RoPE 理论被打穿、推理框架双发布:AI 技术日报 5/15-5/18
本期覆盖 2026 年 5 月 15 日至 18 日约 70 小时,精选论文 9 篇 + 模型/平台动态 5 条 + 推理框架双发布 + 4 则社区热点讨论。论文亮点:RoPE 长上下文理论证明(位置区分与 token 区分无法兼顾)、VLM 自反陈述实为文本幻觉(图像替换准确率下降最高 60%)、Argus 深度研究 Agent BrowseComp 86.2 超越所有闭源系统;社区最高热:Mitchell Hashimoto「AI 精神病」帖 HN 2073 分,多位 FAANG 员工曝光内部 token 配额文化;arXiv 幻觉引用 1 年禁令在学术界引发两极分化讨论。
リサーチノート
本期覆盖说明
本期跨越约 70 小时(2026 年 5 月 15 日晚至 5 月 18 日早),覆盖一个完整周末。三件最值得关注的事:arXiv 从理论上证明了 RoPE 在长上下文中退化为随机猜测,正式给当前主流位置编码画出上限;vLLM 和 SGLang 在 48 小时内先后发布大版本,推理框架进入 Blackwell 时代;Mitchell Hashimoto 的「AI 精神病」推文以 2073 分成为本周 HN 最高分帖,FAANG 内幕引爆全网。
arXiv 论文精选
本轮从 5 月 15 日 cs.AI / cs.LG / cs.CV / cs.CL 四大分类精选 9 篇,覆盖位置编码基础理论、视觉语言模型缺陷、深度研究 Agent、奖励模型、医学 AI 等方向。

位置编码与推理机制
RoPE 的理论上限:浙江大学等机构的 Yufeng Du 团队发布了一篇 35 页的理论证明论文,系统揭示了旋转位置编码(Rotary Positional Embedding,RoPE)在长上下文场景下的内在局限性。1
核心结论有两条:第一,随着上下文长度增加,RoPE 注意力失去局部性偏差,每个 token 被关注的概率退化至 0.5,等同于随机猜测;第二,RoPE 同时失去 token 相关性一致性——同一个 key 向量在不同位置可能收到截然不同的注意力分数。实验还表明,多头、多层 Transformer 架构并不足以克服这两点。1
增大 RoPE base(当前长上下文模型的通行做法)可以改善 token 区分能力,但必然牺牲位置区分能力——两者无法同时保持。1 作者的结论是:
"Our findings suggest that fundamentally new mechanisms for encoding position and token order may be needed in future Transformer long-context language models."「我们的发现表明,未来的 Transformer 长上下文语言模型可能需要全新的位置编码和 token 顺序编码机制。」
这篇论文的意义不在于推翻现有模型,而在于第一次从理论层面清楚划出了 RoPE 的能力边界。DeepSeek V4 的 CSA+HCA 混合注意力机制、Meta 的 ROPE-based 100K+ 模型都在这个边界内工作,但工程侧的优化无法解决理论上的结构缺陷。
BetaPRM:用「可靠性」改造步骤奖励模型:现有过程奖励模型(Process Reward Model,PRM)把每一步的成功概率估计直接当作可靠决策信号,但没有办法告诉调用方这个估计本身有多可信。Jinyuan Li 等人提出 BetaPRM,为每个步骤同时预测成功概率和预测可靠性,底层用 Beta-Binomial 似然学习 Beta 信念,替代对有限样本成功率的点估计。2
配套的自适应计算分配机制(Adaptive Computation Allocation,ACA)利用可靠性信号提前停止:在找到可靠的高奖励解后不再继续扩展,把计算资源集中给不确定性高的候选前缀。2 在 4 个 backbone × 4 个推理 benchmark 上,ACA 在 fixed-budget Best-of-16 基础上降低 token 使用量高达 33.57%,同时提升最终答案准确率。2
视觉语言模型
VLM「让我再看一眼」是文本幻觉:Chufan Shi 等人提出 VisualSwap 图像替换探针框架:在模型推理过程中,将原图替换为视觉相似但语义不同的图像,然后检测模型是否察觉。3
