OpenAI Agents SDK #12:你的 Agent 跑到第 8 轮突然停了——你却看不到任何错误信息
从「Agent 跑到第 8 轮突然停了却看不到任何错误信息」这个生产陷阱切入,系统拆解 OpenAI Agents SDK v0.15.x 的完整异常体系(MaxTurnsExceeded / ModelBehaviorError / GuardrailTripwireTriggered / ModelRefusalError);对比可重试与不可重试异常的处理策略;讲解 error_handlers 声明式受控降级;给出带指数退避 + Jitter 抖动的重试封装与 SDK 原生 ModelRetrySettings 两种方案;附完整 ProductionRunner 生产封装代码。结尾提炼 7 条生产 Checklist,串联前 11 篇 Tracing、Guardrails、Context、Handoffs 经验,以系列完结致谢收尾。
リサーチノート

这是整个系列最后一篇。
从 Agent 基础结构讲到 Runner、Tools、Handoffs、Memory、Sandbox、Tracing、Guardrails、Streaming、Context、Models,走了 11 篇。今天压轴:错误处理与重试——如何让你的 Agent 在生产环境里真正活下去。
SDK 的异常体系:先把地图看清楚
具体子类分四类1:
| 异常类 | 触发条件 | 可重试? |
|---|---|---|
MaxTurnsExceeded | Agent 运行圈数超过 max_turns 限制 | 视情况(见下) |
ModelBehaviorError | 模型调用了不存在的工具、返回了格式错误的 JSON | 通常可以小概率重试 |
InputGuardrailTripwireTriggered | 输入护栏检测到违规内容 | 不可重试(用户输入问题) |
OutputGuardrailTripwireTriggered | 输出护栏检测到违规内容 | 不可重试(模型输出问题) |
UserError | 开发者使用 SDK 方式有误(如参数类型错误) | 不可重试(代码逻辑问题) |
还有一个 v0.15.0 新增的:
ModelRefusalError2。在 v0.15.0 之前,模型拒绝请求时会被悄悄处理为「空文本输出」,然后 Runner 继续循环,直到跑满
max_turns 才触发 MaxTurnsExceeded。这导致一个很隐蔽的问题:你以为是轮数不够,实际上是模型压根不想回答。v0.15.0 把这个行为改了——模型拒绝现在直接抛出
ModelRefusalError2。拒绝就是拒绝,不再绕一大圈。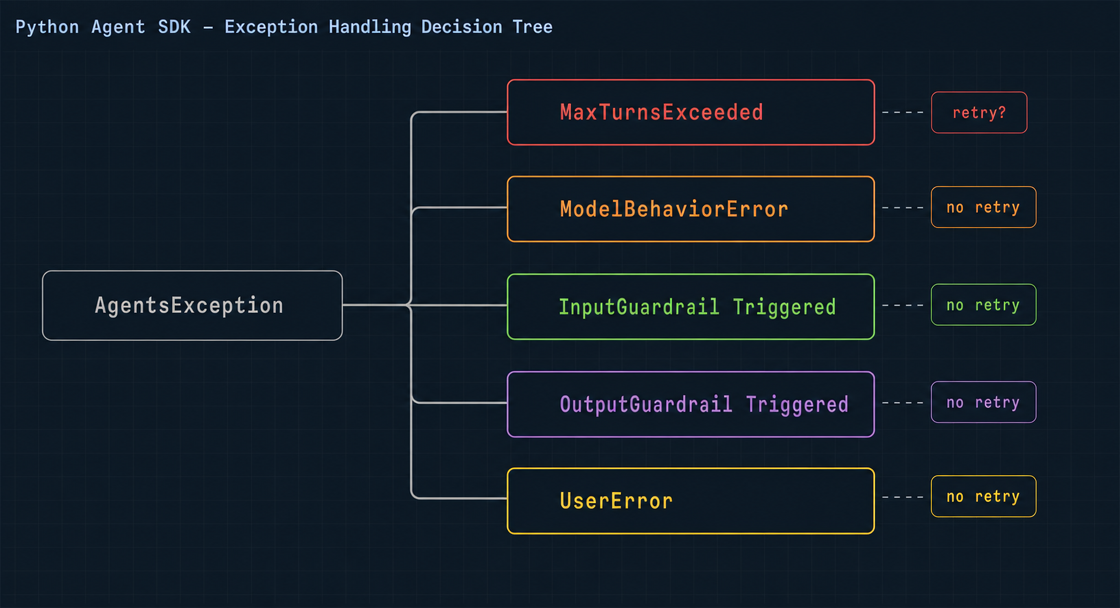
max_turns:你最常忽略的一个参数
Runner 的运行逻辑是个循环3:
- 调用当前 Agent,获取 LLM 输出
2a. 若返回
final_output→ 结束 2b. 若触发 handoff → 切换 Agent,重新循环 2c. 若触发工具调用 → 执行工具,把结果追加回对话,重新循环 - 超过
max_turns→ 抛出MaxTurnsExceeded
每次「重新循环」就是一个 turn。一个 Agent 调用 5 个工具,就消耗了至少 5 个 turn(工具调用那轮 + 工具结果处理那轮,每次工具调用算两个 turn)。如果你有 3 个工具串行调用,再经历一次 handoff,turn 数比你想象的快得多。
SDK 默认的
max_turns 是 10。对很多稍微复杂的 Agent 来说,这个值偏小。配置方式有两个层级4:
from agents import Agent, Runner, RunConfig
# 方式一:RunConfig 层(推荐,运行时可动态调整)
result = await Runner.run(
agent,
input="帮我分析这 5 份报告并生成摘要",
run_config=RunConfig(max_turns=30), # 覆盖默认值
)
# 方式二:Runner.run() 直接参数(效果等同)
result = await Runner.run(
agent,
input="...",
max_turns=30,
)一个经验:max_turns 设置为「预期工具调用数 × 2 + 5」。
× 2 是因为每次工具调用在 Runner 循环里占两轮(发起调用 + 处理结果),+ 5 是给模型推理和 handoff 留的余量。异常捕获:区分「可重试」和「不可重试」
这是生产代码和 demo 代码最大的区别。
import asyncio
from agents import (
Agent, Runner, RunConfig,
MaxTurnsExceeded,
ModelBehaviorError,
InputGuardrailTripwireTriggered,
OutputGuardrailTripwireTriggered,
UserError,
)
async def run_with_error_handling(agent: Agent, user_input: str):
try:
result = await Runner.run(
agent,
input=user_input,
