NVIDIA/SkillSpector: the security scanner you should run before installing your next agent skill
NVIDIA's 18-hour-old Python CLI scans agent skills for 64 vulnerability patterns before you install them — npm audit for the skill ecosystem.

リサーチノート
Today's pick:
NVIDIA/SkillSpector — a standalone Python CLI that scans AI agent skills for 64 vulnerability patterns before you install them. Released ~18 hours ago as of this writing. 2,500+ stars, 202 forks. 1| Field | Value |
|---|---|
| Repo | NVIDIA/SkillSpector |
| Maintainer | NVIDIA (Apache 2.0) |
| Stars | 2,500+ (18 hours old, 308/day velocity) |
| Version | 2.1.3 |
| Language | Python 97.4%, YARA rules 2.2% |
| Requirements | Python ≥3.12, <3.14 |
| Install | pip install or make install via uv |
| LLM backends | OpenAI, Anthropic, NVIDIA build, local Ollama |
| Supported inputs | Git URL, zip, directory, single file |
Important framing: SkillSpector is not an agent skill in the SKILL.md sense. You cannot
npx skills add it or drop it in .claude/skills/. It's a standalone security tool you run before installing other skills — think npm audit for the skill ecosystem rather than a skill itself.What it does
SkillSpector scans a skill's files for 64 vulnerability patterns across 16 categories, assigns a 0–100 risk score, and tells you whether to install, proceed with caution, or stop. 1
The detection categories span two distinct threat classes. The first class covers traditional software risks adapted to the skill context: supply chain issues (unpinned dependencies, typosquatting, live CVE lookups via OSV.dev), behavioral AST checks (
exec(), eval(), subprocess, os.system), and YARA signature matching for malware and cryptominer patterns. The second class is specific to agentic software and has no direct parallel in traditional security tooling: prompt injection (hidden instructions, exfiltration commands, behavior manipulation), excessive agency (unrestricted tool access, autonomous decision-making, scope creep), memory poisoning, tool misuse via parameter abuse (shell=True, --force), and MCP-specific checks for tool poisoning and privilege overdeclaration. 2The risk score works on a weighted additive model: CRITICAL findings add 50 points, HIGH add 25, MEDIUM add 10, LOW add 5. Skills containing executable scripts (
.py, .sh, and similar) get a 1.3× multiplier applied to the total. 2| Score | Rating | Recommendation |
|---|---|---|
| 0–20 | LOW | Safe to install |
| 21–50 | MEDIUM | Review findings before installing |
| 51–80 | HIGH | Do not install |
| 81–100 | CRITICAL | Do not install |
コンテンツカードを読み込んでいます…
Why this exists now
The timing has a research foundation. A January 2026 paper by Liu et al. (arXiv:2601.10338) analyzed 31,132 skills from two major marketplaces. 3 The headline finding:
"Our findings reveal pervasive security risks: 26.1% of skills contain at least one vulnerability, spanning 14 distinct patterns across four categories." 3
Data exfiltration (13.3% of skills) and privilege escalation (11.8%) are the two most common patterns. Skills that bundle executable scripts are 2.12× more likely to contain a vulnerability than text-only skills (OR=2.12, p<0.001). 3
This week, a separate benchmark paper — MalSkillBench (arXiv:2606.07131, published June 5, 2026) — built a runtime-verified dataset of 3,944 malicious and 4,000 benign skills. 4 Its conclusion lands on a structural problem, not just a data problem:
"Detecting malicious skills therefore demands joint reasoning over a skill's task, code, and instructions." 4
No single scanner passes that test. The benchmark found the best-performing detector reached F1=88.6% overall but collapsed on prompt injection attacks specifically — the very attack type that's hardest to detect through static means alone.
SkillSpector ships as NVIDIA's answer to this gap. It also sits inside NVIDIA's broader verified skill pipeline, where it runs at the Scan stage before any skill receives a cryptographic signature and Skill Card.
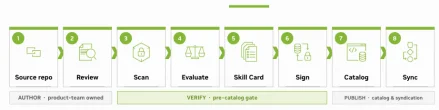
How it works
SkillSpector uses a two-stage pipeline built on LangGraph. 2
Stage 1 — Static analysis runs across 11 analyzers and fires on every scan. This covers regex-based pattern matching, AST behavioral analysis for dangerous function calls, YARA signature matching, and live CVE lookups against OSV.dev (no API key required, results cached 1 hour). High recall, moderate precision.
