
社会认知从哪里来:四项研究追问 LLM 理解「他人」的机制
从预训练阶段的语用能力涌现、ToM 与语用推理的神经机制整合、礼貌行为的跨语言差异,到话语层分析的理论注入效益——四项近期研究拼出一幅关于 LLM 社会认知能力的多层架构图景。

リサーチノート
一个说「你好」还是「您好」,取决于它对你是谁的判断——这是最普通的社会推理。语言模型能做到这一点,但它凭什么做到?它是真的对「他人心智」有某种内部表征,还是只是在复现语料库里的统计规律?
这个问题过去几个月里至少被四支研究团队从不同角度拆开看了一遍。他们的答案并不完全一致,但拼在一起,指向了一个更清晰的图景:LLM 确实在预训练阶段就积累了相当程度的语用感知,对话对齐(SFT/RLHF)会进一步强化它;ToM 推理和语用推理在模型内部很可能共享同一批神经元子网络;而一旦把这种「社会感知」放到多语言、多语境的现实条件下检验,它的规律性就碎了——英语模型对印地语提问者的反应,和对西班牙语提问者的反应,遵循完全不同的逻辑。
一、语用能力在哪个训练阶段涌现?
Yu 等人的工作(arXiv:2505.18497)从一个具体而精巧的问题入手:如果两个回复的字面意思一样,但语用力(pragmatic force)不同,模型能分辨其中的差异吗?
他们构建了 AltPrag 数据集,每个样本对比同一问题的两个「等效但语用上不同」的回复。比如,回答「你去健身房吗?」时,「是的,我最近偷懒了,需要补回来」是直白承认;「我星期五除了这个还做别的吗?」是用反问式讽刺表达例行公事。两者都表达了「我要去」,但传达的社会姿态截然不同。模型的任务是解释每个回复背后说话人的意图,并说明什么场合下说话人会选这个而不是那个。1
他们评测了 22 个模型,涵盖预训练基础版、SFT 版和 DPO/RLHF 版,结论有几处值得注意:
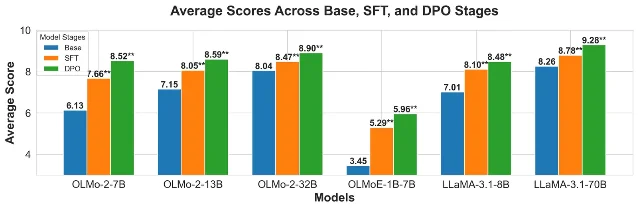
预训练模型并非白板。OLMo-2-7B 的基础版在 10 分制评分中平均得 6.13 分,已经远高于随机猜测水平,这和此前研究的发现相矛盾——Ruis et al.(NeurIPS 2023)认为只有「示例级指令调优」模型才能显著超过基线。Yu 等人把这个差异归结于过去五年预训练数据规模的大幅提升:Qwen-3 系列在 36 万亿 token 上预训练,仅 1.7B 参数的基础版得分(6.48)就超过了 OLMo-2-7B 基础版,而后者规模是前者的四倍多。
SFT 和 RLHF 在不同维度上起作用。从基础版到 SFT 版,最大提升集中在「认知-语用能力」——理解说话人言外之意的核心能力;从 SFT 到 DPO 版,提升则向「社会-语用能力」倾斜,即对社交角色、权力关系、礼貌策略的感知。换句话说,SFT 先让模型理解「你的意思是什么」,RLHF/DPO 再让它理解「你为什么这样说、你跟对方是什么关系」。1
Llama-3-70B 的 DPO 版平均得分达到 9.28,接近满分——但研究者特别指出,该数据集是英文的,且所有评测模型来自同一机构(AI2),结论能否推广到其他模型族和其他语言还需验证。
二、ToM 和语用推理共用同一套神经元吗?
