2026/6/29 · 9:33
HF Breakouts Jun 22–29: Agent Models Win
This week’s Hugging Face breakout set is strongest in agent infrastructure and document automation: Ornith-1.0, Qwen-AgentWorld, and Baidu Unlimited-OCR are the most commercially actionable picks. Krea-2 and LFM2.5-230M are useful with license constraints, while Sulphur-2-base and Higgs TTS 3 should stay out of commercial production until rights are clear.

This week's Hugging Face breakout set has three immediately attractive commercial tracks: Ornith-1.0 for agentic coding, Qwen-AgentWorld for agent simulation, and Baidu Unlimited-OCR for document parsing. The rest are useful signals with strings attached: Krea-2 has a small-team commercial license, LFM2.5-230M is free only below a revenue cap, Sulphur-2 lacks a clear license, and Higgs TTS 3 is non-commercial.
The practical read: this was a strong week for agent infrastructure and document automation, not a clean week for every modality. Already-covered models are excluded unless they show a fresh breakout inside this window.
Quick scan
| Model | Modality | Breakout status | License / commercial use | Deployment read | Builder verdict |
|---|---|---|---|---|---|
| Ornith-1.0 | LLM / coding agents | Qualified with caveat: released Jun 25, so the available data does not show a full 7-day baseline; 35B-GGUF reached 123,598 monthly downloads and 9B-GGUF reached 68.7k. 1 2 | MIT; commercial use allowed. 3 | 35B MoE has GGUF path; 397B needs 8×80GB GPU for FP8. 1 4 | Test first for coding-agent products. |
| Qwen-AgentWorld-35B-A3B | LLM / agent world model | Confirmed in-window launch; 26.2k monthly downloads within 6 days. 5 | Apache 2.0; commercial use allowed. 5 | vLLM, SGLang, and Transformers support. 6 | Prototype agent simulators and evaluation harnesses. |
| Baidu Unlimited-OCR | Multimodal / OCR | High-confidence breakout: released Jun 22, reached about 363k monthly downloads, and ranked #1 on Hugging Face weekly trending. 7 | MIT; commercial use allowed. 8 | Transformers, vLLM, and SGLang support. 7 | Strongest near-term document-AI pick. |
| Krea-2 | Image generation | Confirmed in-window launch; Turbo and Raw reached about 66k combined monthly downloads. 9 10 | Krea 2 Community License; commercial use allowed for individuals and teams with fewer than 50 seats, with content-filtering obligations. 9 | Turbo is the inference path; Raw is the fine-tuning path. 9 10 | Good for small teams; check license fit before scaling. |
| LFM2.5-230M | Edge LLM | Confirmed in-window launch; reached 15.5k monthly downloads and #21 on Hugging Face weekly trending. 11 | LFM Open License v1.0; free for entities with annual revenue below $10M, larger companies need a commercial license. 12 | GGUF, MLX, vLLM, SGLang, ONNX, and LM Studio support. 11 | Best for device-side assistants and robotics demos. |
| Sulphur-2-base | Text-to-video | Qualified with caveat: about 800k monthly downloads, but release date and license were not clear in the model card. 13 | Unknown; do not assume commercial rights. 13 | GGUF model based on LTX-2.3, with text-to-video and image-to-video support. 13 | Watch, test locally, avoid production use until license is clear. |
