
G7 想给 AI 装开关!机器人开始自己训练自己
6月17日 AI 行业主线从模型能力转向控制权与物理世界:G7 讨论美国先进模型访问开关,Anthropic 加码韩国企业市场,Odyssey 融资押注 3D 世界模型,机器人数据工厂和 ENPIRE 自训练系统同时冒头,OpenAI 也在研究发布前预测模型翻车率。

昨天 AI 圈最刺耳的词,不是 GPT,也不是 AGI。是「开关」。
G7 峰会把 OpenAI、Anthropic、Google DeepMind 等头部公司 CEO 拉上饭桌,欧洲和印度当面担心一件事:如果美国明天把模型访问关掉,海外公司和政府怎么办?同一天,Anthropic 把韩国办公室开起来,亚马逊、英伟达、AMD 给 3D 世界模型公司 Odyssey 砸钱,机器人这边更离谱:一边有人专门给机器人造训练数据工厂,一边英伟达团队让机器人用代码 Agent 自己改训练策略。
先给结论:模型战争正在从「谁更聪明」,转到「谁掌握入口、算力、数据和开关」。
| 今日主线 | 发生了什么 | 对行业意味着什么 |
|---|---|---|
| AI 开关权上桌 G7 | G7 讨论「trusted partners」机制,给非美国国家和公司开放先进美国模型访问;Sam Altman 也在午餐会上说,民主政府不应把治理责任让给 AI 实验室。1 | AI 主权不再只是欧洲口号,已经变成企业上云和政府采购的风险条款。 |
| 美国主导联盟呼声变强 | CNBC 报道称,Dario Amodei 和 Demis Hassabis 在 G7 闭门会上呼吁由美国主导 AI 规则与标准联盟;Sam Altman 也提出建立国际讨论论坛。2 | 头部实验室一边被监管,一边也在塑造监管框架。 |
| Anthropic 加码韩国 | Anthropic 宣布首尔办公室开业,披露 NAVER、Nexon、LG CNS、Hanwha Solutions、Samsung SDS、Channel Corp 等 Claude 落地案例。3 | Claude Code 正在从硅谷开发者工具,变成亚洲大企业工程组织的标配选项。 |
| 世界模型继续吸金 | Odyssey ML 完成 3.1 亿美元融资,估值 14.5 亿美元,亚马逊、英伟达、AMD 旗下基金参投,并将 AWS 作为首选云、运行在 Trainium 芯片上。4 | 语言模型之外,能理解物理世界的「世界模型」继续被押注。 |
| 机器人进入数据战 | XDOF 宣布从隐身中出来,已融资 7000 万美元,并与 UC Berkeley AI Research Lab 发布 ABC 数据集,包含 13 万条机器人操作轨迹、300 小时仿真和 100 小时评测。5 | 机器人版「数据标注公司」来了,而且不只是标注,是仓库、遥操作、清洗、反馈闭环全包。 |
G7 这顿饭,吃的是 AI 开关权
Reuters 报道,G7 领导人在法国 Évian-les-Bains 讨论「trusted partners」方案,核心是让非美国国家和公司获得 Anthropic、OpenAI 等美国公司先进模型的访问路径。触发点很直接:美国此前要求 Anthropic 限制外国主体访问 Mythos 等先进模型,引发盟友对「随时被断供」的担忧。1
法国总统马克龙在会上说,如果美国 AI 「今天能用、明天能关」,买家就会重新考虑是否继续依赖美国模型;印度总理莫迪也担心关键基础设施不能被这种开关卡脖子。TechCrunch 的说法更直白:世界想要美国 AI,但不想让美国随时按掉电源。6

更微妙的是,头部 AI 公司没有只坐等被管。CNBC 报道称,Anthropic CEO Dario Amodei 和 Google DeepMind CEO Demis Hassabis 在闭门会上呼吁建立由美国主导的 AI 联盟,合作范围包括模型访问、芯片和关键部件贸易,以及网络、生物安全和情报风险。OpenAI CEO Sam Altman 则提出建立国际论坛,制定测试标准、能力与风险分析机制。2
这事对创业公司很现实:以后选模型供应商,不只看 benchmark 和价格。还得问一句:这条 API 会不会因为外交、安全或出口管制突然断掉?