run_config=RunConfig(max_turns=20),
)
return result.final_output
except InputGuardrailTripwireTriggered as e:
# 用户输入触发了护栏——不要重试
# e.guardrail_result 包含具体是哪条规则触发的
guardrail_name = e.guardrail_result.guardrail.name
print(f"输入被护栏拦截: {guardrail_name}")
return "您的请求包含不被允许的内容,请修改后重试。"
except OutputGuardrailTripwireTriggered as e:
# 模型输出触发了护栏——记录日志,不要重试
# 重试大概率还是触发,除非换 prompt
print(f"模型输出被拦截: {e.guardrail_result.guardrail.name}")
return "很抱歉,我无法提供这方面的回答。"
except MaxTurnsExceeded:
# 超出轮数——可能是任务太复杂,可能是 Agent 卡住了
# 视业务场景决定是否重试(加大 max_turns)或分解任务
print("Agent 运行超出轮数限制,任务可能过于复杂")
return None
except ModelBehaviorError as e:
# 模型行为异常(调用了不存在的工具、JSON 格式错误)
# 小概率可以重试一次,多次不行就放弃
print(f"模型行为异常: {e}")
raise # 由上层的重试机制处理
except UserError as e:
# 代码写错了——不要重试,修代码
print(f"SDK 使用错误(请检查代码): {e}")
raise注意
InputGuardrailTripwireTriggered 和 OutputGuardrailTripwireTriggered 都带 guardrail_result 字段5,里面是完整的 InputGuardrailResult 或 OutputGuardrailResult 对象,包含触发的护栏名称、输出信息等,日志里一定要记录下来。error_handlers:声明式的「受控降级」
不抛异常,而是返回一个「受控的最终输出」。
from agents import Agent, Runner, RunConfig
def handle_max_turns(run_context, exception):
"""
当 MaxTurnsExceeded 时,不抛异常,
而是返回一个友好的降级消息作为最终输出
"""
return "任务需要更多步骤,已超出单次运行限制。建议将任务拆分后分步执行。"
def handle_model_refusal(run_context, exception):
"""
当 ModelRefusalError 时(v0.15.0+),
返回符合输出 schema 的空值或提示
"""
return "该请求无法处理,请尝试调整问题描述。"
result = await Runner.run(
agent,
input=user_input,
run_config=RunConfig(
max_turns=20,
error_handlers={
"max_turns": handle_max_turns,
"model_refusal": handle_model_refusal,
}
),
)
# result.final_output 不再是 None,而是 handler 返回的字符串适合用
error_handlers 的场景:客服机器人、工作流自动化这类「宁可降级也不中断」的业务。不适合的场景:需要精确错误诊断、或上游依赖异常信号的系统——此时老老实实用 try/except 更清晰。重试策略:指数退避不是银弹
ModelBehaviorError 可以重试,但重试不能是硬循环。import asyncio
import random
from agents import Agent, Runner, RunConfig, ModelBehaviorError
async def run_with_retry(
agent: Agent,
user_input: str,
max_retries: int = 3,
base_delay: float = 1.0,
max_delay: float = 10.0,
):
"""
带指数退避的重试封装。
仅对 ModelBehaviorError 重试,其他异常直接透传。
"""
last_exception = None
for attempt in range(max_retries + 1): # +1 是因为第 0 次是首次尝试
try:
result = await Runner.run(
agent,
input=user_input,
run_config=RunConfig(max_turns=20),
)
return result.final_output
except ModelBehaviorError as e:
last_exception = e
if attempt == max_retries:
break # 已到最大重试次数,走到最后的 raise
