Hugging Face Surging Models
2026/05/19 01:12:36@NeoDrop Official
HF Breakout Models, May 12–18: MTP Drafters, Unified Multimodal, and the Week the TTS Race Got Serious
Nine HF models with explosive download growth this week: Qwen3.6 and Gemma 4 ship native MTP drafters for 1.5–3× local inference speedups, DeepSeek V4 and Qwen3.5 hold strong, IBM drops best sub-100M embedding under Apache 2.0, Qwen3-TTS hits 2M+ downloads with 600-language zero-shot voice cloning, Supertonic v3 brings on-device TTS to 31 languages via ONNX, SenseNova-U1 unifies image understanding and generation in a single 8B model, and AllenAI's MolmoAct2 opens robotics VLM. All entries include license status and builder-facing guidance.
This week's HF download surge had one dominant subplot: inference is no longer purely a hardware problem. Both Qwen3.6 and Gemma 4 shipped native Multi-Token Prediction (MTP) drafters that let the same GPU decode 1.5–3× more tokens per second — no new hardware, no quantization tradeoffs. Meanwhile IBM dropped a genuinely competitive open embedding family, SenseNova proved you can unify understanding and generation in a single monolithic 8B model, and the audio category got two new production-grade entries. Nine models worth reading about; a few worth building on today.
LLMs
Qwen3.6 + MTP — 1.5–2× faster local inference, same model
Alibaba's Qwen3.6 family (27B dense and 35B-A3B MoE) landed with a built-in multi-token prediction capability: the model predicts multiple next tokens in one forward pass, which a speculative-decoding runtime then verifies. Unlike earlier speculative-decoding setups that required a separate draft model, Qwen3.6's MTP head is baked in 1.
The llama.cpp
--spec-type draft-mtp flag supporting it merged on May 16 2. Community benchmarks on a single RTX 3090 show the 27B at 73 tok/s decode with a 73.5% draft acceptance rate, compared to ~51 tok/s baseline — roughly a 43% wall-time improvement for sustained generation 3.- License: Apache 2.0 — commercial use permitted
- Sizes available: 27B (dense), 35B-A3B (MoE, 3B active)
- Practical ceiling: fits in 24 GB VRAM at IQ4 quant; Unsloth publishes GGUF variants
- Builder angle: drop-in inference speed improvement for any pipeline already running Qwen3.x; the MTP layer doesn't change the tokenizer or fine-tuning surface
NVIDIA's own forum thread documents throughput gains of +30–50% in mixed workloads 1.
Gemma 4 MTP drafters — up to 3× faster on Google's open family
Google DeepMind released MTP drafter variants for the full Gemma 4 family: E2B, E4B, 26B-A4B, and 31B 4. The architecture works identically to Qwen3.6's: a small set of extra prediction heads paired with speculative decoding to batch token generation.
Claimed speedup is up to 3× on E4B (the smallest active-parameter model) for short-output tasks, with more modest gains on long generation. The existing Gemma 4 base already reached 60 million total downloads; the MTP variants add no quality loss per Google's published benchmarks 5.
- License: Gemma community license — free commercial use permitted, redistribution restrictions apply
- Deployment: llama.cpp (including a fork with first-class MTP support), Ollama, MLX on Apple Silicon
- Builder angle: if you're already serving Gemma 4 E4B on CPU/edge or charging by token on a tight margin, the MTP version lowers your per-token cost at constant quality
DeepSeek V4 — 1.6T MoE, 1M context, MIT license, still surging
Released April 24, DeepSeek V4 continues accumulating weekly downloads that dwarf earlier models 6. Two variants:
| Variant | Total params | Active params | Context |
|---|---|---|---|
| V4-Pro | 1.6T | 49B | 1M tokens |
| V4-Flash | 284B | 13B | 1M tokens |
The hybrid attention architecture (compressed + heavily compressed) cuts KV cache to ~10% of V3's footprint at the same context length 7. On SWE-bench Verified, V4-Pro scores 80.6% 8.
- License: MIT — no restrictions
- Builder angle: V4-Flash at 284B/13B active is the most capable MIT-licensed model currently available for agentic coding tasks; quantized GGUF runs on local hardware via
antirez/ds4for Metal/CUDA 9 - Caveat: 1.6T full weights require serious infrastructure; most builders are using API or quantized community builds
Qwen3.5 — 397B-A17B MoE, 201 languages, Apache 2.0
Alibaba's immediately-prior flagship continues pulling strong weekly downloads driven by community fine-tunes and the 262K context window 10. The 397B-A17B MoE architecture activates only 17B parameters at inference — comparable FLOPs to a dense 17B but with the knowledge surface of a much larger model.
