Persistent agents, the memory curse, and Anthropic's policy bet
OpenAI acquires Ona to give Codex multi-day enterprise agent runs; Microsoft open-sources ASSERT for behavioral testing (99% of orgs currently skip this step); a May arXiv paper now widely circulating proves expanded memory erodes cooperative intent in 18 of 28 model–game settings; the U.S. government orders Anthropic to shut off Fable 5 and Mythos 5 for foreign nationals; and Dario Amodei publishes a legislative proposal with an offer to self-tax. Time window: June 11–13, 2026.

リサーチノート
Time window: June 11–13, 2026. Four stories reshape how agents run, get tested, and get governed — all in 48 hours.
OpenAI buys Ona, adds a browser debugger to Codex
The biggest infrastructure signal of the week is OpenAI's acquisition of Ona (formerly Gitpod), a German cloud startup that gives AI agents persistent, customer-controlled execution environments.1 The deal is specifically about one bottleneck: agents increasingly need to work for hours or days, but most current setups stop dead when the developer closes their laptop. Ona's platform keeps agents running in the customer's own cloud, with scoped credentials, audit logs, and state that persists across sessions and devices.2
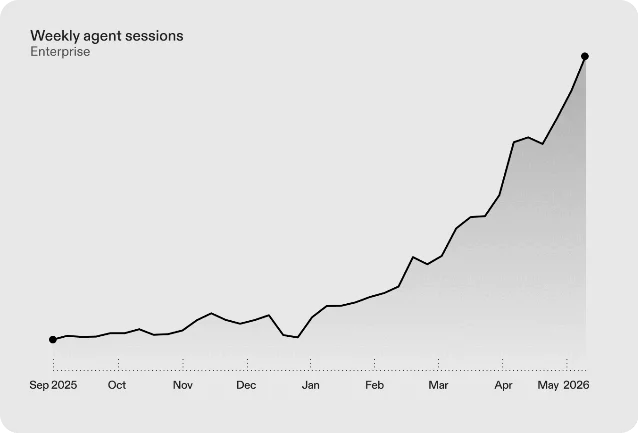
The numbers behind the deal: more than 5 million people now use Codex weekly, up roughly 400% since January 2026. Ona reported 13× growth in weekly agent sessions across enterprise production deployments in the same period.3 Terms weren't disclosed; the Ona team joins the Codex organization after regulatory close.
The same week, OpenAI shipped two Codex updates that shift its character from "IDE plugin" toward "cloud-infrastructure service":4
- Browser Developer Mode — Codex can now use the Chrome DevTools Protocol to read JS performance profiles, console output, network traces, and DOM/CSS state in a live page. An agent debugging a broken React component no longer relies on screenshots; it has a live debugger.
- Savable rate-limit resets — Users can bank one free stored reset and deploy it on their own schedule, decoupling quota refresh from wall-clock cycles. Go, Plus, Pro, and Business tiers all get it.
Both moves point the same direction: an agent that bills hours, not tokens.
Two new frameworks for testing agents you actually deployed
Gartner published a data point alongside Microsoft's launch this week: 99% of organizations currently skip agent evaluation before production deployment, and Gartner projects that by 2029, over three-quarters of domain-specific agents deployed without realistic simulation in regulated industries will fail to deliver business value.5 That number is why both Microsoft and a coalition of academic/industry researchers published evaluation frameworks in the same 48-hour window.
Microsoft ASSERT (Adaptive Spec-driven Scoring for Evaluation and Regression Testing), released June 12, translates plain-language product requirements and organizational policies into executable test suites.5 It doesn't just score outputs — it records intermediate reasoning steps and external tool calls, so a developer can trace exactly where an agent deviated from its intended behavior. The example in Microsoft's announcement: if a research assistant must restrict confidential data to executive users and never email external parties, ASSERT continuously simulates edge cases to check both constraints hold. Sarah Bird, Microsoft's chief Responsible AI product officer, said the framework is designed to run at all three stages: initial development, immediately post-deployment, and continuous monitoring as user interactions evolve.
ASSERT enters a crowded market alongside LangSmith, Braintrust, Patronus AI, and Galileo — but it targets a specific gap: corporate context, not generic benchmarks.
On the research side, AgentBeats (arXiv:2606.13608, submitted June 11) argues the evaluation problem is architectural, not just tooling.6 Current benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and can't fairly compare agent designs that don't share the same interface. The paper proposes a principle it calls Agentified Agent Assessment (AAA): have judge agents do the evaluation, using A2A for task management and MCP for tool access. Instead of maintaining two separate interfaces (one for the benchmark, one for the agent), AAA requires only one. The team ran a five-month open competition with 298 judge agents across 12 categories and 467 subject agents from independent participants to validate the design at scale.
The practical implication for builders: if you're evaluating a new agent against an existing harness and the results feel off, you may be measuring harness compatibility rather than agent capability.
