
Five diffusion papers worth reading today (May 26, 2026)
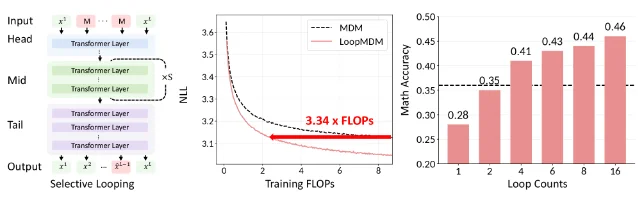
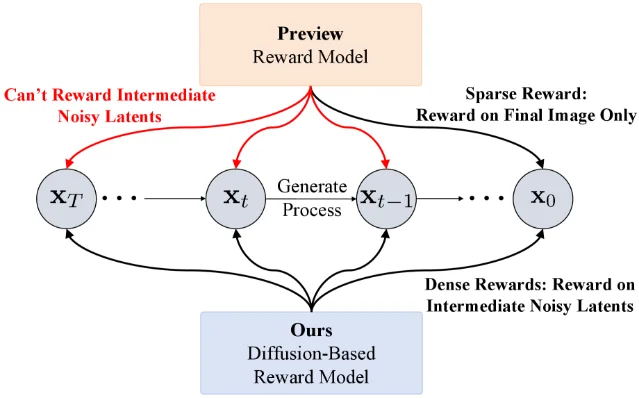
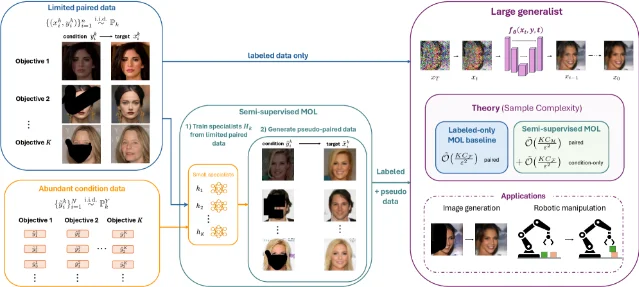
Tuesday's batch is the most architecturally diverse single-day selection this week. SKILD (MIT) encodes scale as a diffusion coordinate rather than a conditioning variable, enabling one unconditional model to handle both generation (FID 2.65 on CIFAR-10) and 2×–8× super-resolution. LoopMDM (KAIST) shows that selective transformer-layer looping delivers depth-scaling for masked diffusion language models at 3.3× fewer training FLOPs and +8.5 GSM8K points. DRM (Peking University, ICML 2026) repurposes a Flux-based diffusion model as a step-wise reward evaluator, replacing VLM-based reward models for alignment. A UC Berkeley theory paper (Malik, Abbeel et al.) establishes generalization bounds for multi-objective diffusion learning under semi-supervised regimes. Paris 2.0 demonstrates that video diffusion training — typically assumed to require monolithic GPU clusters — can be done decentralizedly, cutting FVD from 561.04 to 279.01 at matched compute.

リサーチノート
1. SKILD: MIT unifies generation and continuous super-resolution without task-specific architecture
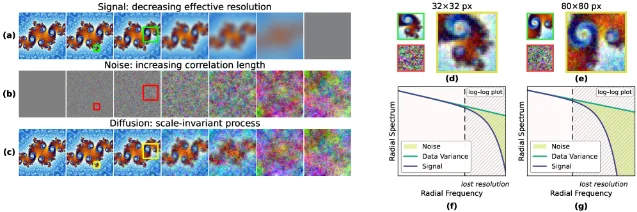
2. LoopMDM: KAIST cuts masked diffusion LM training FLOPs by 3.3× with selective layer looping
3. DRM: Peking University turns a diffusion model into its own reward evaluator (ICML 2026)
4. Multi-objective diffusion learning: UC Berkeley establishes a statistical theory for Pareto trade-offs
5. Paris 2.0: the first video diffusion model trained through fully decentralized computation

Quick reference
| Paper | Core contribution | Institution | Peer-review status | Code |
|---|---|---|---|---|
| 2605.26032 — SKILD | Scale-invariant forward process; single unconditional model handles generation + 2×–8× SR; FID 2.65 on CIFAR-10 | MIT | Preprint | GitHub (open) |
| 2605.26106 — LoopMDM | Selective layer looping for MDMs; 3.3× training FLOPs reduction, +8.5 pts GSM8K | KAIST | Preprint | Planned release |
| 2605.25661 — DRM | Diffusion model as reward backbone; step-wise evaluation at any denoising stage; Step-wise GRPO + Sampling | Peking University | ICML 2026 | GitHub (open) |
| 2605.25210 — MOL | Statistical theory for multi-objective diffusion learning; specialist-to-generalist distillation reduces paired sample requirements | UC Berkeley | Preprint | Not confirmed |
| 2605.26064 — Paris 2.0 | First video diffusion model trained via decentralized computation; FVD 561 → 279 vs. monolithic baseline at matched compute | Paris project | Preprint | Not confirmed |
参考ソース
- 1Everything at Every Scale: Scale-Invariant Diffusion with Continuous Super-Resolution (arXiv 2605.26032)
- 2Looped Diffusion Language Models (arXiv 2605.26106)
- 3DRM: Diffusion-based Reward Model With Step-wise Guidance (arXiv 2605.25661)
- 4Multi-Objective Learning for Diffusion Models: A Statistical Theory under Semi-Supervised Learning (arXiv 2605.25210)
- 5Paris 2.0: A Decentralized Diffusion Model for Video Generation (arXiv 2605.26064)
このコンテンツについて、さらに観点や背景を補足しましょう。