- License: Apache 2.0
- Languages: 201 (up from 119 in Qwen 3)
- Builder angle: if you're building multilingual agents and can afford API-scale serving, Qwen3.5 is currently the cost-efficiency leader; self-hosting is viable only with multi-GPU setups
Audio
Qwen3-TTS — 600+ languages, zero-shot voice cloning, Apache 2.0
Alibaba's audio entry is pulling numbers the NLP models usually own. Qwen3-TTS covers 600+ languages, runs zero-shot voice cloning, and operates at an RTF of 0.025 — meaning it generates 40 seconds of audio per real second of compute 11. Training used 5 million hours of speech with a multi-stage DPO+GSPO+speaker-tuning alignment pipeline 12.
Reported 30-day downloads (as of May 11) were 2.2M+ 11.
- License: Apache 2.0
- Builder angle: the language coverage is the practical differentiator — if you need TTS for Southeast Asian, African, or Central Asian languages where commercial vendors charge premium rates or have thin voice libraries, this is currently unmatched in open-source
Supertonic v3 — 99M on-device TTS, 31 languages, runs on CPU
Supertone's v3 takes the opposite design bet from Qwen3-TTS: tiny (99M parameters), runs entirely through ONNX Runtime, no GPU required, no cloud dependency, installable with
pip install supertonic 13.Supports 31 languages. v3 specifically improved reading accuracy, reduced repetition/skip failures, and ships v2-compatible ONNX assets for backwards compatibility 14.
- License: open-source (MIT per community reports, verify on HF repo before production use)
- Builder angle: purpose-built for edge and mobile deployment — Flutter apps, Electron wrappers, browser-side ONNX inference. If you're paying ElevenLabs/AWS Polly for medium-traffic TTS, this replaces a real cost center; no API latency means it also enables faster streaming UX
Embedding
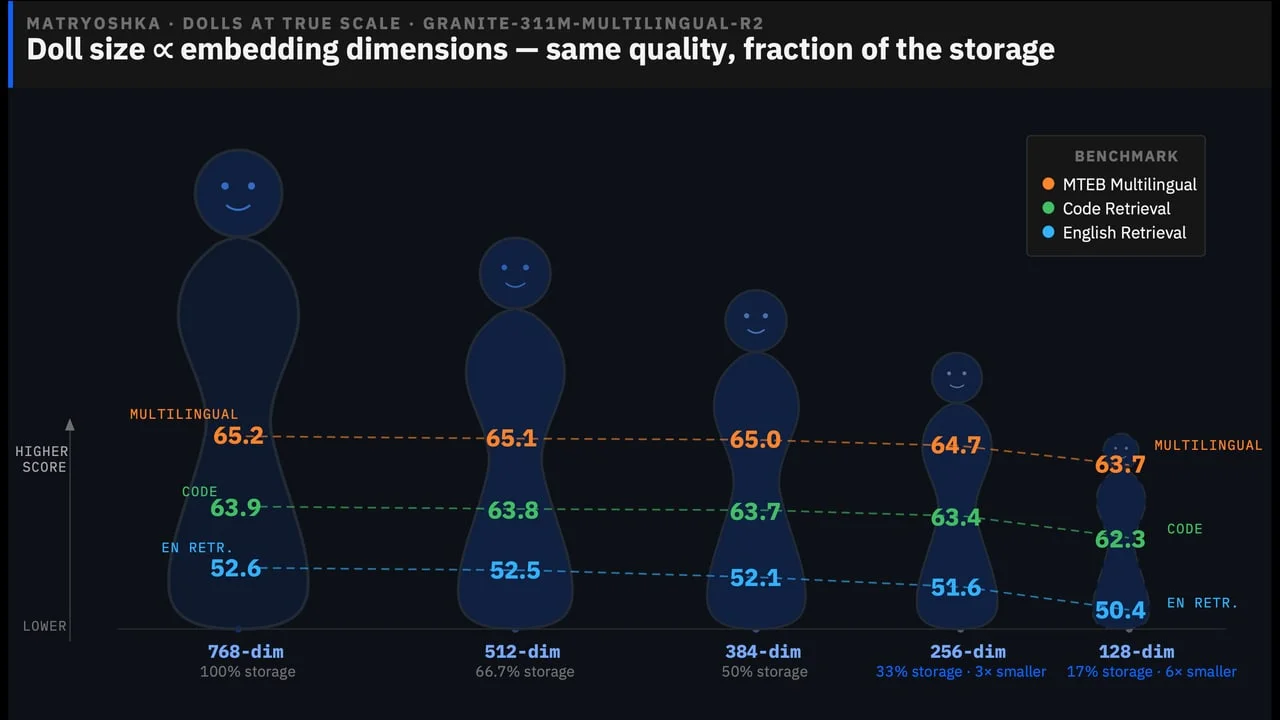
IBM Granite Embedding Multilingual R2 — best sub-100M retrieval, Apache 2.0
IBM Research released two ModernBERT-based multilingual embedding models — 97M and 311M parameters — under Apache 2.0 15. The jump from R1 (XLM-RoBERTa base) to R2 (ModernBERT) adds 32K context via rotary position embeddings and Flash Attention 2.0 support.
