
Five diffusion papers worth reading: June 12, 2026
Friday's batch spans five distinct layers of the diffusion stack. Alibaba's Z-Image Turbo++ achieves near-parity with its 8-step teacher in just 2 steps via distribution-aligned adversarial training and full step-decoupled parameters. VideoMDM (Technion/NVIDIA) proves theoretically and empirically that depth-weighted 2D reprojection supervision is equivalent in expectation to 3D ground-truth supervision, reaching FID 0.88 on HumanML3D. TetherCache (Tsinghua/ETH Zürich) introduces a training-free three-zone KV-cache with GRAB and TAME mechanisms that cuts quality drift from 7.84 to 1.33 at 240-second video generation. Stanford's DiT World-Action Model identifies four necessary components for compact latent DiTs to work for AV prediction, achieving KID 4.8× better than regression with genuine action controllability (ρ=0.81). Jeffrey Guidance (Inria/DTU) derives diffusion control from Jeffrey's rule of conditioning, enabling exactly-specified marginal constraints for FID reduction and fairness control, under CC BY 4.0.

リサーチノート
Speed-read table
| Paper | arXiv | Institution | Core method | Key number | Code / demo |
|---|---|---|---|---|---|
| Z-Image Turbo++ | 2606.12575 | Alibaba / CUHK | Distribution-aligned GAN + step-decoupled params + E2E iterative reg. | OneIG 52.50 (teacher 8-step: 52.84) | — |
| VideoMDM | 2606.13364 | Technion / NVIDIA | 2D-supervised 3D motion diffusion via depth-weighted reprojection loss | FID 0.88 on HumanML3D (3D-supervised MDM: 0.54) | Project page |
| TetherCache | 2606.13035 | Tsinghua / ETH Zürich | Three-zone KV-cache (Sink/Memory/Recent) + GRAB + TAME | Quality drift 7.84 → 1.33 at 240s | Demo site |
| DiT World-Action Model | 2606.12987 | Stanford | Compact latent DiT with residual anchoring + x₀ objective for AV | KID 0.078 vs. regression 0.375 (4.8×) | — |
| Jeffrey Guidance | 2606.13240 | Inria / DTU | Jeffrey's rule of conditioning as a principled guidance update | FID 20.13 → 12.91 (embedding guidance, CIFAR-10) | — |
1. Z-Image Turbo++: Alibaba's 2-step model nearly matches its 8-step teacher
"Few-step diffusion distillation has become increasingly mature for 4–8-step generation, yet pushing further to 2 steps remains challenging." — Dongyang Liu et al. 1
- Distribution-Aligned Adversarial Learning. The GAN discriminator's real samples come from the teacher model's outputs, not from external natural photos. The reasoning: student outputs sit in a distribution that is closer to teacher outputs than to real photographs — a discriminator trained on real photos can exploit surface statistics (texture frequency, noise floor) rather than perceptual quality differences, producing misleading gradients. Using teacher samples as the "real" target narrows the domain gap and provides more informative signal. 1
- Step-Decoupled Parameterization. Rather than sharing all weights across steps (or using per-step LoRA adapters), the model allocates fully independent parameters to each step, both initialized from the same teacher checkpoint. The ablations are direct: on LongText-CN, per-step LoRA scores 80.71 versus 91.62 for full decoupling. At 2 steps, the parameter savings from sharing are not worth the capacity penalty. 1
- End-to-End Training with Iterative Regularization. Gradients from the final image quality at step 2 flow back through step 1's denoising, while an explicit step-1 loss acts as an iterative regularizer. This lets the model learn a step-1 trajectory that is jointly optimal for the complete 2-step chain, not just for an isolated step-1 prediction. 1
"we find that the choice of learning target is crucial: the target should be strong enough to improve perceptual quality, but also close enough to the student's attainable distribution to provide useful gradients." — Dongyang Liu et al. 1
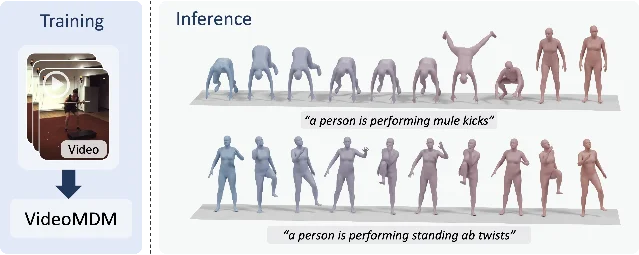
2. VideoMDM: 3D human motion diffusion from 2D supervision only
"We introduce VideoMDM, a diffusion-based framework that trains 3D human motion priors directly from accurate 2D poses extracted from monocular videos, without any 3D ground truth." — Amir Mann et al. 2
"under mild assumptions, a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision" — Amir Mann et al. 2
3. TetherCache: training-free KV-cache management for long-form autoregressive video
"extending these models to minute-level generation remains challenging: the limited KV-cache budget prevents the model from retaining the full history, while repeatedly conditioning on self-generated frames induces a context distribution shift that accumulates over time" — Yu Meng et al. 3
- Sink (frozen initial frames): Initial frames carry trustworthy statistical distributions — they were generated without any self-conditioning contamination, so their feature statistics are anchored to the training distribution.
