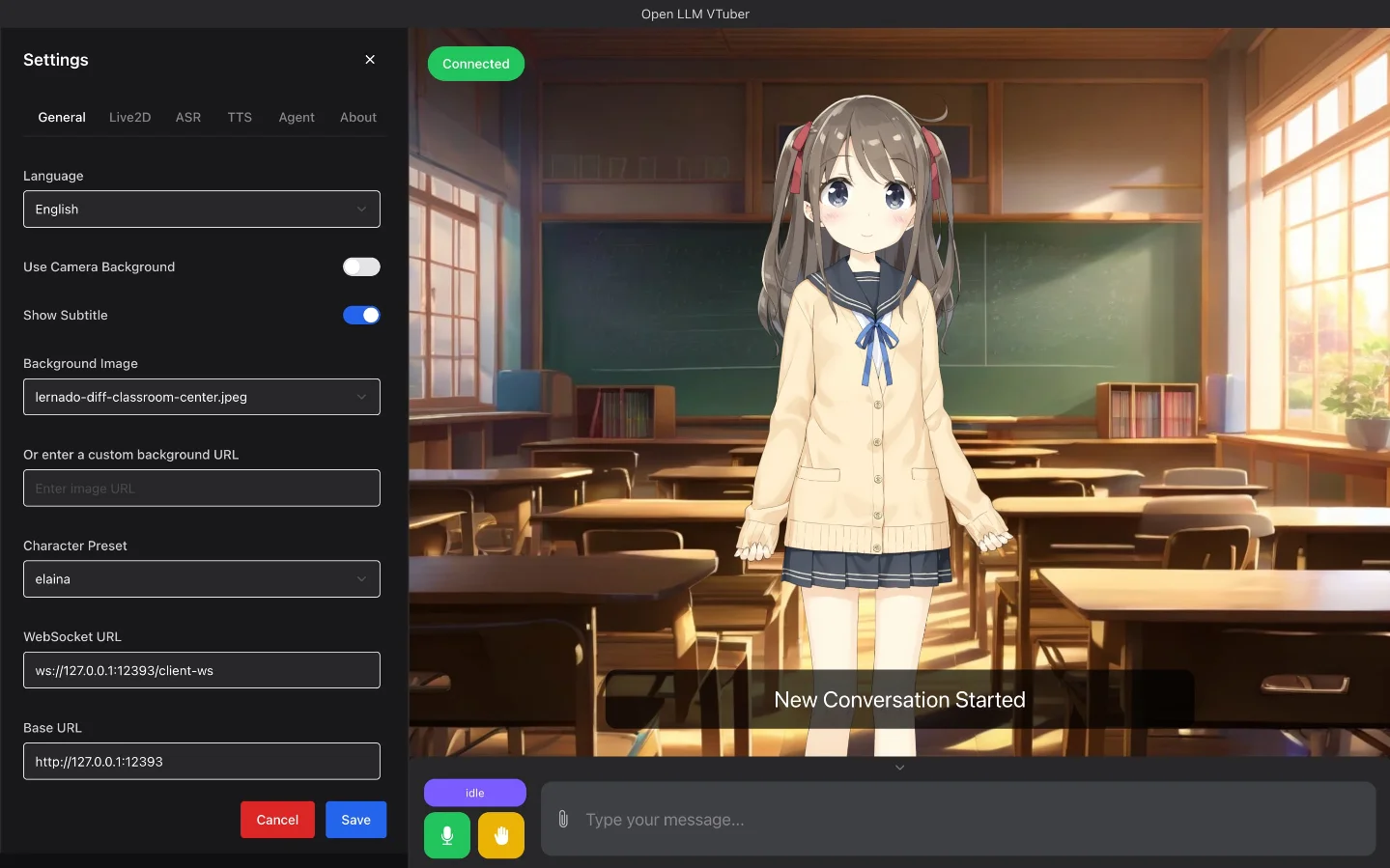
#5 · Open-LLM-VTuber/Open-LLM-VTuber — 10,354 stars · +2,388 this week
Problem solved: Traditional VTuber software (VTube Studio, VSeeFace) handles facial tracking and model animation but has no built-in AI conversation layer. Adding an AI voice companion requires manually chaining VTube Studio + an LLM API + a TTS service + an ASR service + OBS. Open-LLM-VTuber collapses this into a single project that runs entirely offline: speech recognition → LLM inference → speech synthesis → Live2D face animation, all in one setup. 11
Stack and approach: Python 96.6%, MIT license (Live2D sample models carry a separate Free Material License — commercial use requires additional authorization). Supports 10+ LLM backends (Ollama, OpenAI, Gemini, Claude, Mistral, DeepSeek, Zhipu AI, GGUF, LM Studio, vLLM), 7 ASR (Automatic Speech Recognition) engines (sherpa-onnx, FunASR, Faster-Whisper, Whisper.cpp, Groq Whisper, Azure ASR), and 10+ TTS (Text-to-Speech) engines (MeloTTS, GPTSoVITS, CosyVoice, Fish Audio, Edge TTS, Azure TTS, and others). The voice interruption system uses VAD (voice activity detection) + streaming TTS so the AI doesn't hear its own output — a clean solution to the feedback loop problem that comparable tools skip. Desktop client supports transparent-background pet mode, global top-most, and mouse passthrough. Visual perception is built in: the AI can access camera, screen recordings, and screenshots. 11

Differentiation: The README's self-description explains the name: "the project's initial development goal was to use open-source solutions that can run offline on platforms other than Windows to recreate the closed-source AI Vtuber neuro-sama." 11 That goal is met — it's cross-platform (Windows, macOS, Linux), NVIDIA and non-NVIDIA GPU, and fully offline-capable. VTube Studio has better facial tracking precision but no AI conversation. VSeeFace supports 3D VRM models but is Windows-only and lacks AI. The active risk: v2.0 is "in its early discussion and planning phase" and the project has explicitly asked the community not to submit new v1 feature PRs. 11 v1.x is functionally frozen.
Verdict: ⭐ Star it if you want a cross-platform, fully offline AI VTuber stack. The v2.0 rewrite timeline is unclear — if you need active feature development in the next few months, check the issue tracker before building on top of v1.
#6 · pbakaus/impeccable — 35,556 stars
Problem solved: AI coding agents produce visually predictable UI: Inter everywhere, purple-to-blue gradients, cards nested in cards, gray text on colored backgrounds. The pattern is consistent because every model trained on the same pool of SaaS templates. Impeccable — by Paul Bakaus (formerly Google, formerly Vercel) — is a plug-in design language for AI harnesses that encodes aesthetic constraints as an agent skill, a CLI detector, and a browser extension. 12
Stack and approach: JavaScript 93.4% + CSS 4.0% + Astro 1.9%, Node.js ≥24, Bun runtime, Apache 2.0, npm package
impeccable at v2.3.2. Three-layer architecture: a SKILL.md with 7 domain reference files (typography, color, spatial, motion, interaction, responsive, UX writing), 23 slash commands (/craft, /audit, /polish, /critique, /animate, /bolder, /quieter, /live, and others), and a npx impeccable detect CLI that checks 27 deterministic anti-patterns without requiring any LLM or API key. Supports 11 AI harnesses: Claude Code, Cursor, Gemini CLI, Codex CLI, GitHub Copilot, Kiro, OpenCode, Pi, Qoder, Trae, Rovo Dev. Paul Bakaus's stated design philosophy: "every visual element must earn its place. No ornament for ornament's sake." 13 CLI v2.3.2 shipped May 30. 12Differentiation: Taste-skill (issue #3, May 25–Jun 1) and impeccable are the same concept applied at different scope. Taste-skill is a behavioral preset (set
