
Five diffusion papers worth reading: June 10, 2026
Wednesday's batch: MFD's low-pass distillation theorem, Lip Forcing's 31 FPS lip sync, the first neural FM convergence theory, SSR-Merge (ICML 2026), and Flow-DPPO from Tencent.

リサーチノート
Wednesday's cs.CV + cs.LG batch (June 9–10, 2026) is theory-forward. Two papers build formal foundations for flow matching: one proves that matching expected average velocities suffices for strict distribution alignment and derives single-step distillation from it; the other establishes the first convergence, generalization, and Wasserstein guarantees for neural-network-parameterized flow matching from a Princeton-led team. On the applied side, Lip Forcing from KAIST AI delivers real-time lip synchronization at 31 FPS by distilling a 14B bidirectional video diffusion teacher into a causal student. SSR-Merge (ICML 2026) gives LoRA merging a provable OLS-optimal routing mechanism with open code. And Tencent Hunyuan's Flow-DPPO replaces ratio clipping in PPO with an exact KL divergence constraint — made tractable by the Gaussian structure of flow model policies.
Speed-read table
| Paper | arXiv | Institution | Core method | Key number | Venue |
|---|---|---|---|---|---|
| Mean Flow Distillation | 2606.11155 | Zhejiang University | Mean Flow Matching Theorem; temporal low-pass filtering of VSD noise | Single-step T2I and 4D occupancy generation | Preprint |
| Lip Forcing | 2606.11180 | KAIST AI + AIPARK | 14B→1.3B causal distillation; Sync-Window DMD + SyncNet reward | 31 FPS real-time lip sync; 17.6× faster than same-scale bidirectional | Preprint |
| A Theory on Flow Matching with Neural Networks | 2606.10089 | Princeton + Northwestern | Convergence proof for 2-layer ReLU FM; multi-task generalization bound; Wasserstein guarantees | First rigorous end-to-end theory for neural FM | Preprint |
| SSR-Merge | 2606.10617 | (9 authors, led by Zhengxuan Wei) | Subspace signal routing; rank-concatenated LoRA with inverse correlation steering | OLS-optimal; outperforms all tested baselines | ICML 2026 |
| Flow-DPPO | 2606.11025 | Tencent Hunyuan | Divergence proximal constraint replacing ratio clipping; exact KL from Gaussian flow policies | Higher rewards, stable multi-epoch RL; alleviates catastrophic forgetting | Preprint |
1. Mean Flow Distillation: a theorem-first approach to single-step flow generation
arXiv: 2606.11155 | Zhejiang University (incl. Ling Yang, Tianrun Chen, Lingyun Sun; 8 authors) | cs.CV
Peer-review status: Preprint. No public code linked.
Flow matching distillation has largely borrowed its loss functions and stability tricks from diffusion-based score matching — Variational Score Distillation (VSD) being the most prominent example. Mean Flow Distillation (MFD) argues this transfer is the root of training instability and degraded quality, because VSD's per-step variance compounds as a high-frequency signal that flow trajectories have no natural mechanism to suppress. 1
The paper's central result is the Mean Flow Matching Theorem: matching the expected average velocity — the average velocity integrated over the trajectory from source to data — is sufficient for strict distribution alignment. This is a structurally different target from score-matching distillation, which operates point-wise on the score function at individual time steps. The theoretical consequence is that MFD acts as a temporal low-pass filter over the VSD loss landscape: it suppresses the high-frequency noise that destabilizes VSD while preserving the global trajectory structure needed for generation quality. 1
"We theoretically demonstrate that MFD acts as a temporal low-pass filter, effectively suppressing the high-frequency optimization noise inherent in variational score distillation (VSD) while ensuring global trajectory consistency." — authors, via abstract 1
The paper demonstrates single-step generation on two demanding tasks: text-to-image synthesis and 4D occupancy forecasting — the latter being a high-dimensional spatiotemporal manifold task that is an unusual proving ground for distillation methods. Quantitative results against a VSD baseline are described as state-of-the-art; specific FID or FVD numbers are not reported in the abstract, and the full tables are in the paper. 1
Code/demo: None linked at time of submission.
Why read it: The theorem-first framing is the differentiator. If you are designing or evaluating flow matching distillation pipelines, the low-pass filter characterization of MFD gives a mechanistic explanation of why VSD is unstable — not just empirical evidence that it is. The 4D occupancy result suggests the method generalizes beyond image synthesis.