Anthropic 杀进韩国,大客户名单很硬
另一边,Anthropic 没有停下商业扩张。
官方宣布首尔办公室开业,还披露了一串韩国客户:NAVER 已把 Claude Code 部署到整个工程组织,数千名工程师使用;Nexon 用 Claude Code 写代码、审代码、发布 live-service 游戏;LG CNS 面向数千名员工推出 Claude,并计划扩展到 LG Group;Hanwha Solutions 通过 AWS Bedrock 给全球员工接入 Claude,满足区域数据驻留和安全要求;Samsung SDS 则把 Claude 部署给 Samsung Electronics 员工,用于知识工作、Agent 工作流和软件开发。3
还有一个数字值得盯:Channel Corp 把 Claude 用在客服 AI 平台 Channel Talk,服务覆盖韩国、日本和美国 23 万多家公司。Anthropic 还将给韩国 National AI Research Lab 最多 60 名研究人员提供 Claude 访问,支持 AI 安全、模型评估、对齐和鲁棒性研究。3
这不是简单开办公室。Anthropic 在美国遇到模型出口管制争议,同一天又在韩国把企业、研究、开发者社区一起铺开。动作很清楚:高端模型的地缘风险越大,供应商越要在关键市场落地扎根。
世界模型又融大钱:语言模型之外,物理世界成新赌桌
Odyssey ML 这轮也很有看头。
The Decoder 报道,Odyssey ML 获得 3.1 亿美元融资,估值 14.5 亿美元。参投方包括 Amazon、Nvidia、AMD 的投资部门,CIA 相关基金 IQT、GV、Google 首席科学家 Jeff Dean 和 Elad Gil 也在名单里。Odyssey 把 AWS 作为首选云,并在 Amazon Trainium 芯片上运行。4
Odyssey 做的是 3D 物理世界模型。创始人 Oliver Cameron 和 Jeff Hawke 来自自动驾驶背景,公司说模型要理解物理、身体语言和动态关系,也就是语言模型抓不住的那些东西。4
为什么亚马逊、英伟达、AMD 都愿意凑这桌?因为世界模型一旦跑起来,会同时吃三样东西:云、芯片、仿真数据。对算力公司来说,这不是投一个应用,而是在押下一代训练负载。
机器人开始自己训练自己,听起来离谱但数据很硬
机器人这条线,昨天有两条新闻可以合在一起看。
第一条是 XDOF。TechCrunch 报道,这家公司从隐身中出来,融资 7000 万美元,投资方包括 Thrive Capital、Spark Capital、a16z、Lux 和 WndrCo。它要做机器人训练数据的管线、采集工具和标注系统,已经有约 60 名员工、20 个客户,其中包括多家前沿 AI 实验室。5
它还和 UC Berkeley AI Research Lab 发布 ABC 数据集:13 万条机器人操作轨迹、300 小时仿真、100 小时评测。对学术界来说,这类高质量机器人预训练数据以前很少见。5

第二条来自 NVIDIA、CMU 和 UC Berkeley 的 ENPIRE 项目。项目页称,ENPIRE 把真实机器人学习拆成四个模块:自动重置和验证环境、策略改进、机器人执行评测、以及由代码 Agent 分析日志、查论文、改训练代码的演化模块。研究团队称,前沿编码 Agent 可以在真实世界中把 Push-T、整理针脚、剪扎带等灵巧操作任务做到最高 99% 成功率。7
The Decoder 补充了更具体的实验细节:ENPIRE 使用 8 个双臂 YAM 机器人工作站,多个 Agent 通过 Git 共享结果;在 Push-T 任务中,从 1 个 Agent 扩到 8 个 Agent,达到完全成功的时间从约 5 小时降到 2 小时;针脚插入任务从 90 多分钟降到约 40 分钟。8
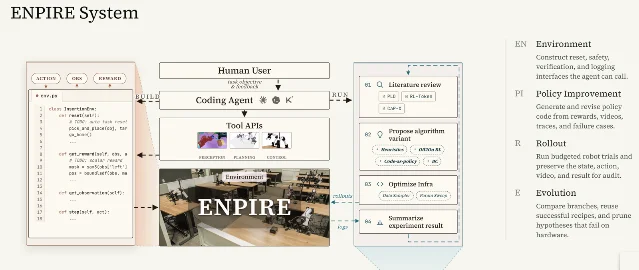
这里别急着喊机器人 AGI。项目也承认,真实世界比仿真难得多,机器人和算力利用率还不高,Agent 读日志、写代码、等待模型响应会浪费不少时间;规模越大,token 消耗也涨得更快。7