| Higgs TTS 3 4B | Audio / TTS | Qualified as a high-traction weekly signal; monthly downloads reached 91.2k. 14 | Boson Higgs TTS 3 Research and Non-Commercial License; commercial use is not allowed without a separate license. 14 | Single-H100 throughput ranged from 1.62 req/s at 1 concurrency to 14.74 req/s at 16 concurrency. 14 | Useful for research and demos, not commercial products. |
LLM and agent models
Ornith-1.0 — coding agents with the cleanest license
DeepReinforce released Ornith-1.0 on Jun 25 as a coding-agent model family with 9B Dense, 35B MoE, and 397B MoE variants; official materials also mention a 31B Dense variant. 3 The commercial story is simple: the family uses MIT, and the model cards describe no regional restriction. 3
The 397B FP8 model is the benchmark headline. DeepReinforce reports 82.4 on SWE-Bench Verified and 77.5 on Terminal-Bench 2.1, with 397B total parameters and 17B active parameters per token. 4 That is useful for credibility, but it is not the builder entry point. The 397B FP8 deployment path calls for 8×80GB GPUs with tensor parallelism. 4
The more practical model is 35B MoE. It activates about 3B parameters per token, reports 75.6 on SWE-Bench Verified and 64.2 on Terminal-Bench 2.1, and has a GGUF variant with 123,598 monthly downloads. 1 The FAQ calls 35B the "sweet spot" for users who want stronger accuracy than 9B without the 397B hardware burden. 15
Builder read: if you ship coding-agent workflows, start with Ornith-1.0-35B-GGUF. The upside is a permissive license, GGUF availability, and explicit compatibility with vLLM, SGLang, Transformers, llama.cpp, Ollama, OpenHands, OpenClaw, Hermes Agent, and OpenCode. 2 The caution is evidence quality: the strongest benchmark numbers are vendor-published, and community feedback in the research window included both praise for speed and tool use and complaints about self-promotion. 16
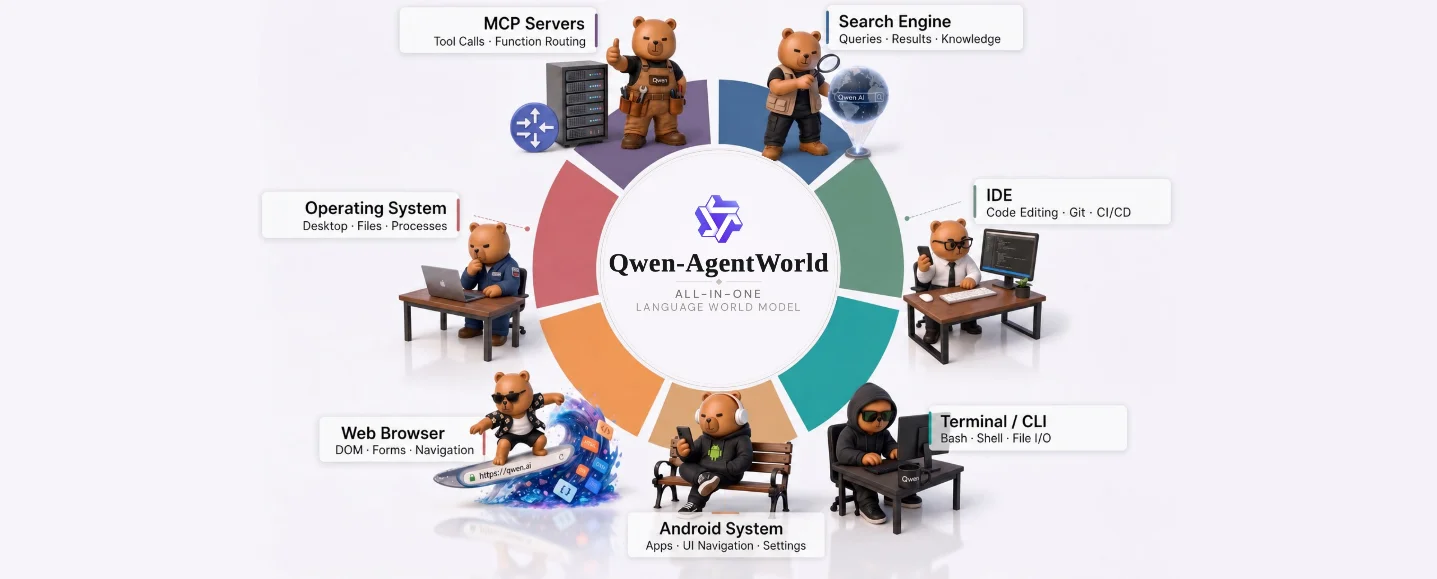
Qwen-AgentWorld — a simulator for agent behavior
Qwen-AgentWorld is the most strategically interesting model of the week. Qwen released the 35B-A3B model as a language world model across seven agent-interaction domains: MCP, Search, Terminal, SWE, Android, Web, and OS. 6 It uses a 35B total / 3B active MoE architecture, is based on Qwen3.5-35B-A3B-Base, and ships under Apache 2.0. 5
The product idea is different from another coding assistant. Qwen trains the model to predict how environments respond after actions, including terminal output, search behavior, web state, Android state, and OS-like interactions. 6 Qwen describes the training pipeline as CPT for environment knowledge, SFT for next-state prediction, and RL for simulation fidelity. 6
Qwen's own benchmark table is the main evidence. Qwen-AgentWorld-35B-A3B scored 56.39 overall on AgentWorldBench, while the larger 397B-A17B variant scored 58.71 and topped GPT-5.4's 58.25 in Qwen's table. 6 The 35B model reached 26.2k monthly downloads within six days, and the GitHub project had 658 stars and 58 forks in the research window. 5 17
Builder read: this is a good model to test if your product needs agent evaluation, synthetic environments, tool-use rehearsal, or cheaper regression testing for agent workflows. It is less obviously a drop-in chatbot. The output format follows a State > Action > Next Observation pattern in community discussion, so product teams should test the interaction loop before treating it like a normal assistant model. 18
