Claude Code does not erase expertise. Anthropic's new study says it compounds it
Anthropic's June 2026 Claude Code study finds that agentic coding shifts execution to Claude while leaving planning, validation, and recovery with the user. The article breaks down the 400,000-session dataset, the division of labor, the returns to task-specific expertise, and why non-software occupations can succeed when they bring strong domain judgment.

The study is about control, not just coding speed
Anthropic's June 16, 2026 research post, 「Agentic coding and persistent returns to expertise」, is one of the more useful Claude Code studies because it does not ask whether an agent can write code in the abstract. It asks what happens when people repeatedly steer Claude Code through real interactive work. The dataset is large: Anthropic analyzes roughly 400,000 Claude Code sessions from about 235,000 people between October 2025 and April 2026, using privacy-preserving transcript analysis and telemetry checks. 1
The headline result is not that coding expertise disappears. It is narrower and more interesting: formal software occupations appear to matter less than task-specific domain expertise. In Anthropic's framing, the user still decides what should be built, what counts as done, and when the agent has misunderstood the problem; Claude increasingly decides how to execute that plan. 1
That distinction matters for anyone using Claude Code as more than autocomplete. The study suggests that the bottleneck is shifting from typing implementation details to specifying intent, validating output, and recovering when the agent gets stuck. In other words, the tool can absorb implementation labor, but it does not yet supply the judgment that makes a task well-posed.
What Anthropic measured
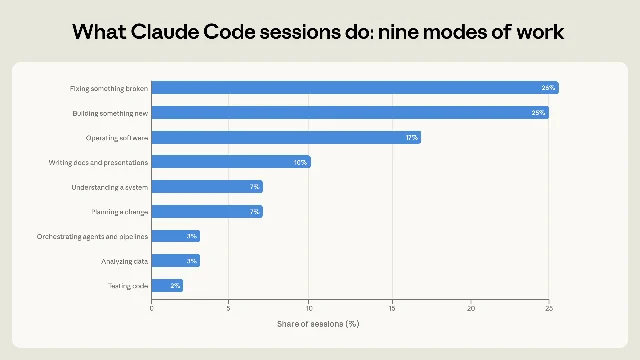
Anthropic classifies each Claude Code session into nine work modes. About 56% of sessions involve directly writing, fixing, testing, or orchestrating code: 25% building something new, 26% fixing broken code, and 5% testing or orchestrating agents and pipelines. Operating software accounts for 17%, planning or understanding systems for 14%, and analysis or prose for 13%. 1
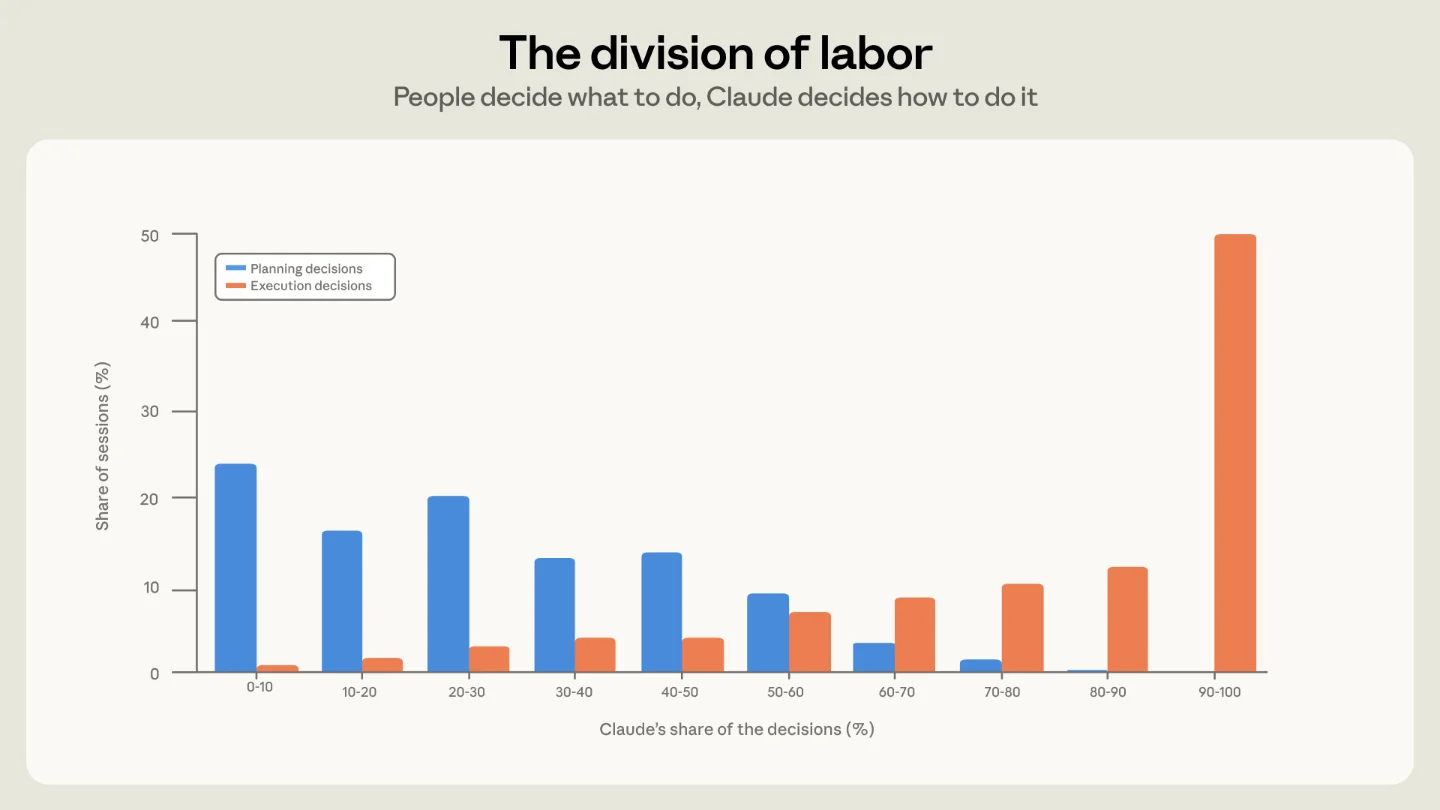
