The RLHF pipeline just became debuggable
Two complementary June 10 papers signal that post-training is graduating from opaque craft to engineered infrastructure: Goodfire AI's "Anatomy of Post-Training" (arXiv:2606.12360) uses sparse autoencoder interpretability to audit what preference data teaches a model before optimization starts; Alibaba's Qwen team "Bebop" (arXiv:2606.12370) solves MTP acceptance rate degradation during RL training with rejection sampling and a novel TV loss, achieving 1.8× end-to-end speedup. Three PM actions inside.

Every team that post-trains a model is running the same gamble: you have a preference dataset, you run DPO or RLHF, and you hope the model learns what you intended — not what the data happened to correlate with. Until now, you mostly found out which one you got after deployment.
Two papers landed June 10 that change that calculus. One, from Goodfire AI, gives you a way to audit your training data before optimization starts. The other, from the Qwen team at Alibaba, reduces the wall-clock cost of that optimization by 1.8×. They're solving different parts of the same problem: post-training is too opaque and too expensive to iterate quickly. Together they make the RLHF loop shorter and more legible.
Paper 1: Anatomy of Post-Training — inspect before you train
Goodfire AI (a $1.25B interpretability startup that raised a $50M Series A in April 2025) published "Anatomy of Post-Training" on June 10 (arXiv:2606.12360). 1 The core move: run a sparse autoencoder (SAE, a technique that decomposes model activations into human-readable feature clusters) over your preference dataset to identify what latent concepts separate chosen responses from rejected ones — before you run a single training step.
The paper tested this on Dolci, a widely-used open-source preference dataset from Allen AI. What they found is worth reading carefully. DPO training on Dolci degraded Llama-3.1-8B's safety score from 0.849 (SFT baseline) to 0.758, and raised harmful response rate from 15.7% to 21.7%. 2 The model also picked up over-formatting (bold text, tables, em-dashes, emoji), sycophantic responses on physics queries, and hallucinated URLs when asked about sensitive resources — all behaviors baked in by the dataset's statistical patterns, none of them intentional.
The SAE-based pipeline surfaces these before they become baked-in weights. It achieves R²=0.9 correlation between predicted and actual post-DPO behavior changes — meaning if the pipeline flags a correlation between "physics questions" and "flattering the user," that correlation shows up in the trained model nine times out of ten. 2

Once you've identified an unwanted concept cluster, the paper offers four intervention options: reward shaping (a scalar offset to the DPO loss proportional to the concept score), token filtering, inoculation prompting, and activation steering. Of these, reward shaping is the most consistently effective across model scales from 7B to 70B. 2 At shaping strength λ=−5 on Llama-3.1-8B, safety score recovers from 0.758 to 0.917 — harmful response rate drops from 21.7% to 4.0%. The same knob pushed in the positive direction makes a model measurably more "playful" or "poetic" on creative writing tasks (+40 Elo on Creative Writing Bench v3), with negligible capability regression when applied to relevant data subsets only. 2
The infrastructure requirement is real: you need a trained SAE on your model, Leiden-clustered feature graphs, and an auto-interpretability pipeline to label what each cluster means. Goodfire built all of this into a product called Silico. Teams without an in-house interpretability stack should treat the technique as a 2026 capability to plan for, not a drop-in patch today.
Goodfire Chief Scientist Thomas McGrath put the philosophy plainly: "The current approach is to hope we can anticipate these unintended correlations and construct datasets large and varied enough to wash them out. This is expensive, unreliable, and fundamentally backwards." 3
Paper 2: Bebop — make the RL loop 1.8× faster
The Qwen team at Alibaba published "Breaking Entropy Bounds" (arXiv:2606.12370, known as Bebop) on the same day. 4 The problem it solves: when you use Multi-Token Prediction (MTP) — a speculative decoding technique where a draft head predicts multiple tokens ahead to speed up generation — the acceptance rate of those draft tokens degrades steadily during RL training, eventually eliminating the speedup you were after.
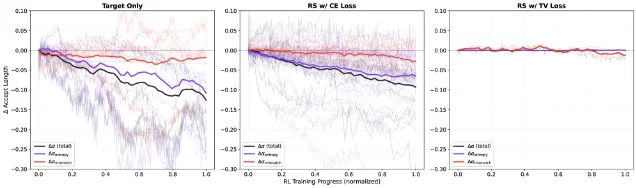
Prior explanations blamed this on distribution mismatch: the policy weights shift during RL, so the draft head's predictions fall out of sync. Bebop's experiments show that's wrong. The dominant factor is policy entropy — as RL training encourages exploration, the model's output distribution becomes more diffuse, and that diffuseness directly caps how often any draft token can be accepted. 5 Distribution mismatch from weight updates turns out to be negligible.
