
2026/6/23 · 9:13
Memory 技术日报 2026-06-23:KV-aware 路由、5D serving 与 AgentCore memory
本期筛出 4 条 memory/context 工程进展:KV-cache-aware routing 正在从单机优化走向网关调度,Red Hat 把长上下文 serving 拆到 5D parallelism,Elastic + AgentCore 展示可审计双层 agent memory,GeneralCompute 给出带 RAGAS 的开源 RAG pipeline。读完可判断今天该优先排查 prefix cache 命中、长上下文 KV 预算,还是企业 agent 的记忆治理。

リサーチノート
覆盖窗口:2026-06-22 01:00 至 2026-06-23 01:00(北京时间)。今天没有把旧论文硬塞进列表,工程侧的增量更集中:KV cache 从单机优化变成路由策略问题,长上下文 serving 开始按 prefill/decode 分池思考,agent memory 则从「存一份向量」走向可审计的双层记忆。
速览
| 信号 | 时间窗依据 | memory 相关点 | 适合谁先跟 |
|---|---|---|---|
| KV-cache-aware routing 连续出现两篇工程说明 | 2026-06-22 | 把共享 system prompt、RAG chunks、多轮对话的 prefix cache 命中率,交给网关或 endpoint picker 决策;普通 round-robin 会把已算好的 KV 状态打散 1 2 | 正在横向扩 vLLM/SGLang 集群的推理平台团队 |
| Red Hat 拆解 5D distributed inference | 2026-06-22 15:01 | 把 KV cache hit rate、context parallelism、prefill/decode 分工放进同一张 serving 决策图 3 | 做长上下文、MoE、企业级推理 SLO 的平台负责人 |
| Elastic Agent Builder 接入 AWS AgentCore Memory | 2026-06-22 13:13 | 一个 agent 同时用 AgentCore 管 session/long-term extraction,用 Elasticsearch agent-memory 索引做可搜、可审计的语义记忆 4 | 做企业数据 agent、需要审计工具调用与记忆的团队 |
| GeneralCompute 发布开源 RAG pipeline 教程 | 2026-06-22 | 把 chunking、embedding、Qdrant、reranker、RAGAS 评测串成可复现流水线 5 | 还在把 RAG 从 demo 推到可评测版本的应用团队 |
KV cache 路由:今天最该看的不是压缩,而是「请求该进哪张卡」
Spheron 的文章把 GKE Inference Gateway 拆成两层:GKE 管 Envoy、负载均衡和控制面,真正的 cache-aware 决策在 llm-d Endpoint Picker 里;它会对请求的 token prefix 做 hash,记录哪个 vLLM replica 最近算过这个 prefix,并结合
vllm:kv_cache_usage_perc 选择后端 1。这类文章的价值不在「GKE 能不能用」,而在提醒平台团队:prefix caching 不是 vLLM 启一个 flag 就完事。多副本之后,普通 round-robin 会让同一段 system prompt 在 8 个 replica 上各算一遍。Spheron 给的建模场景里,8 个 vLLM replica、4K-token system prompt 下,KV-aware routing 把 repeated prefix 的 p50 TTFT 从 3.1 秒压到 0.38 秒,吞吐从 840 tokens/s 提到 2620 tokens/s;作者也明确标注这是 modeled workload estimate,不是生产实测 1。

TrueFoundry 的说法更偏产品落地:它把方案分成 session affinity、prefix-hash routing、KV-event-aware routing 三档。文中引用 llm-d 项目的 8 pods / 16 H100 benchmark,称 prefix-cache-aware routing 相比 round-robin 带来 57 倍 TTFT 改善和 2 倍吞吐;同文还提醒,如果 prompt 都是独一份,或者 prompt 很短,这套复杂度就不值得上 2。
工程判断:如果你的 agent 或 RAG 服务已经有长 system prompt、固定工具说明、重复文档块,下一步不一定是先做 KV 压缩。先把 prompt 的稳定前缀放到最前面,再量 cache hit rate;如果横向扩容后 hit rate 掉得很快,路由层才是瓶颈。
Red Hat 的 5D serving 框架:长上下文开始按阶段切预算
Red Hat 这篇更像一张 serving 决策清单。文章把现代 LLM serving 的并行维度扩到五类:tensor、pipeline、expert、data、context parallelism;其中 context parallelism 又拆成 PCP(prefill context parallel)和 DCP(decode context parallel) 3。