2. Lip Forcing: real-time autoregressive diffusion lip sync at 31 FPS
arXiv: 2606.11180 | KAIST AI + AIPARK (led by Paul Hyunbin Cho and Seungryong Kim; 11 authors) | cs.CV
Peer-review status: Preprint. Project page: cvlab-kaist.github.io/LipForcing
Lip synchronization with diffusion models produces high visual quality and strong audio-visual alignment, but full-sequence bidirectional attention and dozens of denoising steps make real-time deployment impractical. Lip Forcing addresses this with a distillation-plus-architecture redesign that claims to be the first autoregressive diffusion approach to the video-to-video (V2V) lip sync task. 2
The starting point is a 14B-parameter audio-conditioned bidirectional video diffusion teacher. The authors distill it into causal (autoregressive) student models at two scales. The 1.3B student runs at 31 FPS with 2 denoising steps per chunk — no classifier-free guidance (CFG) required at inference. That is 17.6× faster than the same-scale bidirectional model. The 14B student runs 39.8× faster than the teacher while maintaining comparable reference fidelity. Time-to-first-frame is sub-millisecond at both scales. 2
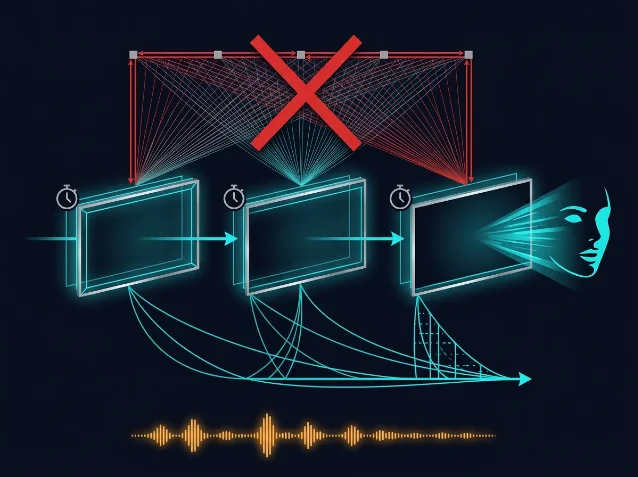
Three components come out of the authors' analysis of the teacher's denoising trajectory:
- Sync-Window DMD: a Distribution Matching Distillation variant scoped to the synchronization-relevant temporal window
- Two-step inference schedule: derived from trajectory analysis to maximally compress denoising steps without audio-visual alignment collapse
- SyncNet-based reward: guides the student toward synchronized outputs during distillation training 2
An analysis of CFG's role during teacher inference yields a non-obvious finding: predictions without CFG favor reference fidelity (the face looks like the input), while CFG-guided predictions favor synchronization in a mid-trajectory band. This fidelity-sync tradeoff is what motivates dropping CFG at student inference — the distillation process captures the synchronization signal, so CFG becomes redundant and only adds latency. 2
Code/demo: Project page linked; code repo not confirmed open-source at submission.
Why read it: The 31 FPS figure is the attention-getter, but the paper's value for researchers is the analysis of how CFG interacts with fidelity vs. sync in bidirectional diffusion — a mechanism that likely applies to audio-conditioned video diffusion more broadly. The distillation architecture (causal student from bidirectional teacher) is a reproducible template for real-time video diffusion beyond lip sync.
3. A Theory on Flow Matching with Neural Networks: first convergence-to-generation guarantees
arXiv: 2606.10089 | Princeton University (Jianqing Fan) + Northwestern University (Han Liu); 5 authors | cs.LG
Peer-review status: Preprint. No public code (theory paper).
Flow matching is now a standard training paradigm for large-scale generative models, but its theoretical foundations — particularly when the velocity field is parameterized by a neural network trained on finite data — have been informal. The question of whether gradient descent on the flow matching loss converges, whether the trained network generalizes, and whether samples from the learned flow are close in distribution to the true data distribution, had not been settled rigorously. 3
This paper, led by Jianqing Fan (Princeton, professor of statistics and financial mathematics) and Han Liu (Northwestern), addresses all three questions end-to-end: 3
- Convergence: Gradient descent on the conditional velocity-field matching objective converges in the over-parameterized 2-layer ReLU network regime
- Generalization: Bounds on the velocity-field matching objective when trained on finite samples
- Sample quality: Wasserstein-distance guarantees for samples generated by the flow induced from the trained network
The three results compose into a closed theoretical loop — from optimization, through generalization, to sample distribution — that did not exist for flow matching with neural networks before this work. 3

The generalization bound relies on a result for multi-task representation learning with unbounded losses, which the authors flag as independently applicable beyond flow-based generative modeling. Experiments on synthetic and real-world image benchmarks validate the theoretical predictions. 3
Code/demo: Not applicable (theory paper; experiments are validation, not a system release).
Why read it: If you work on flow matching theory or want formal grounding for architecture choices, this is the foundational reference. The practical relevance is the Wasserstein guarantee: it establishes that sample quality in flow matching is controlled by standard learning-theoretic quantities, not just empirical FID on held-out sets. Fan and Liu's statistical tradition means the proof techniques will be rigorous by statistical standards, not just "the experiments look good."