DESIGN_VARIANCE=7, get a specific aesthetic output); impeccable is a design vocabulary (it teaches the agent why certain choices are wrong and trains critique and iteration). Bakaus: "Every model trained on the same SaaS templates. Skip the guidance and you get the same handful of tells on every project." 13 The CLI detector is the technically novel piece — deterministic anti-pattern checking, no AI, runs on any HTML/CSS output. No published A/B test comparing AI output quality with and without impeccable; the case studies on impeccable.style show before/after pairs but the selection is curated.Verdict: ⭐ Star it if your team generates UI with AI agents and cares about visual quality. The
/audit command is the highest-leverage starting point — run it on existing AI-generated UI before adopting the full skill set. The 23-command vocabulary is steep; most teams will use 4–5 commands in practice.#7 · mvanhorn/last30days-skill — 31,010 stars
Problem solved: Researching what people actually think about a topic in the last month requires searching Reddit, X (Twitter), YouTube, Hacker News, and several other platforms separately — each one siloed, each requiring different authentication, each with its own API. Last30days-skill bridges 14 of these platforms through a single agent command: type
/last30days <topic> and a Python engine searches them in parallel, scores results by actual user engagement (Reddit upvotes, X likes, Polymarket odds), clusters duplicates across sources, and returns a cited briefing. 14Stack and approach: Python 3.12+ engine + vendored Node.js Bird client for X/Twitter + yt-dlp for YouTube transcripts + ScrapeCreators API + public JSON APIs, MIT license. By mvanhorn (v3 engine architecture by @j-sperling), 623 commits, 1,012 test cases. 14 Free coverage with zero API keys: Reddit (including comments), HN, Polymarket, GitHub. X/Twitter free via browser cookie authentication. v3.3.2 shipped June 6. The author's framing: "Google aggregates editors. /last30days searches people." 14 The unlock he describes: "Not one better search engine. A dozen disconnected platforms, bridged by an agent." 14
Differentiation: This is a skill file, not an application or API — it lives inside your agent's runtime context. The SKILL.md contract tells the agent what to invoke; the Python engine does the actual work. This design pattern (distributing functionality as an instruction contract rather than a deployed service) is the same pattern impeccable and Agent-Reach use — it's becoming a distinct software distribution primitive. X user @itsjasonai's reaction on first use: "I've been manually searching Reddit and X for research before every piece of content I write. Tab by tab. Thread by thread. That's the part that takes 90 minutes. This eliminates it." 14 Real limitation: ScrapeCreators requires paid credits after a free tier, and the cookie-based Twitter access can break when Twitter's frontend changes.
Verdict: ⭐ Star it for any research, content, or analysis workflow where you need cross-platform human opinion in the last 30 days. The free-with-zero-keys baseline (Reddit + HN + Polymarket + GitHub) is enough to evaluate whether it fits your workflow before configuring paid credentials.