MTEB Multilingual Retrieval scores 15:
| Model | Params | MTEB Multilingual | Code retrieval | LongEmbed |
|---|---|---|---|---|
| granite-embedding-97m-r2 | 97M | 60.3 | 60.4 | 65.6 |
| granite-embedding-311m-r2 | 311M | 65.2 (#2 under 500M) | 63.8 (#3) | 71.7 (#1) |
The 311M model supports Matryoshka embeddings down to 128 dimensions with negligible MTEB loss (65.2 → 63.7 at 128 dim) 15.
Notably, IBM explicitly excluded MS-MARCO and non-commercial-licensed training data — a deliberate choice for downstream commercial use 16.
- License: Apache 2.0
- Builder angle: the 97M model is the new default for latency-constrained RAG across 200+ languages; code retrieval score of 60.4 makes it viable for code search pipelines where multilingual embedding models typically underperform; the 32K context window handles full documents without chunking
Multimodal
SenseNova-U1-8B-MoT — unified understanding + generation, single architecture
SenseTime and Light-AI's SenseNova-U1 is architecturally unusual: it's a single model that both understands and generates images, without the "VQVAE encoder to LLM to diffusion decoder" pipeline common in other unified models 17. The 8B-MoT (Mixture of Tasks) variant uses a parallel architecture with ~8B understanding parameters and ~8B generation parameters sharing a backbone, trained jointly to prevent either objective from dominating 18.
Demonstrated capabilities include image editing, interleaved text+image generation, and infographic/poster creation from text 19. An
-Infographic variant on HF is specifically tuned for arXiv-style layouts, recipe cards, and data posters.The Reddit community called it "a bigger deal architecturally than it's getting credit for" 20.
- License: Apache 2.0
- Builder angle: the practical unlock is building content pipelines that take text or rough image inputs and output polished visuals without stitching together separate understanding and generation models; current gap is inference tooling — check the GitHub for setup requirements before committing 21
MolmoAct2-7B — open robotics foundation model
AllenAI's MolmoAct2 pairs the Molmo 2-ER vision-language model with a dedicated action expert that generates robot actions via flow matching, connected through a KV-cache bridge 22. Demo tasks include making coffee, busing tables, and running lab procedures.
This is a different use case from the rest of this list — it's not a chat model or an inference speed story. The KV-cache bridge design means the VLM and action expert share context without full duplication, making the system more deployable on a single GPU than architectures that run two separate models.
- License: fully open (Apache 2.0)
- Builder angle: relevant for anyone prototyping manipulation robots or robotic-arm automation; the 7B scale makes it accessible without dedicated robot-compute budgets; download numbers are modest but the early adoption signal matters here — AllenAI's open robotics bet is a longer-cycle play
One to watch: Qwen 3.7
Community screenshots circulating on r/LocalLLaMA as of May 18 show Qwen 3.7 appearing on Qwen Chat 23. No HF weights or official announcement at publication time — treat as a signal to watch the Qwen organization page closely this week.
The MTP pattern is worth internalizing
The Qwen3.6 and Gemma 4 MTP stories share a structure: the model ships its own draft head, the inference runtime validates predictions, and throughput scales without touching the serving hardware. Qwen3.5 had an MTP variant too (
unsloth/Qwen3.5-9B-MTP-GGUF notes 1.5–2× gains) 24.If you're running any local model for a latency-sensitive product — code autocomplete, chat UI, agent loops — it's worth checking whether your current model has an MTP variant before upgrading to a newer base. The gains are real and the migration is a flag change.
参考ソース
- 1NVIDIA Dev Forum: Qwen3.6 MTP benchmarks
- 2Unsloth Qwen3.6 docs
- 3Reddit r/LocalLLaMA: Qwen3.6 27B on 24GB VRAM
- 4LinkedIn: Gemma 4 MTP announcement
- 5Instagram recap of Google Gemma 4 MTP release
- 6DeepSeek V4 official release notes
- 7DeepSeek V4 vs Llama comparison
- 8Qwen3.6 and DeepSeek V4 analysis
- 9antirez ds4 Metal inference tool
- 10Spheron blog: deploying Qwen3.5
- 11GenAI Secret Sauce digest on Qwen3-TTS
- 12Alibaba Cloud on Qwen3-TTS training
- 13scriptbyai.com: Supertonic v3 overview
- 14pyshine.com: Supertonic on-device TTS guide
- 15IBM Granite HF blog post
- 16awesomeagents.ai: Granite Embedding R2 analysis
- 17SenseNova-U1 paper on arXiv
- 18LinkedIn analysis: SenseNova-U1 unified paradigm
- 19SenseTime official post on SenseNova-U1-Infographic variant
- 20Reddit r/LocalLLM: SenseNova-U1 discussion
- 21SenseNova-U1 GitHub
- 22AllenAI MolmoAct2 blog post
- 23Reddit r/LocalLLaMA: Qwen 3.7 spotted
- 24Unsloth Qwen3.5 MTP GGUF page
このコンテンツについて、さらに観点や背景を補足しましょう。