Memory 技术日报 2026-06-22:PixelRAG、codebase-memory-mcp 与 QKV 共享
本期筛出 5 条 memory/context 方向进展:PixelRAG 把网页和 PDF 作为截图记忆单元检索,codebase-memory-mcp 把代码库索引成 agent 可查的知识图谱,Q-K=V 重新打开 KV cache 结构压缩空间,MRAgent 用图式重构改造长期记忆,Elastic 则把企业 agent memory 的召回、隔离与 supersession 做成工程样例。读完可判断今天该跟进视觉 RAG、代码库记忆、KV 架构压缩,还是生产级长期记忆治理。

リサーチノート
过去 24 小时,memory 方向没有出现足够多的全新论文首发;窗口内更强的信号来自 X/Twitter 与 GitHub:社区在重新评估视觉 RAG、代码库记忆、KV cache 结构压缩、图式长期记忆和工程化 agent memory。下面每条都区分「讨论发生在本窗口」与「原始论文 / 仓库发布时间」,避免把旧论文误写成今日首发。
速览清单
- PixelRAG:6 月 22 日上午的中文技术帖把它作为「截图式 Web RAG」重新推到讨论区;帖子指向 StarTrail-org/PixelRAG 1。仓库公开代码、Apache-2.0、2.5k stars;README 写明 hosted Wikipedia index 覆盖 8.28M 页面,并用 Qwen3-VL-Embedding 做截图向量化 2。直接影响是:RAG 管线不再只纠结 HTML parser,网页、PDF、图表型文档可用「渲染后图像」作为记忆单元。
- codebase-memory-mcp:GitTrend 在 6 月 21 日上午的 GitHub 热点帖中把它列为代码记忆项目 3。仓库 README 声称 158 种语言、知识图谱、14 个 MCP tools、Linux kernel 28M LOC/75K files 约 3 分钟索引、五个结构查询 3,400 tokens vs 412,000 tokens 4。它把 coding agent 的「项目记忆」从文件 grep 推向结构图查询。
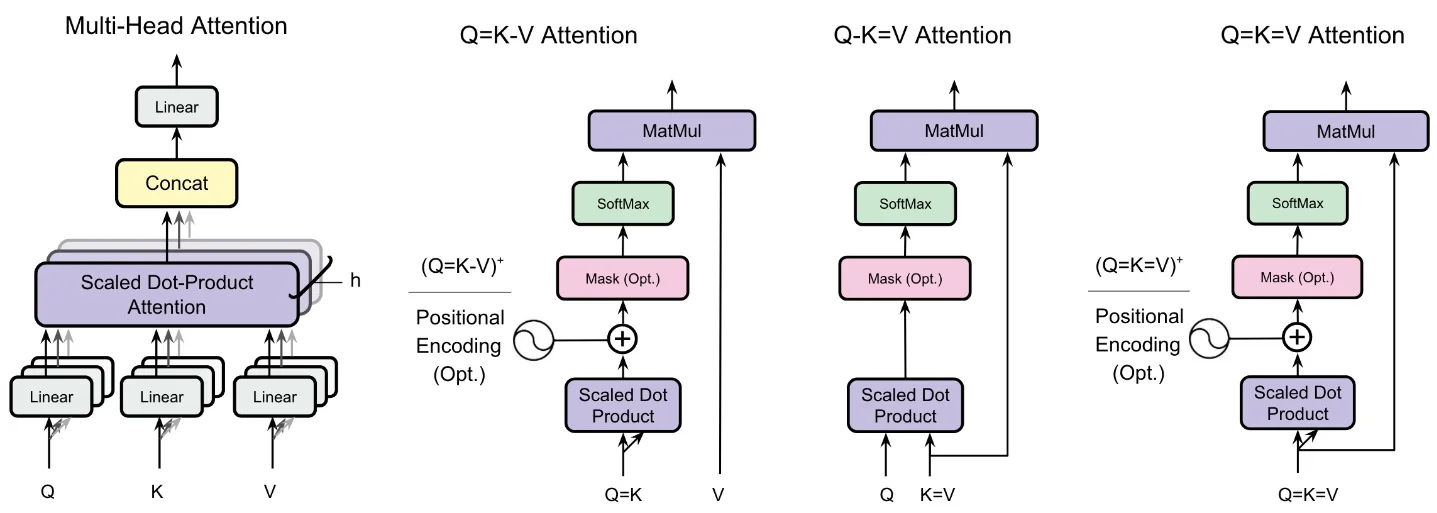
- Q-K=V projection sharing:6 月 22 日上午社区重新讨论「K/V 投影共享」对 KV cache 的影响 5。原始论文已被 ICML 2026 接收;arXiv 摘要写明 Q-K=V 可让 KV cache 降 50%,与 GQA-4 组合降 87.5%,与 MQA 组合降 96.9% 6。这提示 KV cache 压缩不只靠量化和 evict,也可以从 attention 参数共享下手。
- MRAgent:6 月 21 日下午的社区解读把它概括为「记忆是重构,不是检索」 7。论文 6 月 4 日提交并被 ICML 2026 接收;摘要称 Cue-Tag-Content graph + active reconstruction 在 LoCoMo 和 LongMemEval 上相对强基线最高提升 23% 8。它把长期记忆检索做成「推理中不断补线索」的过程。
- Elasticsearch agent memory:6 月 22 日早间日本工程师圈转发 Elastic 的 agent memory 文章 9。Elastic Labs 6 月 16 日文章给出三索引、BM25+dense RRF、reranker、supersession、DLS;博客报告 168 个问题上 R@10=0.89 且零跨租户泄漏 10。企业 agent memory 的重点由此转到权限隔离、同轮写入可见性、事实 supersession 和检索衰减。
逐条解读
1. PixelRAG:把网页记忆单元从 DOM 文本换成截图 tile
PixelRAG 的窗口内信号来自 6 月 22 日 08:50 左右的中文技术帖;帖子把它描述为绕过 HTML 解析、直接对页面截图建索引的 Web RAG 系统,并链接到 StarTrail-org/PixelRAG 仓库 1。这不是今日首发项目。仓库 README 显示它的正式定位是「Web Screenshots Beat Text for Retrieval-Augmented Generation」官方代码库,作者来自 Berkeley SkyLab、BAIR 和 Berkeley NLP 2。
