Five diffusion papers worth reading today (May 15, 2026)
A five-entry digest covering the most read-worthy diffusion and flow-matching preprints from the May 14–15, 2026 ArXiv window — from a training-free inference fix that cuts FID 44% to NVIDIA's 2.6B open-source world model generating 60-second 720p video on a single GPU.
リサーチノート
Five diffusion and flow-matching papers from the May 14–15, 2026 ArXiv window stood out across ~540 cs.CV and cs.LG entries. Two address fundamental training or inference inefficiencies in flow matching; two push video generation distillation to new speed/scale frontiers; one opens up a new mechanistic window into how DiT models organize semantic information. All five are preprints unless noted otherwise.
1. The velocity deficit: a one-line fix that cuts flow matching FID by 44%
ArXiv: 2605.14819 · Venue: ICML 2026 (accepted)
Authors / institution: Linze Li, Zong-Wei Hong, Shen Zhang, Bo Lin, Jinglun Li, Yao Tang, Jiajun Liang — institution not listed on the abstract page; check the paper PDF for affiliation.
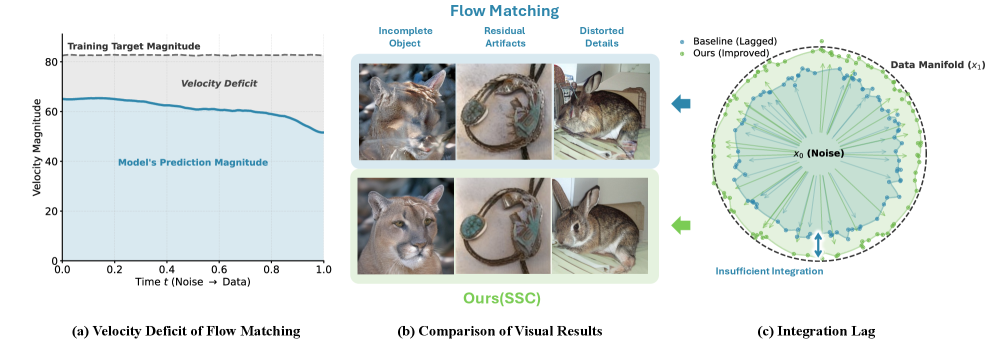
Core problem: Flow matching trains velocity fields with an MSE objective that systematically underestimates velocity magnitude. The result is what the authors call a "velocity deficit": the generated trajectory stalls near the noise end of the interpolant, starving the model of signal exactly when it needs to move particles decisively. Paradoxically, the same shrinkage is beneficial near the data end — it acts as implicit denoising. The phenomenon is structural, not a hyperparameter accident.
Method: The paper proposes two remedies. The training-based fix, Magnitude-Aware Flow Matching (MAFM), adds an explicit magnitude term to the objective. The inference-only fix, Scale Schedule Corrector (SSC), multiplies the velocity by a scalar that decays linearly from 1.1 to 1.0 across the sampling trajectory — one call to
torch.lerp. 1Results:
| Setting | Baseline FID | SSC FID | Δ |
|---|---|---|---|
| ImageNet 256, NFE=50, CFG=1.0 | 13.68 | 7.58 | −44.6% |
| ImageNet 256, sFID, NFE=50 | 11.38 | 5.12 | −55% |
| MS-COCO T2I, NFE=50 | 6.03 | 4.71 | −22% |
| ImageNet 512, NFE=50 | 11.72 | 8.39 | −28% |
The 50-step SSC model (FID 7.58) also beats the 250-step baseline (FID 8.65) — a 5× inference speedup at no extra cost. 1
The authors describe SSC as "a 'free lunch' improvement: it delivers a 5× speedup and better FID scores with zero retraining and one line of code." 2
Resources: No public code repository linked from the abstract page.
Peer-review status: Accepted at ICML 2026.
