
Claude's 1M-token window changes the bottleneck from memory to retrieval discipline
Anthropic's August 2025 1M-token context beta for Claude Sonnet 4 was more than a bigger prompt window. This article breaks down what shipped, why the pricing boundary matters, how it connects to Claude Code and agentic workflows, and why Anthropic's own context-engineering guidance says bigger memory still needs stricter retrieval discipline.

A 1-million-token context window sounds like a larger inbox. For Claude, it was closer to a change in operating model: more of the system can stay visible at once, so the hard problem moves from fitting the material into the prompt to deciding which material deserves to be there.
On August 12, 2025, Anthropic gave Claude Sonnet 4 support for up to 1 million tokens of context on the Anthropic API, a fivefold increase over the 200K-token class that had defined most Claude 4 usage. Anthropic said the window could fit entire codebases with more than 75,000 lines of code, dozens of research papers, or agents carrying state across hundreds of tool calls. 1 The feature shipped first as a public beta for customers with Tier 4 and custom rate limits, with availability through Amazon Bedrock and, after an August 26 update, Google Cloud Vertex AI. 1
That narrow launch detail matters. This was not a consumer chat upgrade. It was an infrastructure feature aimed at developers building code agents, document-analysis systems, and enterprise workflows where the cost of losing state is often higher than the cost of a larger prompt.

What actually changed
Anthropic's announcement bundled three claims into one release: bigger memory, more agent continuity, and a different economic boundary for long prompts.
| Change | What Anthropic said | Why it changes the workflow |
|---|---|---|
| Context ceiling | Sonnet 4 could accept up to 1M tokens, enough for over 75,000 lines of code or dozens of research papers. 1 | Teams can try whole-system analysis before building a retrieval pipeline. |
| Agent state | Anthropic described agents maintaining context across hundreds of tool calls and multi-step workflows. 1 | Long agent runs can keep more API docs, tool definitions, interaction history, and intermediate findings visible. |
| Availability | The beta was available natively on the Claude Developer Platform, and in Amazon Bedrock and Google Cloud Vertex AI. 1 | The target user was the production developer, not just the Claude.ai chat user. |
| Price boundary | Prompts at or below 200K tokens kept Sonnet 4's $3 per million input tokens and $15 per million output tokens pricing; prompts above 200K rose to $6 per million input tokens and $22.50 per million output tokens. 1 | The larger window is available, but the product nudges users to reserve it for tasks where full context is worth the premium. |
The release also tied 1M context to prompt caching and batch processing. Anthropic said prompt caching could reduce latency and costs for long-context Sonnet 4 requests, while batch processing could add a further 50% cost saving for asynchronous workloads. 1 The pricing page explains the same basic mechanics: cache reads cost a fraction of base input pricing, and batch processing charges half of standard input and output token rates. 2 3
In plain terms: Anthropic did not make the 1M prompt a default cheap path. It made it a high-capacity path that becomes more plausible when the workload has repeated shared context, offline processing, or enough value per run to justify the larger bill.
Why this was a Claude Code move, even when Claude Code was not the headline
The launch only makes full sense beside the Claude 4 release three months earlier. Claude 4 introduced Opus 4 and Sonnet 4 as models built for coding, advanced reasoning, and agents; the same announcement made Claude Code generally available and added API capabilities such as code execution, MCP connector support, a Files API, and one-hour prompt caching. 4
That stack created a new bottleneck. Once a model can use tools, run code, inspect files, and keep working through multi-step tasks, the failure mode becomes less about answering a single prompt and more about preserving the right state across a long run. Anthropic's 1M-context examples map directly onto that failure mode: full codebases, large document sets, and agents with hundreds of tool calls. 1
This explains why Sonnet, not Opus, was the first model named in the 1M rollout. Sonnet 4 was Anthropic's practical workhorse: cheaper than Opus, strong enough for coding, and already positioned as the model that could carry everyday agentic workloads. The larger context window made Sonnet more attractive for the messy middle of engineering work, where a tool has to understand tests, documentation, prior edits, and architectural constraints at the same time.
The catch: more context is not the same as better context
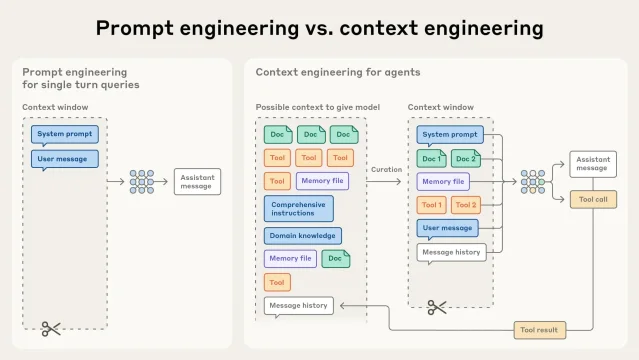
Anthropic's later documentation is unusually explicit on this point. The context-window guide defines context as the model's working memory, then warns that larger context is not automatically better because accuracy and recall can degrade as token count grows, a problem the docs call context rot. 6 The same page says Claude has strong long-context retrieval results on benchmarks such as MRCR and GraphWalks, while still emphasizing that gains depend on what is placed in context rather than on size alone. 6
Anthropic's engineering team later framed this as a shift from prompt engineering to context engineering. Their definition is broader than writing better instructions: context engineering means curating and maintaining the tokens that enter inference, including system instructions, tools, MCP connections, external data, and message history. 5 The same post argues that context has diminishing returns because models have a finite attention budget, and that strong agent performance often depends on finding the smallest high-signal set of tokens rather than stuffing everything into the window. 5
That is the real constraint hiding inside the 1M number. The bigger window reduces one kind of engineering work, because fewer tasks need aggressive chunking before the first model call. It increases another kind: deciding what to load, what to cache, what to retrieve just in time, and what to summarize or discard.
The product lesson
A 1M-token Claude is easiest to misunderstand if you imagine it as a replacement for retrieval. It is better read as a pressure valve. It lets teams start with whole-repository or whole-dossier reasoning when the task demands it, then use caching, batch processing, compaction, and targeted tool calls to keep the recurring cost under control.
Anthropic's current context-window docs show that the idea has continued beyond the original Sonnet 4 beta. As of the current model documentation, Claude Opus 4.8 and Claude Sonnet 4.6 have 1M-token context windows on the Claude API, Amazon Bedrock, and Vertex AI, while other models such as Sonnet 4.5 remain at 200K tokens. 6 The model overview also lists 1M-token context for the latest Opus and Sonnet tiers, with Opus 4.8 capped at 200K on Microsoft Foundry. 7
The August 2025 Sonnet 4 launch therefore looks like a bridge release. It took the agent-first logic of Claude 4 and gave developers a larger working surface. The enduring lesson is less flattering but more useful: once a model can remember almost everything you give it, the scarce resource is no longer prompt space. It is attention.
このコンテンツについて、さらに観点や背景を補足しましょう。