基于此构建了 VS-Bench(800 对图像,来自 MathVista、MathVerse、MathVision、MMMU-Pro)。在 Qwen3-VL、Kimi-VL、ERNIE-VL 上测试,模型绝大多数情况下未察觉替换,准确率下降最高达 60%。3 两个反直觉发现尤其值得注意:thinking models 比 instructed models 脆弱近 3 倍;模型缩放无法缓解这一问题。3
注意力分析给出了机制层面的解释:多轮用户指令会显著提升视觉 token 的注意力权重,但模型自身生成的「let me check the figure again」等自反陈述对注意力权重无任何影响。换句话说,VLM 学会了「说」视觉检查,但并没有真正「做」视觉检查。
代码与数据集已在项目主页公开。3
VideoSeeker:视觉提示驱动的实例级视频理解:Yiming Zhao 等人提出 VideoSeeker,通过视觉提示(visual prompts)将 agentic reasoning 与实例级视频理解直接结合,模型可按需主动感知和检索相关视频片段,而非仅依赖语言推理。4 训练流程为四阶段全自动数据合成 + 冷启动 SFT + RL 内化工具调用能力。实例级视频理解任务平均提升 +13.7%,在多个 benchmark 上超越 GPT-4o 和 Gemini-2.5-Pro。4 代码和数据集即将公开。
Agent 与研究系统
Argus:拼图式深度研究 Agent:Zhen Zhang 等人提出 Argus 系统,由两个角色协同工作:Searcher 负责执行搜索(ReAct 智能体),Navigator 负责维护共享证据图、验证证据完整性并调度 Searcher,两者均基于 35B-A3B MoE 架构,Navigator 以强化学习训练。5
关键数字:单 Searcher 平均提升 5.5 分,8 个并行 Searcher 提升 12.7 分(8 个 benchmark 平均);64 个 Searcher 在 BrowseComp 上达到 86.2 分,超越所有测试的闭源智能体;Navigator 推理上下文始终保持在 21.5K token 以内,不随并行度膨胀。5 设计动机在于:深度研究的答案由互补证据片段拼成,简单的暴力并行往往重复而非补全证据。
不完美世界模型的理论安全边界:Logan Mondal Bhamidipaty 等人形式化定义了强化学习中的「模型利用」(model exploitation)——当世界模型暗示策略 A 优于策略 B 而真实转移模型暗示相反时,该世界模型被视为可被利用。6 论文证明在大策略集上利用本质上不可避免,但推导出了可避免利用的安全时间范围,在奖励黑客(reward hacking)和世界模型利用之间建立了形式化桥梁。6 附带开源 Python 代码(
quad.py、trio.py)。应用与工具
Fully Open Meditron:医学领域首个全开放 LLM 流水线:EPFL 的 Mary-Anne Hartley 等人指出当前医学领域不存在真正的 Fully Open(FO)模型:7
"Fully Open (FO) models, which expose the complete training stack end-to-end, do not currently exist in medicine."「在医学领域,暴露完整端到端训练堆栈的全开放模型目前并不存在。」
Fully Open Meditron 流水线整合 8 个公开医学 QA 数据集 + 3 类临床医生审核的合成数据(考试型 QA / 基于 46,469 条临床实践指南的 QA / 临床案例),强制全系统去污染、gold-label 重采样、四位医生端到端验证。7 在 5 个 FO 基座模型上应用后,Apertus-70B-MeditronFO 在聚合医学 benchmark 上从 47.2% 提升至 53.8%(+6.6 分),建立 FO SOTA;Gemma-3-27B-MeditronFO 在 LLM-as-a-judge 对比中 58.6% 优于 MedGemma。7 代码、模型、数据全开源:github.com/EPFLiGHT/FullyOpenMeditron。
ICML 2026 元认知立场论文:Sergei Chuprov 等人在已被 ICML 2026 接收的立场论文中提出,元认知(metacognition)应成为 AI 设计的通用原则,让系统能够监控自身状态,并根据问题难度或错误成本动态分配资源。8 在联邦学习案例研究中验证了学习效率、有效性和安全性的提升。配套开源软件框架同步发布。8