Stage 2 — LLM semantic analysis is optional but recommended for final decisions. This is where context gets evaluated: hidden instructions embedded in HTML comments or zero-width characters (pattern TP1), Unicode deception via homoglyphs or RTL overrides (TP2), and whether a skill's declared purpose matches its actual bundled behavior (TP4 — LLM-powered). LLM analysis filters false positives from Stage 1 and provides human-readable explanations. NVIDIA reports this brings precision to approximately 87%. 2
The LangGraph graph:
resolve_input (normalizes Git URL/zip/directory/file inputs) → build_context (builds component list, file cache, AST cache, manifest) → 20 parallel analyzer nodes → meta_analyzer (LLM filter/enhancement) → report (SARIF + risk score + report body).One important caveat: the behavioral taint tracking analyzer, all MCP-specific analyzers, and the semantic analysis nodes are currently stubs — placeholders that are not fully implemented in v2.1.3. 6 The coverage matrix NVIDIA advertises is the design target, not the current implementation.
Install steps
# Clone and set up a virtual environment (Python 3.12+ required)
git clone https://github.com/NVIDIA/skillspector.git
cd skillspector
uv venv .venv && source .venv/bin/activate # or: python3 -m venv .venv
make install # production install
# make install-dev # includes dev/test dependenciesConfigure your LLM backend (choose one): 7
# OpenAI (default model: gpt-5.4)
export SKILLSPECTOR_PROVIDER=openai
export OPENAI_API_KEY=sk-...
# Anthropic (default model: claude-opus-4-6)
export SKILLSPECTOR_PROVIDER=anthropic
export ANTHROPIC_API_KEY=sk-ant-...
# NVIDIA build (default model: deepseek-ai/deepseek-v4-flash)
export SKILLSPECTOR_PROVIDER=nv_build
export NVIDIA_INFERENCE_KEY=nvapi-...
# Local Ollama (no API costs)
export SKILLSPECTOR_PROVIDER=openai
export OPENAI_API_KEY=ollama
export OPENAI_BASE_URL=http://localhost:11434/v1
export SKILLSPECTOR_MODEL=llama3.1:8bUsage examples
# Scan a local skill directory
skillspector scan ./my-skill/
# Scan a single SKILL.md file
skillspector scan ./SKILL.md
# Scan a GitHub repo directly
skillspector scan https://github.com/user/my-skill
# Skip LLM analysis (faster, static only)
skillspector scan ./my-skill/ --no-llm
# Output SARIF for CI/CD integration
skillspector scan ./my-skill/ --format sarif --output report.sarif
# JSON output for programmatic processing
skillspector scan ./my-skill/ --format json --output report.jsonConcrete example: a Reddit user in r/mcp reported scanning about 40 local MCP tool configs and having SkillSpector flag 3 suspicious patterns. 8 That's the practical use case — not scanning skills you wrote yourself, but vetting third-party skills before they get access to your agent's tool stack.
For CI/CD, the SARIF output integrates directly with GitHub Code Scanning and other SARIF-compatible pipelines. Add a scan step before any
skills install action and gate merges on a score threshold.What production data says about its accuracy
OpenClaw integrated SkillSpector into ClawHub's ClawScan trust pipeline alongside VirusTotal and static analysis, then ran all three against 67,453 publicly available skill versions. 9
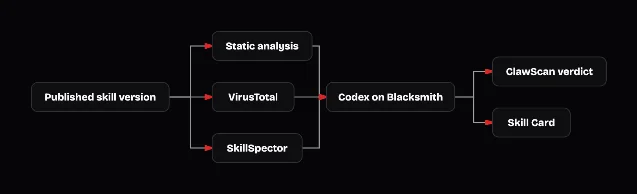
The numbers reveal a trade-off that's worth understanding before you rely on any single scanner: 9
- SkillSpector flagged 48.7% of all 67,453 skills as positive — the highest rate of any scanner
- VirusTotal flagged 7.75%; static analysis flagged 6.57%
- Jaccard agreement between any two scanners: 6.5–10.4%
- Only 468 skills (0.69%) were flagged by all three simultaneously
- 81.9% of positive findings came from a single scanner alone
The directional interpretation, per OpenClaw:
"We do not believe these findings point toward an issue with any of the individual scanners. Rather, each scanner has a different risk surface." 9
In plain terms: SkillSpector is calibrated to catch agentic risk — broad risk-surface skills — not traditional malware. Among the 206 skills ClawScan marked as definitively malicious, VirusTotal caught 72.8% and SkillSpector caught only 6.8%. 9 For catching actual malware payloads, VirusTotal is still the better tool. For catching the skill-specific attack surface — prompt injection, excessive agency, tool poisoning — SkillSpector covers ground neither VirusTotal nor generic static analysis can reach.
コンテンツカードを読み込んでいます…
Muhammad Ayan (@socialwithaayan, 69K followers) put it precisely: "This is the npm audit moment for AI agent skills. Except the ecosystem is moving faster than npm ever did and nobody had a gate until now." 10 That framing has appeared independently in Chinese, Japanese, Spanish, and Portuguese developer communities across X over the past 48 hours.