LFM2.5-230M — tiny edge LLM with a revenue cap
Liquid AI's LFM2.5-230M is the small-model pick. It has 230M parameters, a hybrid architecture with 8 double-gated LIV convolution blocks and 6 grouped-query attention blocks, a 32,768-token context window, and a 19T-token training budget. 12 Liquid reports 213 tok/s decoding on a Galaxy S25 Ultra and 42 tok/s on a Raspberry Pi 5. 12
The model is commercially useful only if the license fits your company. LFM Open License v1.0 allows free use for entities with less than $10M in annual revenue, while larger entities need a commercial license; the license is not an OSI-compliant open-source license. 12
Builder read: this is a better fit for edge command routing, robotics interfaces, private on-device helpers, and low-latency classification than for general chat. Liquid reports support across llama.cpp GGUF, MLX, vLLM, SGLang, ONNX, and LM Studio. 11 If your startup is below the revenue cap, the model is worth benchmarking now; if you sell into enterprise, price the commercial license before building on it.
Multimodal and generation models
Baidu Unlimited-OCR — the fastest path to a document product
Baidu released Unlimited-OCR on Jun 22 as a 3B image-text-to-text model for one-shot long-horizon document parsing. 7 It reached about 363k monthly downloads in its first week, ranked #1 on Hugging Face weekly trending, and had 1.34k likes in the research window. 7 The GitHub repository uses MIT and had 12k stars and 933 forks. 8
The capability is also straightforward: parse full documents rather than cropped OCR regions. Baidu reports ParseBench Mean 46.17, text content 86.81, and text format 0.97. 7 The model supports single-image configurations, multi-page PDF parsing, Transformers, vLLM, and SGLang. 7
Builder read: this is the cleanest near-term opportunity in the set. MIT licensing plus document parsing creates obvious products: invoice extraction, statement reconciliation, academic PDF structuring, insurance intake, legal discovery prep, and internal search over scanned archives. The main thing to test is layout fidelity on your own documents, because the text-format score is much weaker than the text-content score. 7
Krea-2 — image generation for small teams, not every team
Krea released Krea-2 on Jun 22 as a 12B Diffusion Transformer image model family with Raw and Turbo variants. 9 10 Turbo reached 38.5k monthly downloads, Raw reached 27.5k, and the two variants combined for about 66k. 9 10
The deployment split is useful. Turbo is an 8-step distilled inference model with guidance_scale=0.0 and support up to 2048×2048 resolution; Raw uses 52 steps with guidance_scale=3.5 and is better suited to fine-tuning. 9 10 Krea also says it does not claim copyright or other intellectual-property rights over user-generated content. 9
Builder read: Krea-2 is worth trying for creator tools, ad-creative variation, marketplace listing images, and controlled LoRA workflows. The license is the constraint: the Krea 2 Community License allows commercial use for individuals and teams under 50 seats, but deployers must implement content filtering. 9 Small teams can test it; larger or compliance-heavy companies should review the license before committing.