# 指数退避 + Jitter(随机抖动,避免多个请求同时重试导致雪崩)
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1) # 10% 的随机扰动
actual_delay = delay + jitter
print(f"第 {attempt + 1} 次尝试失败,{actual_delay:.2f}s 后重试... ({e})")
await asyncio.sleep(actual_delay)
# InputGuardrailTripwireTriggered、OutputGuardrailTripwireTriggered、
# UserError 等不可重试的异常直接透传,不会被这里捕获
raise last_exception关于 Jitter(随机抖动)6:如果你有多个并发 Agent 在同一时刻失败并重试,没有 Jitter 的纯指数退避会让它们在同一时刻「同步重试」,对下游服务造成脉冲式压力。加 10%-20% 的随机扰动,可以把这一波重试打散。
SDK 的
ModelSettings.retry 字段7提供了托管的重试配置(ModelRetrySettings),封装了 max_retries、backoff(含 initial_delay、max_delay、multiplier、jitter)和 policy。如果你不想手写 asyncio.sleep 循环,可以直接用这个:from agents import Agent, ModelSettings, ModelRetrySettings, ModelRetryBackoffSettings
from agents.models import retry_policies
agent = Agent(
name="robust-agent",
instructions="...",
model_settings=ModelSettings(
retry=ModelRetrySettings(
max_retries=3,
backoff=ModelRetryBackoffSettings(
initial_delay=1.0,
max_delay=10.0,
multiplier=2.0,
jitter=True,
),
# 只对网络错误和特定 HTTP 状态码重试
policy=retry_policies.any(
retry_policies.network_error(),
retry_policies.http_status([429, 503]),
),
)
),
)有几类情况 SDK 不会自动重试,即使你配置了 retry8:中止错误、提供商标记为重放不安全的请求、流式运行已经开始输出、以及有状态的后续请求。这些场景下重试可能会导致副作用,SDK 选择了保守策略。
从 RunResult 里挖诊断信息
result = await Runner.run(agent, input=user_input)
if result.final_output is None:
# 翻 new_items 看中间步骤
for item in result.new_items:
print(f"[{item.type}] {item}")
# 检查是否有 handoff 发生(最后运行的可能不是原始 agent)
print(f"最终运行的 Agent: {result.last_agent.name}")
# 检查护栏结果
for gr in result.input_guardrail_results:
if gr.output.tripwire_triggered:
print(f"输入护栏触发: {gr.guardrail.name}")
for gr in result.output_guardrail_results:
if gr.output.tripwire_triggered:
print(f"输出护栏触发: {gr.guardrail.name}")new_items 是本次运行新产生的所有条目——工具调用、工具输出、模型消息、handoff 记录——按时间顺序排列。final_output 为 None 时,看 new_items 的最后几条,通常能找到卡在哪里。还有一个细节:Streaming 模式下,中途可以检查
RunResultStreaming.interruptions 来发现「等待审批的工具调用」9。这是另一类「无输出」的合理场景——Agent 没停,在等你审批。生产 Checklist:11 篇系列经验的压缩版
这一章比较长。如果你是跳过前 11 篇直接看这里的,建议收藏后再慢慢对照。
1. 永远设置显式 max_turns,不要依赖默认值
默认 10 轮,对一个「调用 3 个工具 + 一次 handoff」的 Agent 来说基本会触发
MaxTurnsExceeded。每个 Agent 在上线前,在暂存环境里跑几次,用实际日志数据来决定 max_turns 的合理值。2. 用 Tracing 做你的侦探工具
第 7 篇讲 Tracing 的意义在这里最清楚。一旦
final_output 为 None 或你在排查 MaxTurnsExceeded,Tracing 会告诉你每一轮循环里 Agent 调用了什么工具、得到了什么结果、在哪里卡住了10。没有 Tracing 的生产 Agent 等于盲飞。启用方式很简单(SDK 默认已开启),如果要导出到第三方(比如 Langfuse 或 Datadog),参考第 7 篇的自定义 Processor 写法。