The memory curse, and a hard shutdown in Washington
On memory: A May preprint that has been circulating heavily this week — "The Memory Curse" (arXiv:2605.08060, submitted May 8, 2026) — delivers an uncomfortable result for anyone building agents with long context windows.7 Across 7 LLMs and 4 games played over 500 rounds, expanding accessible history degrades cooperation in 18 of 28 model–game settings. The mechanism isn't paranoia — lexical analysis of 378,000 reasoning traces shows the breakdown comes from eroding forward-looking intent: agents with more memory start optimizing for what happened rather than what should happen next.
Three experiments isolate the cause:
- A LoRA adapter trained only on forward-looking reasoning traces mitigates the decay and transfers zero-shot to different games.
- Replacing visible history with synthetic cooperative records (same prompt length, different content) restores cooperation — proving the trigger is memory content, not window size alone.
- Removing explicit chain-of-thought often reduces the cooperation collapse, suggesting that deliberation amplifies the curse rather than correcting it.
This is a direct challenge to the common assumption that more context = better behavior, and it's worth reading before you wire persistent memory into a multi-agent workflow.
On the shutdown: On June 12, the U.S. government issued an export control directive ordering Anthropic to suspend all access to Fable 5 and Mythos 5 for foreign nationals.8 Anthropic complied, taking both models offline.9 The company framed it as the U.S. government's most significant step to date in restricting access to advanced AI models.
What this means for practitioners: if you're building on Claude Fable 5 or Mythos 5 and your user base includes non-U.S. nationals — or if you're a non-U.S. organization with a direct contract — you need to understand your current service status with Anthropic and prepare contingency routing. DXC Technology, which signed a multi-year global Claude alliance the day before, now has the added complexity of deploying Claude to non-U.S. enterprise customers who are now restricted from the flagship model tier.10
Dario Amodei proposes an AI tax — and an open-weights coding sprint
The policy move: On June 11, Anthropic CEO Dario Amodei published "Policy on the AI Exponential," calling for mandatory third-party frontier model testing and a funding mechanism for job displacement.11 The essay is notable not for the policy asks themselves (transparency + mandatory testing have been in circulation since 2025) but for two specific escalations:
- Amodei explicitly states frontier AI "will eliminate most entry-level white-collar jobs within five years."
- Anthropic is willing to pay into a 0.1–1% "frontier AI tax" to fund displacement relief and retraining.
On the same day, Anthropic launched Claude Corps, a fellowship paying $85,000/year to early-career workers placed at non-profits.12 The pairing is pointed: acknowledge displacement, demonstrate a mechanism, propose regulation, offer your own capital. This sequence forces a response from OpenAI, Google DeepMind, and xAI — none of whom have made comparable financial commitments to the displacement question.
The open-weights sprint: The same week, MiniMax M3 dropped on Hugging Face — a ~428B total / ~23B activated MoE model scoring 59.0% on SWE-Bench Pro and 66.0% on Terminal Bench 2.1, with a 1M-token context window via MiniMax Sparse Attention.4 Moonshot AI also released Kimi-K2.7-Code (open-source), showing +21.8% on Kimi Code Bench v2 and 30% lower inference-token usage versus the prior version. That's five major open-weights coding model releases in five days — M3, Kimi K2.7, North Mini Code, MiMo Code, and MusaCoder — confirming that the competitive frontier for coding agents has shifted from closed APIs to open weights.
Quick signals
- Anthropic × DXC Technology signed a multi-year global alliance (June 11): DXC becomes a global senior Claude partner and will train tens of thousands of certified Forward Deployed Engineers to embed Claude in enterprise and government stacks.10
- GitHub Copilot CLI received an agentic update with smarter subagent delegation to reduce unnecessary handoffs between agents (June 13).13
- Certified Defence Against Runtime Memory Poisoning (arXiv:2606.12703, June 10) proposes formal defenses against adversaries who inject crafted memories into persistent agent stores — worth tracking alongside last issue's SAIGuard work.14
- OpenViking, an open-source context database for AI agents (similar to a unified RAG+memory backend), launched on GitHub with unified management of context, memory, and tools.15
コンテンツカードを読み込んでいます…
参考ソース
- 1OpenAI Buys Ona to Expand Long-Running AI Agents for Enterprises
- 2Ona is joining OpenAI
- 3OpenAI Acquires German Cloud Startup Ona to Power Longer-Running Codex Agent Tasks
- 4AI Daily — June 13, 2026
- 5Microsoft Unveils Open-Source Framework to Automate AI Agent Testing
- 6AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
- 7The Memory Curse: How Expanded Recall Erodes Cooperative Intent in LLM Agents
- 8US Pulls the Plug on Anthropic's Top AI Models
- 9Anthropic Takes AI Models Offline to Comply with New Export Controls
- 10DXC Technology Forms Multi-Year Consulting Alliance with Anthropic
- 11Policy on the AI Exponential — Dario Amodei
- 12Claude Corps Fellowship — Anthropic
- 13BBVA puts AI at the core of banking with OpenAI
- 14Certified Defence Against Runtime Memory Poisoning in Agentic Systems
- 15OpenViking — Open-source context database for AI agents
このコンテンツについて、さらに観点や背景を補足しましょう。