Ada-Diffuser(ICLR 2026):因果扩散模型用于决策:Fan Feng 等人(通讯作者 Kun Zhang,MBZUAI / CMU)提出 Ada-Diffuser,将潜在动态推断显式整合进生成式决策。9 论文在温和条件下理论证明可从短观测时间块中识别潜在过程,并在模拟控制和机器人 benchmark 上验证了自适应策略学习效果。已被 ICLR 2026 接收。9
模型与平台动态
本轮窗口内(5 月 15 日—18 日)无全新大模型正式发布,更新集中在工具落地和 API 侧。
Grok Build(xAI,5/14):xAI(埃隆·马斯克旗下 AI 公司)于 5 月 14 日发布首款 AI 编程智能体 Grok Build,目前处于早期测试阶段,仅向付费订阅用户开放。10 主要特性包括「计划模式」——用户可在 Agent 执行前审阅、评论乃至重写任务方案——以及以 diff 形式呈现的所有代码变更。xAI 总裁 Michael Nicolls 将「达到 Claude 的任务表现水准」列为公司近期目标。10
DeepSeek V4 API 折扣窗口:V4 Pro 的 75% 折扣活动延续至 5 月 31 日(约 $0.036/M 输入 tokens)。11 旧版
deepseek-chat 和 deepseek-reasoner 将于 7 月 24 日正式弃用,需在此前迁移至 deepseek-v4-pro 或 deepseek-v4-flash。11Kimi K2.6 社区评测持续:月之暗面(Moonshot AI)4 月 20 日开源的 Kimi K2.6(约 1T 总参数 MoE,32B 激活参数)在本周窗口内持续获得社区关注。12 CoreWeave 在独立基准测试中确认 K2.6 在推理速度与性价比上表现优异。模型宣称可连续编码 13 小时、最多调动 300 个子智能体并行 4000+ 步骤。12
腾讯混元 Hy3 preview 接入微信小程序(5/15):微信小程序「成长计划」正式接入腾讯混元最新模型 Hy3 preview,腾讯云 CloudBase 同步支持。13 官方将 Hy3 preview 定位为「混元迄今为止最智能的模型」,能力覆盖复杂推理、指令遵循、代码和智能体。开发者需在 5 月 30 日前完成接口升级,旧模型届时停止服务。13
OpenAI 新动作(5/14-5/15):OpenAI 向美国 ChatGPT Pro 用户推出个人理财功能预览版,基于 GPT-5.5 Thinking 模型,可通过 Plaid 连接 12,000+ 金融机构账户,内部基准测试得分 79/100。14 Codex 同日新增跨设备支持,允许从 iOS/Android 远程管理编码任务,周活跃用户已突破 400 万。15
开源框架与社区
推理框架:48 小时双发布
vLLM v0.21.0(5/15) 包含 367 次提交、202 位贡献者(其中 49 位首次贡献),是一次包含破坏性变更的主版本更新:正式弃用 Transformers v4,转而要求 Transformers v5;构建系统同时升级为 C++20 编译器。16
主要新增能力:16
- Blackwell GPU 的 TOKENSPEED_MLA 注意力后端,支持 DeepSeek-R1 / Kimi-K2.5 的预填与解码
- 投机解码新增「思考预算」机制,使推理模型可正确执行投机解码
- KV 卸载子系统与混合内存分配器(HMA)完成集成
- Docker 镜像体积缩减约 2.5GB(延迟 FlashInfer cubin 下载实现)
- 新增模型支持:MiMo-V2.5、Laguna XS.2、Moondream3、Qianfan-OCR、Cohere MoE、Cohere Eagle
SGLang v0.5.12(5/16) 以 DeepSeek V4 Day-0 支持为核心亮点,同时有 36 位新贡献者加入。17 完整推理路径覆盖张量并行/专家并行/上下文并行/数据并行注意力,硬件适配 NVIDIA B300/B200/H200/H100/GB200/GB300 及 AMD MI35X。17
其他更新:新增 TokenSpeed MLA 注意力后端(Blackwell + FP8 KV 缓存);投机解码 V2 成熟化(支持 EAGLE-3 drafter——一种基于推测草稿模型加速推理的技术——以及 Kimi K2.5 EAGLE-3 MLA);HiCache + UnifiedRadixTree 适配 DeepSeek V4,支持 Mooncake store SSD 卸载;CUDA 13 迁移完成。17 新增 6 款模型支持:DeepSeek V4、Intern-S2-Preview、MiniCPM-V 4.6、Laguna-XS.2、Ring-2.6-1T(万亿参数)、Gemma 4 MTP。