The study also separates planning decisions from execution decisions. Planning covers what to do, which approach to take, and what counts as completion; execution covers which files to change, what code to write, what commands to run, and related implementation choices. On average, users make about 70% of planning decisions while Claude makes about 80% of execution decisions. 1
That is the study's most important conceptual move. If one only measures how many commands Claude runs or how much code it edits, Claude Code looks increasingly autonomous. Anthropic's earlier autonomy work already examined how long Claude Code runs and how often users approve actions automatically. 2 This new study adds a second axis: who is making the substantive decisions.
In a typical session, Anthropic reports roughly four user-Claude turns. Each prompt triggers about 10 Claude actions on average, sometimes more than 100, and Claude writes about 2,400 words of output per turn. 1 That is enough agency to make the user a manager of work, not a line-by-line driver of work.
Expertise compounds the agent's output
Anthropic rates the user's apparent task-specific expertise on a five-point scale from novice to expert. The classifier looks for signals such as how precisely a user frames instructions, what the user asks Claude to verify, and whether the user corrects Claude or Claude corrects the user. A senior engineer asking a first Rust question can be a beginner at that task; a non-programmer accountant who specifies month-end reconciliation rules and catches edge cases can be an expert at that task. 1
The gradient is visible before outcomes are even measured. In novice-rated sessions, each prompt produces about five Claude actions and roughly 600 words of output. In expert-rated sessions, the chain is more than twice as long, about 12 actions, and the text output is roughly five times as large at 3,200 words. Anthropic says the upward trend remains statistically significant after controlling for work mode, task value, month, occupation, and model family, with estimated gains of 9% more actions and 13% more output per expertise level. 1
This is the strongest evidence for the 「compounding」 interpretation. Experts do not merely ask harder questions. They appear to give Claude enough structure to safely do more between check-ins. The better prompt is not a magic phrase. It is a compressed representation of domain knowledge: constraints, edge cases, known failure modes, and a sharper test of whether the answer is useful.