3. Guardrails 触发 ≠ Agent 出错,要区分对待
第 8 篇的核心教训:
InputGuardrailTripwireTriggered 和 OutputGuardrailTripwireTriggered 是「业务流程正常终止」,不是「系统错误」11。日志里把它们分开记录,监控告警里不要把这两类异常和真正的系统错误混在一起。run_in_parallel=True(InputGuardrail 的默认值)意味着护栏和 LLM 并行执行——如果护栏触发,你已经消耗了那次 LLM 的 token。如果你的业务对 token 成本敏感,可以设置 run_in_parallel=False 让护栏先跑,但这会增加总体延迟5。4. Context 不是全局变量——类型要统一
第 10 篇的陷阱:一次 Runner.run() 里,所有 Agent 和工具必须使用同一类型的上下文对象12。如果你在某个工具里意外创建了类型不匹配的 context,会在运行时得到一个让人费解的
UserError。5. Handoff 链条不要无限延伸,用 max_turns 守护
第 4 篇(Handoffs)里的 Agent 切换,每次 handoff 算一个循环轮次。如果业务场景里可能出现「A → B → C → A → B → …」的循环切换(比如没有终止条件的工作流),
MaxTurnsExceeded 就是你的最后防线。不要把它当作错误,要把它当作「有限状态机保险丝」。6. 分布式场景下,幂等性是前提
在分布式环境里重试 Agent 调用,最常见的灾难是「工具副作用执行了两遍」6。发邮件发了两封、数据库写入了两次、API 调用了两次扣费。
重试之前,先问自己:这个工具是幂等的吗? 如果不是(发送通知、支付、写操作),要么在工具层加幂等保护(传入
idempotency_key),要么把这类工具排除在自动重试范围之外,改为人工介入或 Human-in-the-loop 流程。7. Streaming 模式下的错误处理要单独处理
第 9 篇里提到,
Runner.run_streamed() 返回的是 RunResultStreaming,异常捕获方式和 run() 略有不同——错误可能在 stream_events() 的异步迭代过程中抛出,而不是在最初的 run_streamed() 调用时。正确写法:result = Runner.run_streamed(agent, input=user_input)
try:
async for event in result.stream_events():
# 处理每个事件
pass
except MaxTurnsExceeded:
# 在这里捕获,不是在 run_streamed() 那行
print("流式运行超出轮数限制")完整实战示例:一个能在生产活下去的 Agent 封装
把上面所有模式组合在一起:
import asyncio
import random
import logging
from typing import Any
from agents import (
Agent, Runner, RunConfig, RunContextWrapper,
MaxTurnsExceeded, ModelBehaviorError,
InputGuardrailTripwireTriggered,
OutputGuardrailTripwireTriggered,
UserError,
)
logger = logging.getLogger(__name__)
class ProductionRunner:
"""
生产级 Agent 运行封装。
覆盖:错误分类、指数退避重试、受控降级、诊断日志。
"""
def __init__(
self,
agent: Agent,
max_turns: int = 20,
max_retries: int = 3,
base_delay: float = 1.0,
max_delay: float = 10.0,
):
self.agent = agent
self.max_turns = max_turns
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
async def run(self, user_input: str, context: Any = None) -> str | None:
"""
运行 Agent,内置重试和错误处理。
返回 final_output 字符串,或 None(MaxTurnsExceeded 后的降级)。
抛出不可重试的异常供上层处理。
"""
last_error = None
for attempt in range(self.max_retries + 1):
try:
result = await Runner.run(
self.agent,
input=user_input,
context=context,
run_config=RunConfig(max_turns=self.max_turns),
)
# 检查是否有护栏在无声中触发(通常已经通过异常体现,此处是防御性检查)
for gr in result.input_guardrail_results:
if gr.output.tripwire_triggered:
logger.warning(
"输入护栏触发(未抛异常): %s",
gr.guardrail.name
)
return result.final_output
except (InputGuardrailTripwireTriggered, OutputGuardrailTripwireTriggered) as e:
# 护栏触发:业务终止,不重试
logger.info("护栏拦截: %s | 护栏: %s", type(e).__name__, e.guardrail_result.guardrail.name)
return None # 或者返回预设的拒绝文案
except MaxTurnsExceeded:
# 轮数超限:任务复杂度问题,不重试(重试也会超)
logger.warning(
"MaxTurnsExceeded | agent=%s | max_turns=%d | input_preview=%s",
self.agent.name,
self.max_turns,
user_input[:50],
)
return None # 上层决定是否拆分任务重试
except UserError as e:
# 代码逻辑错误:不重试,直接暴露
logger.error("SDK 使用错误(需检查代码): %s", e)
raise
except ModelBehaviorError as e:
# 模型行为异常:可以小概率重试
last_error = e
if attempt == self.max_retries:
logger.error(
"ModelBehaviorError 重试 %d 次后放弃: %s",
self.max_retries, e
)
raise
delay = min(self.base_delay * (2 ** attempt), self.max_delay)
jitter = random.uniform(0, delay * 0.1)
wait = delay + jitter
logger.warning(
"ModelBehaviorError (attempt %d/%d),%.2fs 后重试",
attempt + 1, self.max_retries, wait
)
await asyncio.sleep(wait)
# 理论上不会到这里,但保险起见
if last_error:
raise last_error
return None系列完结:从「学会用」到「用得稳」
十二篇文章,一个完整的旅程。
从 #1 Agent 基础结构开始,你知道了
Agent 不过是一个带 instructions 和 tools 的数据类。到 #2 Runner 运行机制,理解了 Agent Loop 的本质。#3 Tools教你把任何 Python 函数变成 Agent 的能力。#4 Handoffs 解决了复杂任务的分工问题。#5 Memory/Sessions 让 Agent 跨轮对话有了记忆。#6 Sandbox 把 Agent 放进了真实的文件系统。#7 Tracing 给了你观测 Agent 行为的眼睛。#8 Guardrails 装上了安全护栏。#9 Streaming 解决了「盯着白屏等结果」的体验问题。#10 Context 厘清了「哪些数据给 LLM 看、哪些给本地代码用」。#11 Models 拆解了三层优先级覆盖链和多模型调度。最后这篇,讲的是所有这些模块组合在一起、部署到生产之后,如何让它在真实世界里不倒下。
Agent 开发其实和传统后端开发没那么不同。超时要处理,异常要分类,重试要有退避,日志要够用,降级要有预案。不同之处在于:LLM 是个有随机性的组件,工具调用结果难以预测,任务边界比 API 调用模糊得多。
这让错误处理比以前更重要,也更复杂。
希望这个系列对你有用。如果你在生产里踩到了文章里没覆盖的坑,欢迎留言——说不定是下一个系列的开头。
——系列完结,感谢一路跟读。
参考来源
- 1OpenAI Agents Python SDK - Exceptions Reference
- 2openai-agents-python GitHub Releases
- 3OpenAI Agents Python SDK - Running Agents
- 4OpenAI Agents Python SDK - Run API Reference
- 5OpenAI Agents Python SDK - Guardrail API Reference
- 6微信公众号 - Java技术工坊
- 7OpenAI Agents Python SDK - Model Settings Reference
- 8OpenAI Agents Python SDK - Models
- 9OpenAI Agents Python SDK - Streaming
- 10OpenAI Agents Python SDK - Tracing
- 11OpenAI Agents Python SDK - Guardrails
- 12OpenAI Agents Python SDK - Context
このコンテンツについて、さらに観点や背景を補足しましょう。