When AI Designs Proteins That Work: Mark Zuckerberg, Priscilla Chan, and Alex Rives on Biohub's Open-Source Bet
On June 10, No Priors hosted Mark Zuckerberg, Priscilla Chan, and Biohub Head of Science Alex Rives. The episode covers the release of ESMFold2 — an open-source protein design engine that produced functional cancer binders in days rather than years — and why the right structure for this kind of science is a nonprofit, not a startup. The conversation also gets unusually candid about what the models can't yet do, and where the virtual cell roadmap goes next.

On the June 10 episode of No Priors, Mark Zuckerberg and Priscilla Chan joined hosts Sarah Guo and Elad Gil to talk about Biohub — not the social network, not Meta's AI stack, but the 501(c)(3) nonprofit they co-founded in 2016 to cure, prevent, and manage all human disease. 1 Their guest, Alex Rives, is Biohub's head of science and the person who has spent the last decade building the ESM family of protein language models.
The occasion was the public release of ESMFold2, ESMC, and ESM Atlas — a trio of open-source models Biohub describes as "a world model of protein biology." 2 The 56-minute conversation ranged from the mechanics of protein design to why the right institutional structure for this kind of science is a charity, not a startup.
The central claim: AI has internalized the rules of biology
Alex Rives opened with a precise statement of what the ESM models actually do. Proteins are sequences of amino acids. Evolution, acting over billions of years, has preserved sequences that work — that fold into functional shapes, bind the right targets, resist degradation. The ESM hypothesis is that if you train a language model on enough protein sequences drawn from across all life, it will learn those rules implicitly.
"What we've shown is that these models have learned such a high-fidelity world model of biology that you can design protein interfaces computationally, take them into the laboratory, and they function as predicted." — Alex Rives 2
This is a stronger claim than structure prediction. AlphaFold2 and its successors — including ESMFold2's predecessor — can predict how a known protein folds. What Rives described is generative: the model can produce new sequences for proteins that don't exist in any database and that bind specific disease targets with therapeutic-grade affinity.
Biohub ran the proof-of-concept against five targets central to cancer and immunology research: EGFR, PDGFRβ, PD-L1, CTLA-4, and CD45. The computational search took days, not the three-to-four years a traditional preclinical program would require. In lab experiments, the designed binders achieved hit rates of 36–88% for compact minibinder formats and 15–29% for antibody-derived formats. For PD-L1 — the same checkpoint that approved cancer immunotherapies like pembrolizumab block — Biohub's computationally designed binders restored T cell signaling in laboratory tests. 2

Three tools, one open platform
The release bundles three components Rives described as a "shared ecosystem":
ESMC is the underlying protein language model — trained on roughly 2.8 billion sequences spanning bacteria from deep soil to the 20,000+ protein types in the human body. It's the foundation everything else runs on.
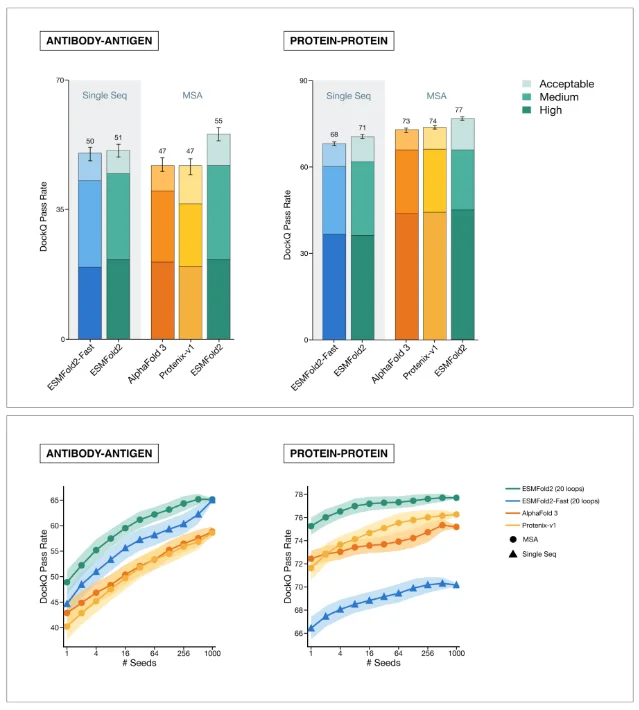
ESMFold2 is the design engine. Feed it a target protein and a desired binding property; it produces candidate binder sequences with atomic-resolution structural predictions. In benchmark tests, ESMFold2 outperforms AlphaFold 3 on antibody-antigen interaction prediction — one of the most clinically relevant but computationally hardest tasks in the field. 3
ESM Atlas applies ESMC representations to 6.8 billion protein sequences and 1.1 billion predicted structures — the largest AI-protein mapping project to date. Rives emphasized a specific capability that came up repeatedly in the conversation: ESM Atlas surfaces evolutionary connections between proteins that no existing annotation database has captured. For diseases where the underlying biology is poorly understood — which describes most rare diseases and many cancers — this makes previously unsearchable biology navigable.