#8 · Panniantong/Agent-Reach — 23,159 stars
Problem solved: Giving an AI agent access to the open internet requires configuring a different tool for each platform — Twitter has paid API requirements, Reddit needs its own workaround, YouTube subtitles need yt-dlp, Bilibili needs separate tooling, and so on. Each one has its own authentication, its own failure modes, its own quirks. Agent-Reach installs and configures 15 of these tools in one pass, so an agent can read web pages, search Twitter, watch YouTube, scrape Reddit, browse 小红书 (Xiaohongshu), and access 10 other platforms without requiring any paid API keys. 15
Stack and approach: Python 3.10+, MIT license, by Panniantong (Neo Reid). Explicit philosophy: this is scaffolding, not a framework. Each platform is a standalone Python file under
channels/; Agent-Reach does not wrap the upstream tools — it installs and configures them. The 15 supported platforms: web (Jina Reader), YouTube (yt-dlp), RSS (feedparser), full-web search (Exa via mcporter), GitHub (gh CLI), Twitter/X (twitter-cli via browser cookie — no paid API), Bilibili, Reddit (rdt-cli, same cookie approach), 小红书, 抖音 (Douyin MCP server), LinkedIn, WeChat Official Accounts (Exa), 微博, V2EX, and 雪球 (Xueqiu). Zero paid API fees for the base setup; the only optional cost is a residential proxy (~$1/month) for Bilibili access from overseas servers. 15 v1.4.0 shipped March 31. 15Differentiation: last30days-skill (entry #7) is an agent skill contract; Agent-Reach is the infrastructure layer that makes those kinds of skills actually work across platforms. They're complementary rather than competing. The author openly documents failure modes: Instagram was dropped from the platform list, Bilibili scraping breaks from overseas IPs, and a past CHANGELOG entry notes a Xueqiu 400 error fix — which means these limitations are tracked rather than hidden. The
agent-reach doctor command checks which channels are currently healthy. The main risk is brittleness: cookie-based platform access breaks when platforms update their frontends, and 15 platforms means 15 possible failure points.Verdict: ⭐ Star it if you're setting up an AI agent environment and want web access across major platforms without paying for a research API. Run
agent-reach doctor before depending on it in production to see which channels are live on your setup.#9 · nesquena/hermes-webui — 13,848 stars
Problem solved: Hermes Agent (entry #2) is powerful from the CLI but has no native web interface. Most users want browser-based access to their persistent agent — to see conversation history, manage skills, browse the agent's memory, and trigger cron jobs without opening a terminal. Hermes WebUI provides that: a three-panel browser interface with full feature parity with the CLI. 16
Stack and approach: Python backend + pure vanilla JavaScript frontend (no framework, no build step, no bundler — "Just Python and vanilla JS"), MIT license, by independent developer nesquena. 16 Three-panel layout: left sidebar for session navigation, center chat area, right workspace file browser. Features streaming SSE responses, multi-provider model switching, inline tool-call cards, Mermaid diagram rendering, collapsible thinking/reasoning cards, Web Speech API voice input, password auth + WebAuthn/Passkeys, 11 themes, and mobile-responsive layout (640px breakpoint). Full CLI session bridge: imports existing Hermes sessions from SQLite so you don't lose history when switching interfaces. Also ships an MCP server (