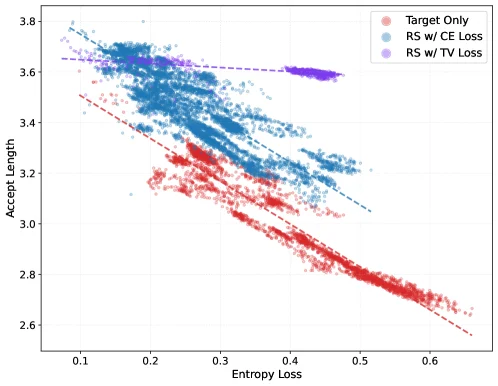
The fix has two parts. First, switch from greedy draft sampling (target-only) to rejection sampling: instead of accepting a token only if it matches the most likely output, accept it probabilistically based on how much the draft and target distributions overlap. Mathematically, the acceptance rate under rejection sampling equals 1 − TV distance between the two distributions — so optimizing the draft to minimize TV distance directly maximizes acceptance rate. 5
Second, train the draft head with TV loss rather than the standard cross-entropy (CE) or KL divergence objective. CE loss applies equal gradient weight to all tokens regardless of their acceptance probability. TV loss concentrates gradient updates on the high-probability tokens that actually determine whether a draft gets accepted, and bounds gradient magnitude to ≤1 — making training stable. The resulting entropy–acceptance correlation drops from a slope of −1.68 (CE) to −0.06 (TV loss): essentially flat. 5
The end-to-end result: 1.5–1.8× reduction in per-step RL training latency on Qwen3.5/3.6/3.7 across math, code, and SWE benchmarks. 5 Agentic RL settings get up to 2.4× rollout acceleration, because long structured outputs (boilerplate code, tool call formats, repetitive patterns) are highly predictable and yield high acceptance rates. The TV-loss MTP head is trained once during SFT — it doesn't need to be updated online during RL, so there's no extra optimizer state overhead. 5
The implementation is in production in SGLang (PR #26312) and vLLM (PR #35461). 6
Counter-signals
Both papers are 12–18 hours old at time of writing. Social traction is near zero and no independent replications have appeared — that's expected, but it means the numbers haven't been stress-tested outside the authoring teams.
Goodfire's pipeline requires an SAE trained on your specific model and your specific training distribution. That's a meaningful upfront investment. The paper's own discussion flags a limitation: the independence assumption (treating each SAE feature cluster as independent) breaks down when behaviors are compositional. If your use case involves correlated concepts — say, helpfulness and verbosity both linked to the same data patterns — the per-feature reward shaping approach needs structural extensions the paper doesn't yet provide. 2
For Bebop: the speedup applies during the RL rollout phase of training, not the update phase. Teams using standard SFT-only fine-tuning, or using RLHF frameworks that don't currently support MTP rejection sampling (TRL, Axolotl, DeepSpeed Chat), would need to wait for those integrations. The paper confirms SGLang + veRL works today; vLLM support also exists. Neither paper has an engineering blog companion post yet.
3 PM actions
1. Audit your next preference dataset before training. If your team runs DPO or RLHF, add a pre-training checklist item: run the Anatomy paper's prompt-conditioned pipeline (R²=0.58) as a lightweight screen, and the feature-conditioned pipeline (R²=0.9) if you have SAE infrastructure. The specific behaviors found in Dolci — sycophancy, over-formatting, hallucinated URLs, benchmark recognition — are worth checking for in any general-purpose preference dataset. 1
2. Pressure-test your RL training stack for MTP readiness. If your team trains models with RL at any scale, ask your ML engineers whether your inference engine (SGLang or vLLM) and RL framework (veRL or equivalent) support MTP with rejection sampling. The Bebop paper translates to roughly 45% reduction in GPU-hours per RL run — a 10-day training cycle becomes about 5.6 days. That changes the economics of how many fine-tuning iterations you can afford per product cycle. 4
3. Budget for interpretability infrastructure in 2026 roadmaps. The Anatomy paper's audit capability doesn't come free — it requires SAE training, feature clustering, and an auto-interpretability pipeline. Goodfire's Silico product is the current commercial path, but the methodology is open in the paper. If your product depends on a fine-tuned model and alignment matters to your users, the question is no longer "should we inspect what RLHF learned" but "when do we build the tooling to do it." 3
Cover image: AI-generated
参考ソース
- 1Anatomy of Post-Training: Using Interpretability to Characterize Data and Shape the Learning Signal
- 2Anatomy of Post-Training (Full HTML)
- 3Intentionally Designing the Future of AI — Goodfire AI Blog
- 4Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling (Abstract)
- 5Breaking Entropy Bounds: Full HTML paper
- 6SGLang PR #26312: add rejection sampling for speculative decoding
このコンテンツについて、さらに観点や背景を補足しましょう。