github.com
sjsyrek/design-council
Claude Code plugin: convene 11 role-specialized peer agents to debate a technical decision in real time, with the invoking Claude acting as CEO.

`design-council` by Steven Syrek (sjsyrek) is a Claude Code-only skill that spawns 11 independent specialist agents — each with its own context — to debate a cross-cutting architecture or design decision in parallel. The article covers the 6-phase debate protocol, the full seat roster with dynamic sizing rules, exact installation commands, a concrete opening-prompt example, and five documented limitations including the 10–20× token cost and complete absence of community validation as of today. A comparison table against `hallmark` and `frontend-design` clarifies that all three can coexist in a workflow.

リサーチノート
design-council gives you 11 independent Claudes who argue with each other — and leave a paper trail."A single context, no matter how capable, evaluates a cross-cutting design decision from one vantage point."
design-council fixes this by spawning each seat as a truly independent Claude agent with its own context. As SKILL.md puts it: 2"Every teammate has its own context — not a subagent inheriting yours — so disagreement is structural, not simulated."
design-council's disagreement model 1| Seat | Owns |
|---|---|
principal-engineer | Architecture, module boundaries, simplicity — opens the debate with a ≤300-word position paper |
platform-engineer | Systems, infra, data shape, operational cost, observability |
integration-engineer | Downstream consumers, third-party developers, backwards compatibility |
test-engineer | TDD, mutation ritual, coverage, assertion hygiene |
qa-engineer | User flows vs. spec alignment, regression surface, manual test plan |
security-engineer | Input validation, secrets, path safety, error sanitization |
performance-engineer | Batching, memory, concurrency, measurement before optimization |
product-manager | UX alignment, product coherence, best-practice conformance |
ui-ux-designer | Ergonomics, visual consistency, interaction design |
accessibility-specialist | a11y, keyboard navigation, screen reader, contrast |
technical-writer | Docs, in-app help, CHANGELOG, API reference |
ui-ux-designer and accessibility-specialist. No user-facing input or infrastructure? Also drop security-engineer and platform-engineer. Internal tooling decisions often land on 4–6 seats. The plan card (Phase 0) shows you the proposed roster before anything spawns. 1devops-engineer (deploy risk, CI/CD, rollback), finops-engineer (cloud/API cost), legal-compliance (privacy, licensing), domain-expert (narrow subject-matter SME), and historian (codebase precedent for mature repos).TeamCreate, TeamDelete, Agent (with run_in_background and team_name), SendMessage, and TaskCreate — all Claude Code-specific primitives. There is no Cursor, Cline, Copilot, or Gemini CLI support, and none is mentioned as planned. 1/plugin marketplace add sjsyrek/claude-plugins
/plugin install design-council@sjsyrekgit clone --branch v0.2.1 https://github.com/sjsyrek/design-council.git
/plugin marketplace add ./design-council"teammateMode": "tmux" in Claude Code settings.json renders each seat in its own pane, so you can watch agents debate in real time. Without it, seats share the main pane and you cycle with Shift+Down.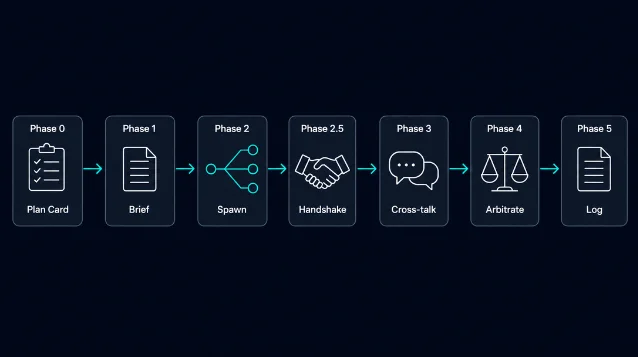
go to proceed, or adjust with swap X for Y, drop X, add X, or abort. This step is not skippable unless you've granted explicit "auto-mode" in your CLAUDE.md.CLAUDE.md, specs, memory, and task tracker — then writes a shared ~/.claude/councils/<slug>/brief.md. All seats point at this one file, which enables prompt-cache hits across parallel spawns (roughly 7–12k tokens saved per 8-seat council). 4principal-engineer, product-manager, technical-writer, historian); Sonnet handles analytical seats (test-engineer, performance-engineer, platform-engineer, qa-engineer). All-Opus is an option for high-quality-bar calls — at significantly higher cost.tmuxPaneId entries, which indicate silent spawn failures. This step exists because Agent can return [Tool result missing due to internal error] while still registering a teammate — Syrek observed a 3/13 silent-failure rate in one session. 3APPROVE, CONCERNS, or BLOCK, then DM each other directly to debate. The CEO routes: pairing disagreers, inviting tiebreakers, asking narrowing questions. Hard cap of 3 rounds.save, amend, or discard. On save, the log persists to ~/.claude/councils/<yyyy-mm-dd>-<slug>/log.md — outside any repo, intentionally durable.Decision Question: Should we move our auth tokens from localStorage
to httpOnly cookies across all three clients?
Binding Constraints: [pointer to brief.md]
Non-Goals: Do not revisit the session storage migration we completed
in Q1. Do not reopen the JWT vs. opaque token debate.
Prior-Council Context: council-2026-04-22-session-refresh found that
Safari's ITP behavior requires an explicit cookie prefix strategy.
Success Criterion: A decision with enough implementation specificity
that the integration-engineer can write the API contract change.
Known Deadlines/Budget: Ship by 2026-06-01. Full 11-seat council is
within budget.FINDING N blocks with a P0/P1 priority tag. The CEO deduplicates and files tracker items.domain-expert opt-in exists precisely because the standard seats can't replace a real SME on narrow technical calls. 1TeamDelete, cross-talk closure racing against in-flight DMs, and missing prior-council context causing a council to re-derive conclusions it had already reached. 4 These were fixed in v0.2.1, but the version is barely a month old.| Skill | Mode | When |
|---|---|---|
frontend-design (Anthropic) | Single-agent creative direction | Before or during UI generation — answers "what should this look and feel like?" |
hallmark (nutlope/Together AI) | Single-agent quality gate | After generation — runs 69 slop-test checks against the output |
design-council (sjsyrek) | Multi-agent architectural debate | Before implementation — produces a decision log for cross-cutting calls |
hallmark and frontend-design both run one context evaluating against a rubric. design-council is the only one where disagreement between viewpoints is structural — a security engineer that wasn't told what the platform engineer said, reaching different conclusions. Whether that structural independence produces better decisions than a well-prompted single context is an open empirical question this skill can't yet answer from external data."Do not invoke for simple bug fixes, single-specialist questions, library/tool picks, or pure exploration (→ Explore). The token cost isn't earned."
design-council for that and you're paying 10–20× to get 10 agents to agree with the one who had the relevant opinion.~/.claude/councils/ is also only useful if you'll actually read it — if you're making a decision you'd never audit later, skip the council.Claude Code plugin: convene 11 role-specialized peer agents to debate a technical decision in real time, with the invoking Claude acting as CEO.
このコンテンツについて、さらに観点や背景を補足しましょう。