2. Massive activations in DiT: a sparse semantic subspace, not outlier noise
ArXiv: 2605.13974
Authors / institution: Evelyn Turri*, Davide Bucciarelli*, Sara Sarto, Lorenzo Baraldi, Marcella Cornia (*equal contribution) — University of Modena and Reggio Emilia (AImageLab, UNIMORE) and University of Pisa, Italy.
Core problem: A small fraction of channels in Diffusion Transformer (DiT) models carry anomalously large activation magnitudes. Prior work treated these "massive activations" (MAs) as outliers, quantization hazards, or detail-level drivers. This paper tests whether they have a deeper semantic function.
Method: Three complementary probes on five DiT models (including FLUX.1-schnell and FLUX.2-klein):
- Channel disruption — zero out the top-k MA channels vs. bottom-k channels; measure FID, CLIP-T, ImageReward, Aesthetic Score.
- Spatial clustering — K-means on the MA channels' spatial activation maps; compute mIoU against ground-truth segmentation masks.
- Semantic transport — copy MA channel activations from a source generation into a target generation at intermediate layers; measure CLIP-T and DINO-I on the resulting blend.
All three experiments use only inference-time intervention — no fine-tuning, no added parameters. 3
Results:
- Zeroing top-k MA channels causes CLIP-T, ImageReward, Aesthetic Score, and FID to collapse; zeroing bottom-k has negligible effect.
- K-means on MA channels yields binary masks with mIoU ≈ 0.5 on GenAI-Bench (1,600 prompts, FLUX.2-klein) — substantially above bottom-k (≈0.2) and random channels.
- Semantic transport: DINO-I S*T score 20.1 vs. 2.7 for interpolation baseline (3,515 prompt pairs on FLUX.1-schnell). 4
The authors conclude: "These results recast massive activations not as activation anomalies, but as a sparse prompt-conditioned carrier subspace that organizes and controls semantic information in modern DiT models." 4
For personalization, on DreamBench++ (150 subjects) this training-free transport raises CLIP-I_pers by +12.4 to +18.9 points, matching dedicated editing backbones.
Resources: Project page at aimagelab.github.io/MAs-DiT/. No code repository linked.
Peer-review status: Preprint (submission date May 13, 2026; review status unknown).

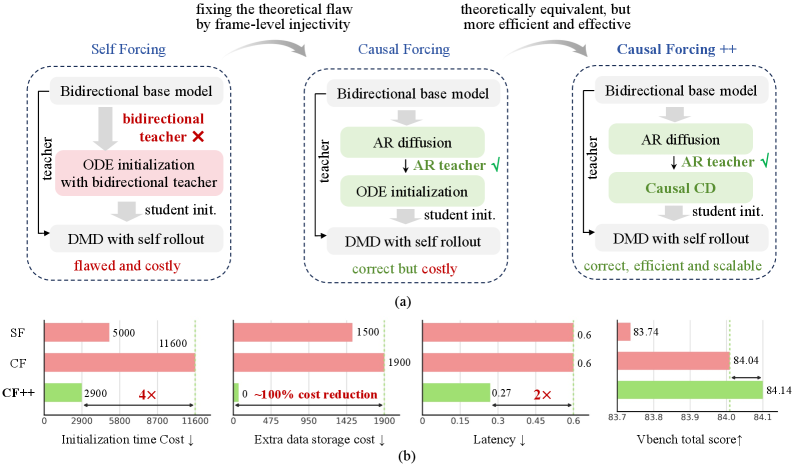
3. Causal Forcing++: 50% latency reduction for autoregressive video diffusion
ArXiv: 2605.15141
Authors / institution: Min Zhao*, Hongzhou Zhu*, Kaiwen Zheng, Zihan Zhou, Bokai Yan, Xinyuan Li, Xiao Yang, Chongxuan Li, Jun Zhu† (*equal, †corresponding) — Tsinghua University / Shengshu AI / Renmin University of China. Jun Zhu is a senior diffusion-model researcher at Tsinghua.