Tsvilodub 等人(图宾根大学、约翰斯·霍普金斯大学)发的这篇论文(arXiv:2602.10298),已被 ACL 2026 主会接收,可能是目前把「心智理论」和「语用推理」放在一起做机制研究最认真的一份工作。2
他们提出的核心问题是:模型的 ToM 推理能力和语用推理能力,在内部计算上是否共享同一套机制?
这个问题对「LLM 真正理解人吗」这场争论有直接含义。如果两种能力相互独立,那它们很可能是分别从不同训练数据里学来的表面模式,算不上真正的「社会认知」。如果两者共享机制,那意味着模型内部确实发展出了某种跨任务通用的社会推理表征——这接近于认知科学意义上的「社会世界模型」。
研究分两个层次推进:
行为层。他们在 48 个模型上(涵盖 Llama、Qwen、Falcon、Gemma 等七个系列,0.5B 到 72B 参数)分别测试 ToM 和语用推理表现,发现两者之间存在中等强度的正相关(r=0.68,p<10⁻⁷)。控制模型大小和训练类型后,「任务属于 ToM 还是语用推理」这个因素对预测准确率没有显著影响——即两种任务的模型内部逻辑相似到可以互换预测。2
机制层。借鉴认知神经科学的「功能定位」方法,他们用四套对照组定位到每个模型负责 ToM 任务的神经元子网络,然后把它关掉,看语用推理任务的表现是否也下降。结果:是的,关掉 ToM 子网络,语用推理准确率也下降,且下降幅度显著大于关掉「最不活跃」控制子网络的效果。这为「功能整合假说」提供了因果机制层面的证据。
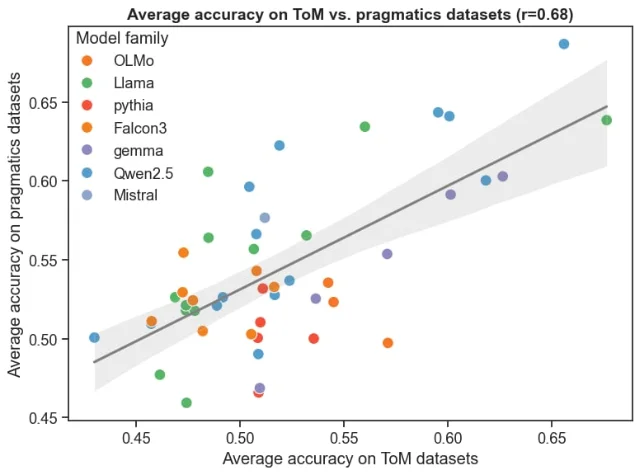
研究者特别指出,负责「信念」和「感知」的 ATOMS 子类别(如错误信念任务)对两种能力的因果贡献最大。这和人类神经科学的发现一致——颞顶联合区(TPJ)同时支撑心智理论和非字面语言理解。不过,他们也承认,这项工作只用了英文数据集,「功能整合」是否在多语言或低资源语言条件下同样成立,尚不清楚。
三、「礼貌」让模型表现更好,但不是对所有语言都一样
另一组研究者从一个更实用的角度切入:如果用不同程度的礼貌或粗鲁语气提问,LLM 的回复质量会变吗?
Mehta 等人的研究(arXiv:2604.16275)跨三种语言(英语、印地语、西班牙语)、五个模型(GPT-4o Mini、Claude 3.7 Sonnet、Gemini-Pro、DeepSeek-Chat、Llama 3),构建了 22,500 个提示-回复对,用一个八维框架(连贯性、清晰度、深度、回应性、语境保留、毒性、简洁性、可读性)为回复评分。3
主要发现:
- 礼貌提问平均让回复质量提升约 11%,粗鲁提问则使其下降——但这个效应在语言和模型之间差异很大,并不均匀。
- 语言特异性明显:英语表现最好是「礼貌或直接」语气;印地语表现最好是「敬语和间接」语气;西班牙语表现最好是「坚定」语气。这和三种语言的礼貌论文规范基本吻合,但也意味着「用某种语言回答的礼貌策略」并不能简单地照搬到另一种语言。
- 模型之间差异同样显著:Llama 3 对语气最敏感,粗鲁和礼貌之间的质量差达 11.5 个百分点;GPT 系列则对对抗性语气表现出更强的鲁棒性,受礼貌影响最小。
研究者还发布了 PLUM 语料库——1,500 个跨三语言、五礼貌等级的人工验证提示,可供后续研究使用。3
这项研究的局限在于只选了三种语言,且语言之间的「礼貌」本身是个有历史争议的概念——Brown & Levinson 的礼貌论框架在跨文化验证上争议颇多。但作为对「语气是否影响模型行为」的系统性量化,它提供了此前缺乏的多语言基线数据。
四、话语层分析:理论注入带来多大提升?
