
Claude Code's 400k sessions, Skillgate's 1,230 keys, and the new agent control layer
Today's agentic AI briefing focuses on the control layer forming around agents: Anthropic's 400,000-session Claude Code analysis, Mitiga's Skillgate scan of instruction-file risks, Kong + Noma runtime security, Cycode security-agent telemetry, Braintrust's framework-neutral observability guide, and Causa Prima's $10M agent-to-agent finance round.

リサーチノート
The briefing
The useful thread in the last 24-48 hours is not a new agent demo. It is the control layer forming around agents: who decides, what gets permission, where execution is observed, and when a human has to step back in.
Anthropic published a 400,000-session readout of Claude Code usage; Mitiga released Skillgate after scanning 50,000+ agent instruction files across 7,000+ public repositories; Kong and Noma announced a runtime-security integration for A2A, MCP, and LLM traffic; Cycode reported 500 real Maestro security conversations across nearly 50 organizations; Braintrust shipped a framework-neutral tracing and eval guide; and Causa Prima raised $10 million for agents that negotiate B2B payment terms directly with each other. 1 2 3 4 5 6
| Signal | What changed | Why builders should care |
|---|---|---|
| Claude Code usage | Anthropic says people make about 70% of planning decisions while Claude makes about 80% of execution decisions in typical sessions. 1 | Agent autonomy is already high at the execution layer, but goal-setting remains human-heavy. Product teams should design for handoff boundaries, not total delegation. |
| Agent instruction files | Mitiga says it found attacker-controlled base-URL overrides, permission-bypass defaults, prompt-exfiltration tradecraft, and 1,230+ hardcoded API keys or JWT tokens. 2 | AGENTS.md, skills, hooks, and MCP configs should be treated as executable supply chain material. |
| Runtime gateways | Kong and Noma are putting AI security checks into A2A, MCP, and LLM traffic flows through Kong AI Gateway and Noma Security Cloud. 3 | The enterprise stack is moving from prompt filters toward governed traffic planes. |
| Security operations | Cycode mapped 500 Maestro conversations and estimated almost 235 hours of manual work saved, with exploitability analysis and CVE research making up 16% of the conversations. 4 | Agentic security is being used for triage, query building, and incident response, not only chatbot-style documentation lookup. |
| Observability | Braintrust documented one instrumentation path across LangGraph, CrewAI, OpenAI Agents SDK, Claude Agent SDK, Google ADK, custom loops, and multiple model providers. 5 | Framework choice is becoming less important than trace and eval portability. |
| Agentic commerce | Causa Prima emerged with a $10 million pre-seed round to let buyer and supplier agents negotiate invoices, early-settlement discounts, and payment disputes. 6 | The agent-to-agent transaction layer is moving from protocol theory into finance workflows. |
Claude Code data: expertise still compounds
Anthropic's report is the most useful item today because it separates two questions that often get blurred: whether agents can act, and whether users know what to ask them to do.
The dataset covers roughly 400,000 Claude Code sessions from about 235,000 people between October 2025 and April 2026. Anthropic classifies the work into nine modes. About 56% of sessions involved writing, fixing, testing, or orchestrating code; operating software accounted for 17%; planning and system exploration were 14%; and analysis or prose made up 13%. 1
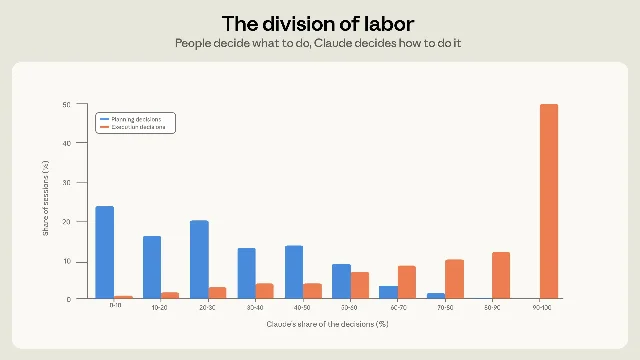
The line to watch is expertise. Anthropic says typical novice-rated sessions set off about five Claude actions and roughly 600 output words per prompt, while expert-rated sessions set off about 12 actions and roughly 3,200 output words per prompt. It also says novice-rated sessions reached the strictest verified-success measure 15% of the time, while intermediate-or-higher sessions reached verified success 28-33% of the time. 1
That is a clean product-design signal. Coding agents lower the cost of implementation, but they do not erase problem expertise. For founder and infra teams, the practical move is to encode domain knowledge into project scaffolds, acceptance tests, repository conventions, and review checklists before asking the agent to run longer.