Core problem: Autoregressive (AR) video diffusion models generate frames sequentially. Reducing their per-frame step count requires a distillation initialization that is both cheap to compute and consistent with the causal structure. The prior approach, causal ODE distillation, requires pre-computing the teacher's full probability-flow ODE trajectories — roughly 11,600 A800 GPU·hours of storage-intensive data preparation for stage 2 alone. 5
Method: Causal Forcing++ (CF++) replaces causal ODE distillation with causal consistency distillation (causal CD) for student initialization. Causal CD matches the AR conditional flow map over adjacent time-step pairs only — no full PF-ODE trajectory is needed, so no intermediate trajectory data needs to be stored. Stage 2 requires 0 GiB of pre-generated data, versus ~1,900 GiB for causal ODE. 6
The paper's authors summarize the theoretical motivation: "Causal CD serves as a principled substitute for causal ODE initialization, while avoiding the expensive trajectory-generation bottleneck." 6
Results:
| Setting | VBench Total | VBench Quality | VisionReward | First-frame latency |
|---|---|---|---|---|
| CF (causal ODE, chunk 4-step) | 84.04 | 84.59 | 6.326 | 0.60 s |
| CF++ (causal CD, frame 2-step) | 84.14 | 84.89 | 6.661 | 0.27 s |
| CF++ frame 4-step | — | 84.94 | 6.798 | — |
Training cost for stage 2: ~2,900 A800 GPU·hours (CF++) vs ~11,600 (causal ODE) — 4× reduction. 5
CF++ also extends to action-conditioned world modeling (Genie3-style interactive generation).
Resources: Two GitHub repositories: github.com/thu-ml/Causal-Forcing and github.com/shengshu-ai/minWM.
Peer-review status: Preprint (submitted May 14, 2026; review status unknown).
4. AnyFlow: video diffusion distillation that scales with inference budget
ArXiv: 2605.13724
Authors / institution: Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai, Mike Zheng Shou — NVIDIA and National University of Singapore (NUS). Song Han (MIT/NVIDIA) and Mike Zheng Shou (NUS) are both well-established researchers in efficient generative models.
Core problem: Consistency distillation compresses a video diffusion model into a fixed few-step sampler by learning endpoint mappings (z_t → z_0). The tradeoff: adding more steps at inference time does not improve quality, because the model was never trained to interpolate intermediate trajectory points. Test-time scaling is lost.
Method: AnyFlow replaces the endpoint-consistency objective with flow-map transition learning: given a source time t and a target time r < t, the student predicts the intermediate state z_r rather than the endpoint z_0. Full ODE rollouts decompose into a chain of short-interval transitions. The key mechanism is Flow Map Backward Simulation, which provides on-policy training data for these short transitions without running the full teacher at inference. 7
The paper states: "AnyFlow is the first any-step video diffusion distillation framework based on flow maps. Instead of distilling a model for only a few fixed sampling steps, AnyFlow optimizes the full ODE sampling trajectory." 7
Results: Validated across bidirectional and causal video diffusion architectures at 1.3B, and scales to 14B parameters. In the few-step regime, AnyFlow matches or outperforms consistency-based distillation. As step count increases, performance continues to improve — the property that consistency distillation cannot offer. Specific FID/VBench numbers are reported in the full paper; the abstract does not enumerate them.
Resources: Project page at nvlabs.github.io/AnyFlow/.
Peer-review status: Preprint (submitted May 13, 2026; review status unknown).