关键点在 DCP。Red Hat 的解释是,decode 阶段的瓶颈常常不是 FLOPs,而是 KV cache 容量和带宽;DCP 沿 sequence 维度切 KV cache,并复用 tensor-parallel 通信域,所以不需要新增 GPU。文章特别提到,对 Qwen3.5 这类 KV heads 较少的模型,普通 TP 可能复制 KV cache,DCP 可以拿回这部分 HBM,用来扩大 batch 3。
这和上面的路由信号拼在一起看,结论很直接:长上下文 serving 的优化栈正在分层。单请求太长,先看 PCP/DCP;多请求共享前缀,先看 cache-aware routing;跨节点要搬 KV,再看 LMCache、Mooncake、NIXL 这类 cache transfer/offload 方案。不要把所有问题都塞进「买更多 H100」这一列。
Agent memory:Elastic + AgentCore 给了一个可审计版本
Elastic 的新教程把一个自然语言数据分析 agent 拆成三层:Elastic Cloud 提供数据、Agent Builder MCP 和 Elasticsearch memory index;AWS Bedrock/AgentCore 负责 reasoning、runtime、session memory;Strands Agents SDK 负责把 LLM、工具和 memory 串起来 4。
它值得放进今天的 memory 日报,是因为它没有把「记忆」只当成聊天历史。文中同时使用 AgentCore Memory 和 Elasticsearch agent-memory index:前者处理 session context、summary、user preference、semantic memory 等托管记忆策略;后者把 agent 写下来的事实和偏好放进带
semantic_text 字段的 Elasticsearch 索引,方便后续 ES|QL、语义搜索、dashboard 和审计 4。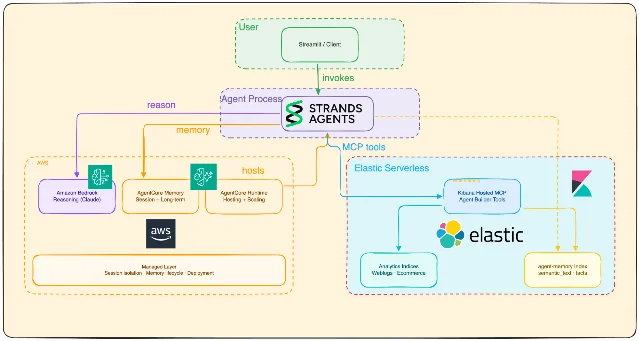
对应的 GitHub 仓库已经公开,README 显示项目使用 Strands Agents SDK、Amazon Bedrock foundation models、Elastic Cloud Serverless hosted Agent Builder MCP,并带 AgentCore Memory、可选 Elasticsearch-backed memory tools 和 Streamlit demo UI 6。
コンテンツカードを読み込んでいます…
工程判断:企业 agent memory 不只是「能想起用户偏好」。更难的是回答:这条记忆从哪来、何时写入、现在还该不该生效、有没有被后续事实 supersede。Elastic 这类架构把 memory 放回可查询、可审计的数据平面,这比单独接一个向量库更接近生产系统。
RAG pipeline:新意不大,但给了可落地的评测底线
GeneralCompute 的 RAG 教程不是新论文,也不是新框架,但它把很多团队容易跳过的步骤写完整了:先 ingest 和 clean 文档,再用 recursive character splitting 做 chunk;文中建议 factual Q&A 可从 512-token chunk 起步,summarization 可试 1024-token chunk,并用 overlap 避免句子被切断 5。
它还给了一个可执行评测口径:用 RAGAS 看 faithfulness、answer relevance、context precision、context recall;初始目标可以把 faithfulness 放到 0.85 以上、answer relevancy 放到 0.80 以上。这个数值不是行业标准,但足以逼团队别再靠「看起来答得不错」上线 5。
工程判断:如果你今天只有时间做一件事,就给现有 RAG 加一小组固定问题和 RAGAS 回归。memory 系统一旦开始自动更新索引、摘要或用户画像,没有评测就很难判断「记住更多」到底是在提高召回,还是在引入陈旧事实。
今天的工程动作
- 做推理平台:把共享 prompt、RAG chunks、few-shot examples 固定在前缀,先量 prefix cache hit rate,再决定是否上 prefix-hash routing 或 EPP 2。
- 做长上下文 serving:把 prefill TTFT 和 decode TPOT 分开看。DCP 适合先回收 decode 阶段的 KV cache HBM,PCP 适合 prefill 太长且 GPU 预算够的场景 3。
- 做企业 agent:把托管 session memory 和可查询的业务 memory 分层,不要让用户偏好、工具轨迹、事实索引混在一个黑盒里 4。
- 做 RAG:先建立 20-50 个固定问题,用 faithfulness、context precision 盯住每次 chunking、embedding、reranker 变更。没有这个回归,后面讨论长上下文还是外部记忆都容易变成玄学 5。
このコンテンツについて、さらに観点や背景を補足しましょう。