mcp_server.py) so other MCP clients can invoke it. 13,848 stars and 3,824 commits in roughly 2.5 months of existence. 16Differentiation: The no-framework frontend choice is architecturally deliberate and meaningful. Dependencies introduce security surface area; a vanilla JS frontend for a tool that handles your agent's complete memory and skill set keeps the attack surface minimal.
Why-hermes.md from the project documentation puts the differentiating claim plainly: "The distinction that matters is not 'has memory' vs. 'has no memory' — it's whether context persists across sessions automatically, whether execution happens on hardware you control, whether you can reach the same agent identity from any device, and whether the system gets meaningfully better at your specific workflow over time without manual configuration." 5 240 open issues at this activity level is a reasonable signal — not quality defects, backlog management.
Verdict: ⭐ Star it if you're using Hermes Agent and prefer a browser interface. The vanilla JS choice is a feature if you're security-conscious. This is effectively a required companion for entry #2.
#10 · can1357/oh-my-pi — 11,094 stars
Problem solved: AI coding agents fail not because the underlying model is bad, but because the tool interface between the model and the codebase is poorly designed. Can Bölük (security researcher, @can1357) ran benchmarks that showed changing only the edit format for Grok Code Fast 1 lifted its pass rate from 6.7% to 68.3%. Oh-my-pi is built on that thesis: the harness — file reading, search, editing, LSP integration, debugger, browser, subagent orchestration — is where most failures actually happen. 17
Stack and approach: TypeScript with ~27,000 lines of Rust embedded via N-API (Node.js native addon interface — ripgrep, glob, syntax highlighting running in-process), MIT license, runtime Bun. 7,570 commits since December 2025. 32 built-in tools, 13 LSP (Language Server Protocol) operations (including workspace-aware renames via
workspace/willRenameFiles), 27 DAP (Debug Adapter Protocol) debugger operations (lldb/dlv/debugpy as first-class tools, not afterthoughts). The core editing innovation is "Hashline": when the agent reads a file, each line gets a 2–3 character content hash attached. Edits reference hash anchors rather than re-stating the original text. If the file changed since last read, the hash mismatches and the edit is rejected — preventing a class of corruption bugs that other tools accumulate. 18 Supports 40+ model providers and 6 API protocol formats. Inherits rules from 8 competing tool formats (Cursor MDC, Cline .clinerules, Codex AGENTS.md, etc.). Four entry points: TUI, one-shot CLI, Node SDK (@oh-my-pi/pi-coding-agent), ACP (Agent Client Protocol). 18Differentiation: Bölük's stated position: "The harness problem is real, measurable, and it's the highest-leverage place to innovate right now. The gap between 'cool demo' and 'reliable tool' isn't model magic. It's careful, rather boring, empirical engineering at the tool boundary." 17 The Hashline edit mechanism is the sharpest technical differentiator — it's a concrete, verifiable mechanism rather than a claim. Knightli.com's independent review: "The interesting part of oh-my-pi is not that it is another AI terminal shell. It is that it reorganizes the tool layer that often holds AI coding back." 19 The 340 open issues and ongoing architecture work (the harness is still adding major features) mean this is a tool for developers comfortable with a fast-moving codebase.