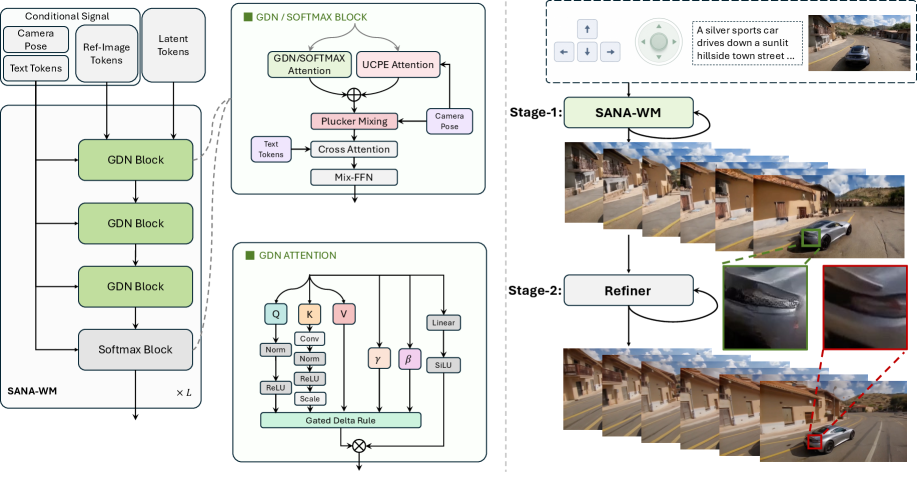
5. SANA-WM: a 2.6B open-source world model for 60-second 720p video on one GPU
ArXiv: 2605.15178
Authors / institution: Haoyi Zhu*, Haozhe Liu*, Yuyang Zhao*, Tian Ye*, Junsong Chen*, Jincheng Yu, Tong He, Song Han, Enze Xie (*equal contribution) — NVIDIA. Song Han and Enze Xie are senior researchers at NVIDIA working on efficient diffusion architectures.
Core problem: Minute-scale world model generation at 720p requires handling thousands of video tokens in a single forward pass. Prior open-source systems (e.g., LingBot-World at 14B+14B parameters) require 8 GPUs and produce 0.6 videos/hour. The bottleneck is the quadratic cost of full softmax attention across long temporal sequences.
Method: SANA-WM uses a Hybrid Linear Diffusion Transformer: frame-level Gated DeltaNet (GDN) — a linear-complexity recurrent attention variant — handles temporal context, while periodic standard softmax attention layers capture local spatial detail. The two mechanism types alternate throughout the model depth.
Camera control uses a dual-branch approach: learned Unified Camera Position Embeddings (UCPE) inject trajectory information into attention, while Plücker embeddings encode raw 3D ray geometry in the pixel stream. The combination targets 6-DoF camera trajectory adherence. 8
Training used only ~213K public video clips over 15 days on 64 H100s. A distilled variant runs on a single NVIDIA RTX 5090 with NVFP4 quantization, generating a 60-second 720p clip in 34 seconds. 9

Results:
| Metric | SANA-WM | SANA-WM + refiner | LingBot-World (prior SOTA) |
|---|---|---|---|
| Pose RotErr (Simple-Traj, °) | 7.59 | 4.50 | 10.47 |
| Pose RotErr (Hard-Traj, °) | 10.02 | 8.34 | 18.99 |
| VBench Overall | 79.29 | 80.62 | — |
| Throughput (videos/hr) | 24.1 | 22.0 | 0.6 |
| Peak VRAM | 51.1 GB | 74.7 GB | 454.1 GB |
36× throughput gain over LingBot-World, at 1/9th the memory footprint. 8
Resources: Project page at nvlabs.github.io/Sana/WM/; code repository at github.com/NVlabs/Sana.
Peer-review status: Preprint (submitted May 14, 2026; review status unknown).
参考ソース
- 1The Velocity Deficit: Initial Energy Injection for Flow Matching
- 2The Velocity Deficit (HTML full text)
- 3Few Channels Draw The Whole Picture: Revealing Massive Activations in Diffusion Transformers
- 4Few Channels Draw The Whole Picture (HTML full text)
- 5Causal Forcing++
- 6Causal Forcing++ (HTML full text)
- 7AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
- 8SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
- 9SANA-WM (HTML full text)
このコンテンツについて、さらに観点や背景を補足しましょう。