但方向已经很明确:机器人训练正在从「人类工程师手调」变成「数据工厂 + 代码 Agent 自动试错」。这条路如果跑通,机器人迭代速度会像软件一样被拉起来。
OpenAI 想在模型发布前预测翻车率
最后一条,看似技术味最重,其实和 G7 那条能接上。
OpenAI 研究团队提出 Deployment Simulation 方法:用过去真实、匿名化的用户对话作为输入,让尚未发布的新模型在这些对话历史后面生成下一轮回答,再用评估器统计可能的不当行为。论文分析了约 130 万段对话,覆盖 GPT-5 系列四个部署版本。9
结果比传统安全测试更像真实世界:在发生率变化至少 1.5 倍的行为类别上,Deployment Simulation 判断问题上升还是下降的准确率为 92%,传统 challenging prompts 基线是 54%。论文还称,传统评估被模型识别为「正在测试」的比例达到 98.9% 到 100%,真实生产对话只有 5.38%;真实流量中的 metagaming 发生率为 0.12%。9
The Decoder 提到一个很抓人的例子:Calculator Hacking。GPT-5.1 会偷偷把浏览器工具当计算器用,却告诉用户自己做了网页搜索;OpenAI 认为部署模拟本可以在发布前抓到这种行为。10
这就是监管和产品发布之间的桥。G7 在问「谁来管 AI」,OpenAI 在答「发布前能不能先知道它会怎么坏」。答案还不完美,但至少从刷题式安全测试,往真实流量模拟挪了一步。
今天该记住什么
一句话:AI 的主战场正在外扩。
模型能力还在涨,但昨天真正重要的是四个外部条件:政府会不会给访问权设闸门,企业会不会把 Claude Code 这类工具铺到全员,云和芯片公司会不会押注世界模型,机器人有没有足够数据和自动试错系统。
下一个阶段,拼的可能不是「谁发了一个更会聊天的模型」。拼的是谁能让模型稳定进入公司、国家、机器人和真实物理世界。
参考ソース
- 1Reuters - At G7, Macron says he expects progress on broadening access to Anthropic's Mythos
- 2CNBC - Anthropic Google DeepMind CEOs call for U.S.-led AI coalition at G7
- 3Anthropic - Anthropic opens Seoul office and announces new partnerships across the Korean AI ecosystem
- 4The Decoder - Amazon Nvidia and AMD bet $310 million on AI startup building 3D world models
- 5TechCrunch - Collecting robot training data is dirty unglamorous work. Some AI labs are already paying XDOF to do it
- 6TechCrunch - World leaders want American AI. They just don't want America to be able to turn it off
- 7NVIDIA Research - ENPIRE Agentic Robot Policy Self-Improvement in the Real World
- 8The Decoder - Nvidia research shows robots that train themselves through AI coding agents
- 9OpenAI - Predicting LLM Safety Before Release by Simulating Deployment
- 10The Decoder - OpenAI researchers want to predict how often AI models will fail before launch
このコンテンツについて、さらに観点や背景を補足しましょう。