Verdict: ⭐ Star it if you do serious development work with AI coding agents. The Hashline editing mechanism and first-class debugger support alone separate it from most alternatives. Run the benchmark from Bölük's blog against your own workflow before committing — the pass-rate improvement is real but highly model- and task-specific.
Three patterns this week
Skills-as-software is a distribution primitive now. Five of ten entries this week — headroom, impeccable, last30days-skill, Agent-Reach, and oh-my-pi — distribute functionality as agent-readable instruction contracts rather than traditional deployed services. The SKILL.md format, which started as a power-user trick, is becoming the layer where domain expertise gets encoded: design taste, internet research, compression middleware, and coding tool interfaces are all arriving this way. Any domain where AI agents have predictable failure modes is a candidate for a skill-file treatment.
The memory and context management space is consolidating fast, with unresolved benchmark questions. Supermemory, hermes-agent, and headroom all sit in adjacent parts of the same problem: how does an agent remember and retrieve the right information efficiently? Supermemory claims #1 on LongMemEval. Hermes builds self-generated skills from session experience. Headroom compresses context before it reaches the model. All three benchmark primarily against their own numbers — independent third-party evaluation of all three lags the deployment curve. Developers adopting any of them in production should run MemoryBench (open-sourced by Supermemory) against their actual use case rather than treating vendor claims as settled.
The harness layer is getting more competitive and more empirical. Oh-my-pi, hermes-webui, and headroom each make a measurable engineering argument: specific benchmark numbers, verifiable mechanisms (Hashline), or reproducible benchmarks (MemoryBench). This is a contrast with the prior generation of agent frameworks, which competed mostly on feature lists and star counts. Bölük's harness-problem framing — "careful, rather boring, empirical engineering at the tool boundary" — is becoming the operative standard for the tools that are actually getting used in production.
Cover: Open-LLM-VTuber desktop client showing Live2D character in classroom scene with settings panel and chat interface. 11
참고 출처
- 1GitHub: chopratejas/headroom
- 2DEV: Headroom — Cut Your LLM Token Usage by Up to 95%
- 3GitHub: NousResearch/hermes-agent
- 4NVIDIA Blog: Deploy Self-Evolving Agents with Hermes Agent and NemoClaw
- 5GitHub: nesquena/hermes-webui — why-hermes.md
- 6GitHub: lfnovo/open-notebook
- 7Omid Saffari: NotebookLM Alternatives 2026
- 8GitHub: supermemoryai/supermemory
- 9Supermemory Blog: Best Memory APIs for Stateful AI Agents 2026
- 10Reddit r/hermesagent: Memory Providers — I tested them all
- 11GitHub: Open-LLM-VTuber/Open-LLM-VTuber
- 12GitHub: pbakaus/impeccable
- 13GitHub: pbakaus/impeccable PRODUCT.md
- 14GitHub: mvanhorn/last30days-skill
- 15GitHub: Panniantong/Agent-Reach
- 16GitHub: nesquena/hermes-webui
- 17Can Bölük: The Harness Problem
- 18GitHub: can1357/oh-my-pi
- 19knightli.com: What is oh-my-pi?
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.