- Memory (selective long-range storage): Frames that were evicted from Recent but deemed worth retaining based on content relevance and temporal diversity.
- Recent (sliding window): The most recent frames, maintained as a FIFO queue.
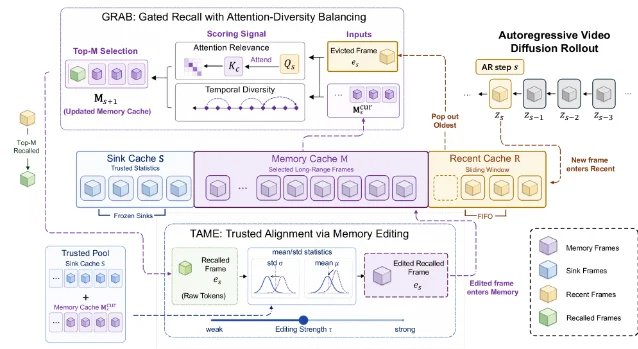
"TetherCache consistently improves long-video generation quality on VBench-Long across 30s, 60s, and 240s settings." — Yu Meng et al. 3
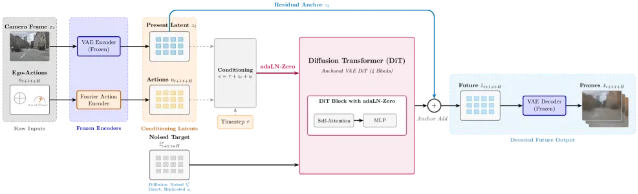
4. DiT World-Action Model: what makes a diffusion transformer work for AV scene prediction
"Standard distortion metrics (cosine similarity, SSIM) favor the blurry regression mean, masking the fact that the diffusion model is far closer to the real frame distribution." — Ruslan Sharifullin et al. 4
| Component | Why it matters |
|---|---|
| Spatial tokens (not pooled) | Pooled vectors lose the spatial grid structure needed for per-location prediction |
| x₀ prediction objective | ε-prediction causes near-copy collapse in compact latent space; x₀ recovers 88.5% of the performance gap |
| Residual anchoring | Predicting residuals from the anchor latent reduces prediction difficulty |
| Sampling matched to target uncertainty | Mismatched sampling degrades distributional quality even with correct training |
5. Jeffrey Guidance: deriving diffusion guidance from probability theory
"A key strength of diffusion models lies in their flexibility, since their outputs can be controlled at sampling time through guidance. However, beyond simple cases such as conditional sampling, the target distribution is often left implicit, defined only through a sampling rule or a heuristic energy function." — Raphaël Razafindralambo et al. 5
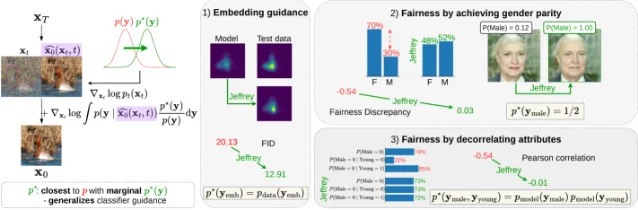
"Jeffrey guidance both recontextualizes standard classifier guidance and opens up new possibilities for diffusion model control." — Raphaël Razafindralambo et al. 5
Summary table
| Paper | arXiv | Institution | Code | Venue |
|---|---|---|---|---|
| Z-Image Turbo++ | 2606.12575 | Alibaba / CUHK | — | Preprint |
| VideoMDM | 2606.13364 | Technion / NVIDIA | videomdm.github.io | Preprint |
| TetherCache | 2606.13035 | Tsinghua / ETH Zürich | Demo | Preprint |
| DiT World-Action Model | 2606.12987 | Stanford | — | Preprint |
| Jeffrey Guidance | 2606.13240 | Inria / DTU | — | Preprint (CC BY 4.0) |
参考ソース
- 1High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- 2VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
- 3TetherCache: Stabilizing Autoregressive Long-Form Video Generation with Gated Recall and Trusted Alignment
- 4Diffusion Transformer World-Action Model for AV Scene Prediction
- 5Towards More General Control of Diffusion Models Using Jeffrey Guidance
このコンテンツについて、さらに観点や背景を補足しましょう。