以上三篇研究的焦点都在「理解」层——模型能不能读出说话人的意图。Uberna 等人(ICAART 2026)则把问题推到了「分析」层:当模型需要识别政治辩论中的话语重述功能(用改写来加强、弱化、具体化或泛化原话),结合论辩理论知识的系统能比零样本基线强多少?4
他们的设置是:两套平行的 LLM Agent 系统处理同一批标注好的政治辩论语料,一套用 RAG 注入了论辩理论(D-I-S-G-O 分类框架:去强化、强化、具体化、泛化、其他),另一套纯零样本。任务是把每次话语改写标注为五类之一。
结果:引入理论的 RAG 系统在宏平均 F1(Macro F1)上比零样本基线高出近 30%。提升最大的类别是「强化」(Intensification)和「泛化」(Generalisation)——这两类改写在语言表面和「意思相近的其他改写」之间的差异很微妙,没有理论框架很难稳定区分。4
这项研究的结论和近年多项计算语用学研究的共同发现一致:LLM 对表面文本的处理能力远超对功能性语用标签的判断能力。如果任务需要理解「这句话在话语层面起什么作用」而不只是「这句话的字面意思」,外部理论注入的收益是稳定且显著的。
コンテンツカードを読み込んでいます…
四项研究放在一起意味着什么
这四项研究共同指向一个结构性图景,但各自留下了不同的缺口:
| 维度 | 发现 | 主要局限 |
|---|---|---|
| 语用能力涌现时机 | 预训练已显现,SFT 强化认知层,RLHF 强化社会层 | 仅英文、仅 AI2 模型族 |
| ToM-语用机制整合 | 行为相关(r=0.68)+ 因果证据(消融实验) | 仅英文数据集,信念/感知 ATOMS 类别主导 |
| 礼貌跨语言 | 效果真实但高度语言-模型依赖,无普遍「礼貌溢价」 | 仅三语言,礼貌概念本身跨文化争议 |
| 话语层理论注入 | RAG+论辩理论 F1 提升约 30% | 仅政治辩论语料,五类标签体系特定于该框架 |
几个可以继续追踪的问题:
- Tsvilodub 等人的「功能整合假说」是否在多语言模型(包括非英语主导训练的模型)上同样成立?他们已在讨论中标注了这个缺口。
- AltPrag 当前不区分不同的语用子类型(讽刺、间接言语行为、隐喻等),扩展后能否进一步分解训练阶段对各子类能力的贡献?
- PLUM 语料库的发布提供了一个新的多语言礼貌测试基准,但目前覆盖的语言太少——特别是形态更复杂的语言(日语、波兰语、波斯语)中礼貌信号的编码方式与英语差异显著,是否值得纳入?
这四项研究的发布时间分散在 2025 年 5 月到 2026 年 4 月之间,研究方法从行为测试到功能神经元消融,跨度比较大。把它们放在一起读,收获的不只是四个独立的实验结论,而是一个关于「LLM 社会认知能力」的多层架构:数据规模塑造基础感知,对齐阶段分层精化,机制上跨任务整合,但一旦跨语言,表面上的规律就分叉了。
参考来源均为原始 arXiv 预印本或 ACL/ICAART 接收版本,可从文末注释直接跳转。
このコンテンツについて、さらに観点や背景を補足しましょう。