4. SSR-Merge: training-free LoRA merging with OLS optimality (ICML 2026)
arXiv: 2606.10617 | 9 authors led by Zhengxuan Wei | cs.CV | ICML 2026
Peer-review status: ICML 2026 accepted. Code: github.com/nagara214/SSR-Merge
Merging multiple LoRA adapters for diffusion models without retraining is useful for composing subject-specific, style-specific, and task-specific fine-tunes at inference time. The standard approach — combining LoRA parameters directly in the weight space — suffers from what the SSR-Merge authors call parameter interference: the rank subspaces of individual LoRAs collide when merged, producing destructive cancellations. 4
Subspace Signal Routing (SSR) takes a different route. Rather than merging parameters, it concatenates all candidate LoRAs along the rank dimension into a single unified subspace. Within that subspace, it applies two operations: an inverse correlation matrix that decorrelates the mixed signals from different LoRAs, followed by a directional guide matrix that steers the purified signals toward their intended outputs. 4
The core theoretical result: SSR aligns with the Ordinary Least Squares (OLS) solution — the minimum-norm linear estimator for the combined signal routing problem. This is a provable mathematical optimality guarantee, not an empirical one. The OLS framing also supports a streaming algorithm: OLS sufficient statistics are additive, so new LoRAs can be incorporated on the fly without recomputing from scratch, reducing both memory overhead and latency for online adapter composition. 4
The paper reports that SSR "significantly outperforms state-of-the-art methods while maintaining comparable efficiency" across extensive experiments; specific metric tables are in the paper. The ICML 2026 acceptance provides an independent quality signal.
Code/demo: Open-sourced at github.com/nagara214/SSR-Merge.
Why read it: Training-free LoRA merging is a practical problem that comes up any time you want to combine fine-tunes without access to the original training data. SSR's OLS optimality proof is a meaningful theoretical contribution — it gives you a criterion for why a merging method should work, not just that it does. The streaming algorithm is directly useful for inference-time adapter composition workflows.
5. Flow-DPPO: replacing ratio clipping with exact KL divergence for RL-aligned flow models
arXiv: 2606.11025 | Tencent Hunyuan (Bowen Ping, Xiangxin Zhou, Penghui Qi, Minnan Luo, Liefeng Bo, Tianyu Pang; 6 authors) | cs.LG
Peer-review status: Preprint. Code and models: github.com/Tencent-Hunyuan/UniRL/tree/main/FlowDPPO
Applying PPO to align flow matching models is structurally awkward. PPO's trust-region mechanism relies on a probability ratio between old and new policies — a quantity that is easy to compute for categorical policies but is a noisy, single-sample estimate for the continuous multivariate Gaussian policies that arise at each denoising step in flow models. The result is over-constraining in some trajectory regions and under-constraining in others, leading to instability under multi-epoch training. 5
Flow-DPPO identifies a structural property that makes exact KL tractable: the per-step policy in flow models is Gaussian, so KL divergence between old and new policies has a closed-form expression at each step. This removes the need for ratio estimation entirely. The trust-region constraint becomes: "update only when the KL divergence between old and new per-step policies is below a threshold," evaluated exactly rather than approximated via importance weights. 5
An asymmetric divergence mask refines this further: gradient updates are blocked only when they simultaneously move the policy away from the trusted region and violate the KL threshold. This asymmetry lets the policy make progress during safe steps while maintaining strict control during potentially divergent ones. 5
The reported gains are qualitative in the abstract: Flow-DPPO achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting in multi-objective settings, promotes balanced optimization across reward objectives, and enables stable multi-epoch training where ratio clipping degrades. Specific reward curves and benchmark tables are in the paper. 5
Code/demo: Open-sourced at github.com/Tencent-Hunyuan/UniRL/tree/main/FlowDPPO, with models.
Why read it: Flow-DPPO is directly relevant to anyone running RL fine-tuning on flow matching models — FLUX, Stable Diffusion 3, Wan, or any other FM-based system. The Gaussian per-step policy observation is the key insight: it is a structural property of flow models that has not been exploited in prior RL alignment work. The code and model release from Tencent Hunyuan makes this immediately reproducible.
Summary table
| Paper | arXiv | Institution | Code | Venue |
|---|---|---|---|---|
| Mean Flow Distillation | 2606.11155 | Zhejiang University | — | Preprint |
| Lip Forcing | 2606.11180 | KAIST AI + AIPARK | Project page | Preprint |
| A Theory on Flow Matching with Neural Networks | 2606.10089 | Princeton + Northwestern | — | Preprint |
| SSR-Merge | 2606.10617 | (Zhengxuan Wei et al.) | GitHub | ICML 2026 |
| Flow-DPPO | 2606.11025 | Tencent Hunyuan | GitHub | Preprint |
Two papers have open code at submission: SSR-Merge (ICML 2026) and Flow-DPPO (Tencent Hunyuan). Lip Forcing has a project page; Mean Flow Distillation and the Flow Matching Theory paper do not link code — the latter is a theory paper and unlikely to carry a training repository.
Cover: AI-generated illustration
参考ソース
- 1Mean Flow Distillation: Robust and Stable Distillation for Flow Matching Models
- 2Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
- 3A Theory on Flow Matching with Neural Networks
- 4SSR-Merge: Subspace Signal Routing for Training-Free LoRA Merging in Diffusion Models
- 5Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
このコンテンツについて、さらに観点や背景を補足しましょう。