Security professionals are reading it differently. Barak Schoster Goihman (reshared by OWASP contributor Dinis Cruz on LinkedIn) wrote:
"The next major enterprise breach won't come from yet another misconfigured S3 bucket... It'll come from an AI agent skill someone installed in 30 seconds." 11
His follow-on point: traditional EDR and MDM tools were designed for binary executables, not for skills, extensions, containers, or MCP configs. SkillSpector is NVIDIA's public acknowledgment that this layer needs its own scanner.
Known limitations
Six things to know before you depend on this:
- Several analyzers are stubs. The behavioral taint tracking, MCP privilege, MCP tool poisoning, and semantic quality analyzers in v2.1.3 are not fully implemented. 6 The 64-pattern coverage number reflects the design; actual enforcement is a subset of that.
- High false-positive rate at the
suspicioustier. SkillSpector flagged 48.7% of 67,453 skills positive in the OpenClaw study. 9 Running it against any moderately complex skill library without LLM filtering will generate a lot of noise. - Weak on actual malware. As noted above: among definitively malicious skills in the OpenClaw dataset, SkillSpector caught 6.8% vs. VirusTotal's 72.8%. 9 If traditional malware delivery is your threat model, VirusTotal is the more relevant tool.
- No
pip install skillspectorone-liner yet. The current install path requires cloning the repo and runningmake install. A PyPI-published package would be more practical for CI/CD integration. - Version mismatch signal. The published version number is 2.1.3, but the public repository has only 16 commits. 1 A large pre-publication history exists, but it's not publicly visible. For a security tool, opaque version history is worth factoring into your trust model.
- No benchmark on the current version. The 86.7% precision / 82.5% recall figures from arXiv:2601.10338 describe the earlier SkillScan research framework, not SkillSpector v2.1.3 specifically. 3 Ground-truth evaluation of the current release has not been published.
When NOT to use this
Skip it if:
- Your threat model is traditional malware delivery. SkillSpector won't catch a trojanized dependency with the reliability of VirusTotal. Run both, or use OpenClaw's ClawScan which synthesizes all three. 9
- You need a fully implemented MCP audit. The MCP-specific analyzers (
mcp_least_privilege,mcp_tool_poisoning) are currently stubs. If MCP tool poisoning is your primary concern, watch the GitHub issues for when these ship. 6 - You want zero-noise CI blocking. The 48.7% positive rate on production skills means you will block legitimate installs at scale. Use
--no-llmfor fast pre-screening and reserve full LLM analysis for skills that cross a score threshold. - You need a one-command install without managing a Python environment. The current install requires
uvorvenvsetup; this isn't anpxtool.
Use it if:
- You install third-party skills regularly and have no vetting step today. Even the static analysis pass (Stage 1,
--no-llm) catches supply chain issues and AST-level dangerous patterns that no one else checks before the skill hits your agent. - You want to run NVIDIA's own verification pass locally before submitting a skill for official review.
- You're building a skill distribution pipeline or marketplace and need structured output. SARIF format plus the JSON report feed directly into Code Scanning and other automated workflows.
- You care about the agentic-specific threat surface — prompt injection, excessive agency, tool poisoning — that generic static analysis and virus scanners weren't built to detect.
Try it now
# Clone and install
git clone https://github.com/NVIDIA/skillspector.git
cd skillspector && uv venv .venv && source .venv/bin/activate
make install
# Static-only scan of a skill (no API key needed)
skillspector scan https://github.com/some-user/some-skill --no-llm
# Full scan with Anthropic backend
export SKILLSPECTOR_PROVIDER=anthropic
export ANTHROPIC_API_KEY=sk-ant-...
skillspector scan ./path/to/skill/Full repo: github.com/NVIDIA/SkillSpector
Cover image: NVIDIA/SkillSpector GitHub repository card (GitHub)
参考ソース
- 1NVIDIA/SkillSpector — GitHub
- 2SkillSpector README.md
- 3Agent Skills in the Wild: An Empirical Study
- 4MalSkillBench: A Runtime-Verified Benchmark of Malicious Agent Skills
- 5NVIDIA-Verified Agent Skills Provide Capability Governance for AI Agents
- 6SkillSpector Development Guide
- 7SkillSpector .env.example
- 8r/mcp: Been scanning MCP tool configs
- 9OpenClaw Collaborates with NVIDIA for Stronger Agent Skill Security
- 10@socialwithaayan on X
- 11Dinis Cruz LinkedIn post (Barak Schoster Goihman reshare)
このコンテンツについて、さらに観点や背景を補足しましょう。