核心变化很直接:PixelRAG 先把网页、PDF 或图片渲染成 screenshot tiles,再用经过截图数据 LoRA 微调的 Qwen3-VL-Embedding 建向量索引;README 还提供了一个 hosted Wikipedia index,覆盖 8.28M 个 Wikipedia 页面,并支持无 API key 查询 2。它给 Claude Code 提供的 pixelbrowse skill 也很有工程味:让 agent 通过
pixelshot 截图页面,再让视觉模型读图,而不是只抓 raw HTML 2。コンテンツカードを読み込んでいます…
工程判断:这条线适合表格、图表、学术 PDF、后台页面和文档站。代价也明显,截图索引通常比纯文本索引更重;如果你的 RAG 资料主要是结构清晰的 Markdown 或 API 文档,文本 parser 仍然更便宜。值得先拿「HTML parser 经常丢布局信息」的页面做小样本 A/B,而不是直接替换整套检索栈。
2. codebase-memory-mcp:代码库记忆开始变成图查询服务
6 月 21 日 10:47 左右,GitTrend 把 DeusData/codebase-memory-mcp 放进 GitHub 热点项目串,理由是它把 codebase 索引成持久知识图谱,并面向 MCP agent 提供查询能力 3。仓库本身给出的信息更具体:它用 tree-sitter AST 覆盖 158 种语言,结合 Hybrid LSP 做语义类型解析,把 functions、classes、call chains、HTTP routes 和 cross-service links 写进持久知识图谱 4。
README 的性能口径很激进:Linux kernel 28M LOC、75K files 的 full index 约 3 分钟;结构查询通常低于 1ms;五个结构查询约 3,400 tokens,而文件级逐个探索约 412,000 tokens,宣称 token 降低 99.2% 4。它还把 14 个 MCP tools 暴露给 Claude Code、Codex CLI、Gemini CLI、Zed、OpenCode、Aider 等 11 类 coding agents 4。
コンテンツカードを読み込んでいます…
工程判断:它解决的是 coding agent 的「项目级长期记忆」问题,而不是聊天记忆。适合大型单仓、多语言仓库、需要频繁问「谁调用了这个函数」「改这个 route 影响哪些模块」的团队。验证时不要只看索引速度,要看三件事:图边是否准、增量同步是否可靠、agent 是否真的少读文件而不漏关键上下文。
3. Q-K=V:KV cache 压缩也可以从投影共享开始
6 月 22 日 09:00 左右,Ala Falaki 重新解读 ICML 2026 论文 Do Transformers Need Three Projections?,重点放在 K/V 投影共享对 KV cache 的影响 5。原论文不是今日首发:arXiv 页面显示 v1 于 6 月 2 日提交,v2 于 6 月 5 日前后修订;论文已被 ICML 2026 接收 6。
论文比较了三类 projection sharing:Q-K=V、Q=K-V、Q=K=V。摘要给出的结论是,Q-K=V 在语言模型实验中可以把 KV cache 降 50%,perplexity degradation 约 3.1%;它还可以叠加 head sharing,和 GQA-4 组合后 cache reduction 到 87.5%,与 MQA 组合后到 96.9% 6。官方代码仓库说明,语言模型实验覆盖 300M 和 1.2B 参数规模,并把 Q-K=V 标为 paper 的 headline result 11。
コンテンツカードを読み込んでいます…
工程判断:这不是部署层能直接开关的 cache trick,而是训练或架构层面的选择。它对端侧推理和小 batch 长上下文很有吸引力,但读者要先看清实验条件:300M/1.2B、10B tokens 训练规模、SlimPajama 等设置和自己的模型规模是否接近。短期可跟进代码复现;中期才可能进入自训模型或蒸馏模型的设计空间。
4. MRAgent:把长期记忆召回做成「边想边找」
6 月 21 日 14:30 左右,社区帖把 MRAgent 概括为「Memory is Reconstructed, Not Retrieved」,核心观点是 agent 不该只做一次 retrieve-then-reason 7。arXiv 原文显示论文 6 月 4 日提交,已被 ICML 2026 接收 8。