All three are freely available at biohub.ai, with no commercial licensing restrictions for researchers. 2
コンテンツカードを読み込んでいます…
Why a nonprofit
This was one of the more substantive threads in the conversation. The question Guo pressed — essentially: why didn't you build a company? — got a two-part answer.
Zuckerberg's argument was institutional: the goal of curing all disease requires a long time horizon, broad talent access, and maximum knowledge sharing across the research community. A for-profit Biohub would be competing with pharma companies and AI labs for IP, incentivized to keep discoveries proprietary, and governed by quarterly pressures that don't map well onto decade-scale biology programs.
Chan's answer was more specific. She made the point that personalized medicine — treatments designed around the specific biology of an individual patient's disease — requires information that is fundamentally shared. You cannot build a world model of disease from proprietary siloes. Open science is not just a values position; it's a practical requirement for the kind of work Biohub is trying to do.
"Biohub was built on the belief that open science accelerates discovery. Making these tools freely available means researchers everywhere can move faster toward personalized cures that work for individual patients, because they target the specific biology driving their disease." — Priscilla Chan 2
The $500 million Virtual Biology Initiative announced in April was part of the same rationale: building computational infrastructure that no single company would build because it wouldn't be capturable as competitive advantage. 3
On limits: what the models can't yet do
One segment of the episode stood out for being unusually candid about the limits of current AI biology. Rives was asked about off-target effects — the core safety problem in therapeutic protein design, where a drug that binds its intended target also binds something else, causing toxicity.
His answer was careful. The computational tools can now design binders that work in a dish. They cannot yet reliably predict off-target binding at the scale needed for clinical confidence. The pipeline from "computationally designed binder that works in vitro" to "drug that passes Phase I trials" still contains several hard unsolved problems. ESMFold2 compresses the early-stage search dramatically, but it does not eliminate the development work downstream.
This matters as context for how the benchmarks should be read. The hit rates of 36–88% describe binding affinity confirmation in initial lab tests — a standard that is early in the drug discovery pipeline, not a clinical outcome measure.
What Biohub is building toward
The hosts spent the last portion of the episode asking about the roadmap. Rives described two targets.
The first is mechanistic interpretability applied to protein models: understanding not just what the model predicts, but which features it has learned to associate with specific biological functions. This is directly analogous to the mechanistic interpretability work happening in AI safety research — and Rives noted the parallel explicitly. Knowing which internal representations drive a prediction is what lets you audit it and trust it.
The second is the virtual cell: a hierarchical simulation of cell behavior where protein-level predictions compose into pathway-level predictions, which compose into cell-level predictions, which ultimately allow doctors to simulate how a specific patient's disease biology will respond to a specific treatment. Rives framed this as a multi-year project, not a near-term product. But the argument was that ESMFold2 and ESM Atlas are the protein layer of that stack, and the stack is now being assembled in order.
Zuckerberg added something worth noting: he said that when Biohub was founded in 2016, curing all human disease by the end of the century seemed like a stretch goal worth working toward. His assessment in 2026 is that the goal may have been set too conservatively.
That's the kind of claim that reads as hype when a CEO says it in an earnings call. Coming from someone who donated the land, built the labs, hired the scientists, and has been watching the protein design benchmarks come in for the last two years, it's worth taking literally.
What the episode doesn't settle
Two caveats are worth carrying forward. The first is the one Rives named: the path from in vitro binding to clinical drug is long and full of failures. Biohub's results are real and significant, but they're in early-stage discovery, and the history of drug development is full of candidates that bound beautifully in the lab and failed in patients.
The second is the comparison landscape. Isomorphic Labs, Google DeepMind's drug-discovery spinout, has raised over $2 billion to work on AI-based drug design and is not publishing its methods. OpenAI and Anthropic both have active life sciences research programs. 3 Biohub's bet on open science may prove decisive — or it may turn out that the proprietary approaches, with better feedback loops from undisclosed clinical data, pull ahead in the translation race. The episode makes a strong case for the open model but does not settle the question.
このコンテンツについて、さらに観点や背景を補足しましょう。