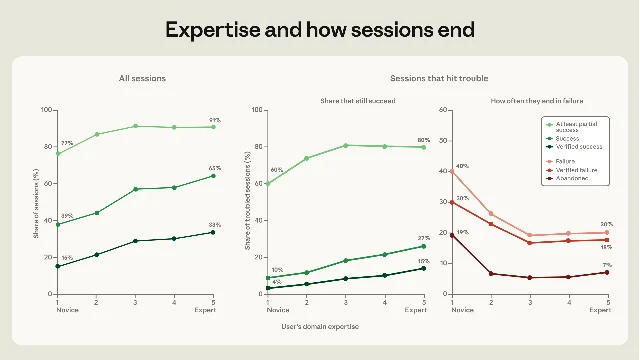
The outcome results follow the same pattern. Anthropic excludes sessions with no clear goal, about 7.7% of the full sample, then compares outcomes using transcript-based success classifiers and hard signals such as commits, pull requests, passing tests, and explicit user affirmation. 1 Novice-rated sessions reach verified success 15% of the time and at least partial success 77% of the time. Intermediate and higher sessions reach verified success 28% to 33% of the time and partial success 91% to 92% of the time. 1
The gap is especially revealing when sessions hit trouble. Among troubled sessions, verified success rises from 4% for novices to 15% for experts. At least partial success rises from 60% for novices to 80% to 81% for intermediate through expert sessions. Novice troubled sessions are also much more likely to be abandoned: 19% end as failures with zero lines of code written, compared with 5% to 7% for everyone else. 1
Software occupation is not the whole story
The study's occupational result is easy to overstate, so it should be read carefully. Anthropic infers occupation from project context, file names, artifacts, and vocabulary, and explicitly tells its classifier not to treat the act of coding itself as evidence of a software job. Occupation can be inferred in about 70% of sessions. 1
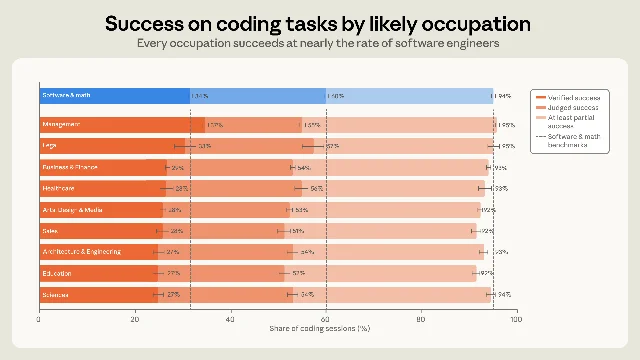
In the inferred set, software-related occupations still lead on strict measures. People in software-related occupations reach verified success in about 30% of sessions overall, compared with about 26% for other professions. In sessions that produce code, the gap is 34% versus 29%. 1
But under the looser 「at least partial success」 measure, the gap nearly disappears. In code-producing sessions, software-related users and non-software users reach partial success at 89% and 88%, respectively, and every one of the ten largest occupational groups lands within seven percentage points of software and math users on success. 1
This does not mean a lawyer, scientist, analyst, or manager suddenly has the full skill set of a senior engineer. It means that, for many bounded tasks, the agent can supply enough implementation capability that the user's real advantage becomes the ability to specify and evaluate the work. That matches Anthropic's internal-work study, where employees reported using Claude for a large share of their work and described productivity gains, while the researchers emphasized that AI changed task composition rather than simply replacing workers. 3
The result also fits Anthropic's May 2026 social-science coding-agent study, which found uneven adoption: 81% of surveyed social scientists had tried AI chatbots, but only 20% had adopted coding agents, with adoption higher among top-university researchers and male-name researchers. 4 The Claude Code expertise paper suggests why that adoption gap matters. If domain knowledge compounds agent output, then access and confidence gaps can turn into productivity gaps.
The limits are as important as the result
Anthropic is unusually explicit about what the study cannot show. It does not observe whether code from a session is later used, discarded, deployed, or economically valuable. It excludes non-interactive usage, including third-party IDE integrations, SDK usage, and headless CLI sessions. It also relies on model classifiers reading long transcripts, which Anthropic says are hard to validate at scale even when checked against telemetry and reference models. 1
Those limits should make the result more credible, not less. The paper is not a universal claim that domain experts now dominate software production. It is an early measurement framework for a specific surface, Claude Code in interactive use, over a seven-month period.
The most actionable takeaway is therefore conditional. If the pattern holds, Claude Code will reward people who can turn messy professional knowledge into precise tasks, testable constraints, and informed supervision. Coding syntax becomes less central. System understanding, taste, verification, and domain judgment become more central.
Two watchpoints follow from Anthropic's own conclusion. First, if the return to expertise decreases over time, models may be starting to supply more of the judgment that users currently provide. Second, if non-software occupations continue to succeed at more coding tasks, software production may become a normal part of many jobs rather than a specialized output of one occupational group. 1
For now, the study's message is disciplined: Claude Code is doing more execution, but the user still carries the problem. The advantage goes to people who know what they are trying to make true.
このコンテンツについて、さらに観点や背景を補足しましょう。