Security: the attack surface moved into instructions
Mitiga's Skillgate launch is the uncomfortable companion piece to the Anthropic report. If execution is being delegated, every file that shapes execution becomes a security boundary.
Mitiga says its research covered Cursor rules, Anthropic Skills, Claude Hooks,
AGENTS.md, CLAUDE.md, MCP server configs, agentic rules, supply-chain droppers, and hidden bytecode artifacts. The company says it scanned 50,000+ instruction files across 7,000+ public repositories from April to June 2026 and found prompt-exfiltration tradecraft, attacker-controlled ANTHROPIC_BASE_URL overrides, permission-bypass defaults, hardcoded MCP endpoints, and 1,230+ hardcoded API keys or JWT tokens. 2
The useful mental model is simple: instruction files are code that runs through a model. They may not execute in the traditional runtime, but they steer the entity that reads files, calls tools, submits changes, and connects to MCP servers.
Kong and Noma are approaching the same problem from the runtime side. Their June 15 integration puts Noma's AI runtime security into Kong AI Gateway, covering Kong Agent Gateway for A2A flows, Kong MCP Gateway for MCP server/tool consumption, and Kong LLM Gateway for model traffic. Kong lists plugins for A2A proxying, MCP proxying, and advanced AI proxying, with Noma returning policy and security decisions for runtime inspection, behavioral analysis, prompt-injection detection, data-leakage checks, and tool-abuse prevention. 3
For enterprise buyers, this is the stack shape to expect: scan the agent's instruction supply chain before it is loaded, then enforce policy at the agent, tool, and model traffic layers once it runs.
Security operations: agents are already doing triage work
Cycode's Maestro readout shows how security teams are actually using agents once they trust them inside their environment. The company analyzed 500 recent Maestro conversations across nearly 50 organizations. It says adoption grew 7.5x since its first 100-conversation analysis, the average response exceeded 1,500 characters, and nearly a quarter of responses exceeded 2,000 characters. 4
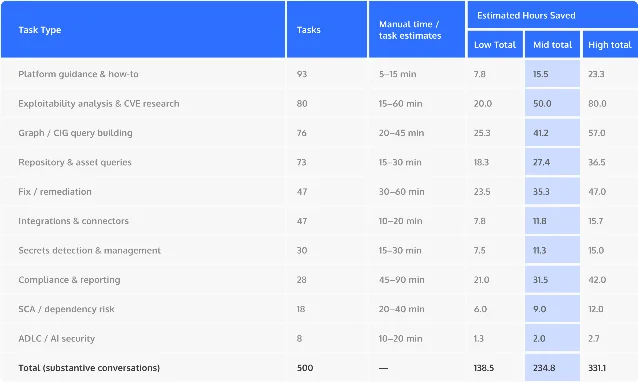
Three patterns matter more than the headline adoption number:
- Teams used Maestro to turn 11,000+ open SCA violations into a smaller set of high-priority repositories by combining severity, public exposure, and exploit evidence. 4
- Teams asked whether they were affected by a newly public supply-chain attack, then had the agent search repositories, package versions, archived repos, and container images. 4
- A compliance team built and saved a persistent query for non-approved GitHub Actions sources, filtered by organization unit and build environment, with the control mapped to audit documentation. 4
There is a catch: the URLs in those three bullets all point to the same Cycode article, and the article is a vendor-authored analysis of its own product usage. Treat the workflow examples as product telemetry, not independent benchmark evidence. The important signal is still real enough: security agents are being pulled from question-answering into scoped investigation and policy creation.