MRAgent 把 memory 表示成 Cue-Tag-Content graph。摘要说,它把 LLM reasoning 直接嵌进 memory access,让 agent 根据推理过程中累积的新证据迭代探索和剪枝 retrieval paths,避免无约束图扩展带来的组合爆炸 8。论文报告,在 LoCoMo 和 LongMemEval 上相对强基线最高提升 23%,同时降低 token 与 runtime cost 8。
工程判断:这条路线更像 memory agent 的控制策略,而不只是换一个向量库。它适合多轮、多会话、线索分散的个人助理或研究助理;对一次性问答、事实高度局部的 RAG,复杂图检索可能只是增加延迟。可以把它拆成两个可测假设:图上的中间线索是否真的提高命中率;迭代检索增加的延迟是否被少读 token 抵消。
5. Elasticsearch agent memory:把三类记忆、召回和租户隔离放进同一搜索栈
Elastic Labs 的文章发布于 6 月 16 日,但 6 月 22 日 06:17 左右在日本工程师时间线上被重新转发,转发重点是三索引、BM25+dense RRF、reranker、R@10=0.89 与零租户泄漏 9。原文把这个系统定位为 persistent agent memory layer,并明确说 1M-token context window 是 scratchpad,不是 memory system 10。
这套设计把 episodic、semantic、procedural 三类记忆分别映射到三个 Elasticsearch indices;recall 阶段用 BM25 + Jina v5 dense,经 RRF 融合,再用 cross-encoder reranker 排序 10。文章还讨论了 supersession:用户搬家后,新事实写入,同时旧事实保留审计链但从默认 recall 中隐藏;同轮写入可见性则通过
refresh=True 保证下一次 tool call 能查到刚写入的记忆 10。配套 demo 仓库显示,Atlas 暴露 /api/atlas/mcp/{user_id},把 recall_memory、write_memory、forget_memory 接给 Claude Desktop、Cursor 或其他 MCP client 12。工程判断:这篇文章的价值不在「Elasticsearch 也能存向量」,而在把记忆生命周期问题拆开:事件日志如何沉淀成事实,过期事实如何不污染召回,多租户记忆如何靠 DLS 在服务端隔离。企业团队如果要把 agent memory 放进生产,应优先复核这些边界条件,而不是先讨论换哪种 embedding 模型。
工程判断
今天的共同线索是:memory 正在从「把更多东西塞进 context」转成「决定什么状态可以被结构化、复用、隔离和回滚」。PixelRAG 处理的是网页与文档的视觉状态;codebase-memory-mcp 处理代码结构状态;Q-K=V 处理推理时的 KV 状态;MRAgent 和 Elastic 则处理跨会话事实状态。
如果只能选一个方向跟进,建议按场景切:
- 做浏览器 agent 或复杂文档 RAG,先试 PixelRAG 的截图 tile 管线。
- 做 coding agent,先用 codebase-memory-mcp 跑一个中型仓库,测它是否真的减少文件读取。
- 做端侧或长上下文 serving,先复现 Q-K=V 的小规模实验,再判断是否值得进训练计划。
- 做个人助理或企业助理,先把 supersession、租户隔离、同轮写入可见性这些「脏工程」补上;没有它们,memory 很快会从资产变成负债。
参考ソース
- 1PixelRAG 讨论帖
- 2StarTrail-org/PixelRAG README
- 3GitTrend 热点帖
- 4DeusData/codebase-memory-mcp README
- 5QKV variants 社区解读
- 6Do Transformers Need Three Projections? arXiv
- 7MRAgent 社区解读
- 8Memory is Reconstructed, Not Retrieved arXiv
- 9Elasticsearch agent memory 转发帖
- 10Elastic Labs agent memory article
- 11Brainchip-Inc QKV code release
- 12atlas-memory-demo README
このコンテンツについて、さらに観点や背景を補足しましょう。