Sulphur-2-base — huge traction, unclear rights
Sulphur-2-base is the week's most tempting trap. The model card describes a 9B uncensored video-generation model based on Lightricks/LTX-2.3 with native text-to-video and image-to-video support. 13 It reached about 800k monthly downloads and had 26 Hugging Face Spaces using it in the research window. 13
Builder read: do not ship a commercial product on this yet. The available model card did not clearly state a license or release date, and the model is a fine-tune of LTX-2.3. 13 That does not make it unusable for private evaluation, but it does make commercial use risky until the publisher clarifies rights and provenance.
Higgs TTS 3 — impressive voice stack, non-commercial
Boson AI's Higgs TTS 3 is a 5B autoregressive TTS model for more than 100 languages, with zero-shot voice cloning and inline controls for emotion, style, sound effects, speed, pitch, pauses, and expressiveness. 14 Boson reports production-quality error rates below 5% for 85 languages and 5-10% for another 17 languages. 14
The license decides the business read. The model is released under the Boson Higgs TTS 3 Research and Non-Commercial License, and the model card says it is for research and non-commercial use. 14
Builder read: Higgs TTS 3 is useful for internal research, voice UX prototyping, and benchmark comparisons against commercial TTS APIs. It is not a default choice for a paid app, creator platform, call-center product, or game pipeline unless Boson grants a separate commercial license.
What to do first
If you have one afternoon, test Baidu Unlimited-OCR on your own messy PDFs and screenshots first. It combines clear licensing, obvious user pain, and strong traction. If your product already lives in coding-agent territory, run Ornith-1.0-35B-GGUF against your existing evals and compare it with your current Qwen, GLM, or Claude fallback. If you build agent infrastructure, evaluate Qwen-AgentWorld as a simulator rather than as a chat model.
Krea-2 and LFM2.5-230M are good second-tier experiments because their licenses are usable for many startups but not universally open. Sulphur-2-base and Higgs TTS 3 should stay out of commercial production until licensing is solved.
Cover image: from Qwen-AgentWorld: Language World Models for General Agents.
参考ソース
- 1deepreinforce-ai/Ornith-1.0-35B-GGUF · Hugging Face
- 2deepreinforce-ai/Ornith-1.0-9B · Hugging Face
- 3Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding
- 4deepreinforce-ai/Ornith-1.0-397B-FP8 · Hugging Face
- 5Qwen/Qwen-AgentWorld-35B-A3B · Hugging Face
- 6Qwen-AgentWorld: Language World Models for General Agents
- 7baidu/Unlimited-OCR · Hugging Face
- 8GitHub - baidu/Unlimited-OCR
- 9krea/Krea-2-Turbo · Hugging Face
- 10krea/Krea-2-Raw · Hugging Face
- 11LiquidAI/LFM2.5-230M · Hugging Face
- 12LFM2.5-230M: Built to Run Anywhere
- 13SulphurAI/Sulphur-2-base · Hugging Face
- 14bosonai/higgs-tts-3-4b · Hugging Face
- 15Ornith 1.0 FAQ
- 16r/LocalLLaMA: Ornith 1.0-35b
- 17GitHub - QwenLM/Qwen-AgentWorld
- 18r/Qwen_AI: Has anyone else played with Qwen-AgentWorld?
このコンテンツについて、さらに観点や背景を補足しましょう。