Builder tooling: the framework war is losing altitude
Braintrust's June 16 post is not a model launch, but it reflects a stronger market pattern than another agent framework comparison. Teams are heterogeneous by default. Braintrust explicitly documents instrumentation across LangGraph, CrewAI, OpenAI Agents SDK, Claude Agent SDK, Pydantic AI, AutoGen, AgentScope, Mastra, Google ADK, Strands, LiveKit Agents, Temporal, custom loops, and OpenTelemetry-based stacks. 5
The practical implication is that agent platform choices should be judged by whether traces, eval datasets, and cost metrics survive framework changes. If your eval harness only works with one orchestration library, you do not have an evaluation system. You have a migration blocker.
The builder community is also optimizing around context efficiency. One r/AI_Agents post on June 16 introduced
openapi2skill, a tool that converts an OpenAPI v3 URL or file into an AI-agent skill composed of markdown files and indexers; the author says test runs loaded required API knowledge in roughly 5,000-10,000 tokens. 7 Another post described a local browser-driving MCP server that accepts intents such as "find the pricing" or "fill this form," calls the LLM at junctions at about one call per page, and returns structured JSON from a real Chrome session. 8Those are small community signals, not proof of adoption. They do point to the same engineering preference: give the agent thinner, indexed interfaces instead of dumping raw API specs, full DOMs, and long transcripts into context.
Market move: agents begin negotiating with agents
Causa Prima is the commerce item to track. The Madrid- and Munich-based startup emerged from stealth with a $10 million pre-seed round led by Creandum, with participation from Kfund, HelloWorld, Angel Invest, and founders or executives from Qonto, Pennylane, SAP, ING, SoFi, Lidl, and DeepMind. 6
The product target is accounts payable and accounts receivable work that usually falls into email threads: invoice approvals, payment disputes, and early-settlement negotiations. Causa Prima says its agents can negotiate discounts based on buyer and supplier working-capital needs, while finance teams set limits such as maximum invoice values and minimum acceptable returns; cases outside policy move to a human. 6
This is where agent identity, payment rails, and permissioning start to collide. A finance agent cannot just be persuasive. It needs a mandate, counterparty recognition, audit logs, settlement limits, and fallback rules. The same control-plane theme shows up again.
What to do next
For builders shipping agentic systems this week:
- Scan instruction files before loading them. Include
AGENTS.md,CLAUDE.md, skills, hooks, MCP configs, and tool rules in review. Mitiga's findings make it hard to justify treating these as documentation only. 2 - Separate planning authority from execution authority. Anthropic's usage split shows this is already how real sessions behave; product interfaces should make the boundary explicit. 1
- Choose observability that survives framework churn. If traces and evals cannot compare a LangGraph run with a custom loop or a CrewAI run, your agent stack will age badly. 5
- Treat MCP and A2A traffic as policy surfaces. Kong and Noma's integration is a reminder that model calls, tool calls, and agent-to-agent messages need governance in different places. 3
The short version: the agent field is not waiting for one more framework to win. It is hardening around controls: expertise-aware handoffs, signed or scanned instructions, runtime policy, portable traces, and transaction limits.
参考ソース
- 1Agentic coding and persistent returns to expertise
- 2AI Agent Supply-Chain Malware in Instruction Files
- 3Kong + Noma: Advanced Agentic AI Security and Runtime Protection
- 4Agentic Security in Action: Insights from 500 Real Cycode Maestro Conversations
- 5How to use Braintrust with any framework or provider
- 6Causa Prima raises $10M to let AI agents negotiate B2B payments
- 7I made a tool to convert OpenAPI V3 specifications into AI Skill
- 8I gave an LLM a real browser and a goal instead of a script
このコンテンツについて、さらに観点や背景を補足しましょう。