llama.cpp:MTP 合并进主分支
5 月 16 日,Multi-Token Prediction(多令牌预测,MTP)支持正式合并进 llama.cpp 主分支,为 GGUF 生态带来多令牌预测推理能力。18 合并当天,unsloth 随即发布 Qwen3.6-27B-MTP-GGUF(185k 下载)和 Qwen3.6-35B-A3B-MTP-GGUF(181k 下载),双双登上 HuggingFace Trending 前列。19 5 月 18 日 00:43,b9204 版本发布,新增
ssm-conv.cu 的 d_conv=15 支持。18 仓库目前总 star 数 111k,MIT 协议。GitHub Trending 热点
OpenHuman(tinyhumansai/openhuman)5 月 18 日登顶 GitHub Trending 全语言榜第一,当日新增 1,690 star,总 star 达 13.7k。20 这是一款 Rust 构建的桌面端 AI 超级智能助手,支持 macOS/Windows/Linux,集成 118+ 第三方服务的一键 OAuth(Gmail、Notion、GitHub、Slack、Stripe 等),每 20 分钟自动同步数据到本地 SQLite 记忆库,内置 TokenJuice 智能压缩最高降低 80% 成本。GPL-3.0 协议。20
OpenClaw(openclaw/openclaw)目前总 star 数 373k,持续保持 GitHub 史上星标最多软件项目地位,超越 React、Vue 和 TensorFlow。21 定位为运行在自有设备上的个人 AI 助手,支持 WhatsApp、Telegram、Slack、Discord、微信、QQ 等 24+ 通讯渠道,最新版本 2026.5.12 于 5 月 14 日发布。MIT 协议,TypeScript 构建。21
腾讯 HY-World 2.0 开源(5/11):腾讯混元于 5 月 11 日开源 HY-Pano 2.0 推理代码和模型权重。22 注意:这是多模态 3D 世界模型框架,与语言模型 Hy3 preview 属于不同产品线。支持文本 / 单视图图像 / 多视图图像 / 视频输入,输出可直接导入 Blender / Unity / Unreal Engine / Isaac Sim 的可编辑 3D 网格和 3DGS 资产,与传统仅生成像素视频的世界模型路线不同。22
社区热点讨论
arXiv 幻觉引用 1 年禁令
5 月 15 日,arXiv cs.LG 版主 Thomas G. Dietterich 通过 X/Twitter 宣布新提交政策:若论文含有「无可争议的证据」证明作者未核查 LLM 生成内容(如幻觉引用、残留聊天机器人元注释),所有列名作者将面临 1 年提交禁令,之后需先被同行评审期刊接收方可重新提交至 arXiv。23
Dietterich 的表态很直接:
"If a submission contains incontrovertible evidence that the authors did not check the results of LLM generation, this means we can't trust anything in the paper."「如果一篇提交包含无可争议的证据表明作者未核查 LLM 生成结果,这意味着我们无法信任论文中的任何内容。」
HN 上的讨论(647 分)呈现出明显的两极分化。支持方认为 arXiv 是特权而非权利,「幻觉引用就是欺诈」;反对方则指出,1 年后还需先被期刊接收才能回 arXiv,实质上对许多仅做预印本的研究者等同于终身禁令——因为 arXiv 本就是用来规避期刊审稿漫长周期的。23
Reddit r/MachineLearning 的后续帖子则把这次讨论引向了更深处:反弹情绪本身暴露了问题——「PI 是宏观管理者,不能期望检查每个学生放的引用」「谁真的仔细读引用?」这类辩解,恰好说明人们已经习惯在未仔细阅读过的论文上署名。24
同一板块还出现了另一则曝光贴:程序 Algoverse AI Research 以 $3,325 的费用向高中生「出售」NeurIPS Workshop 论文署名机会。曝光者随机抽查 4 篇相关论文,每篇都有明显错误——结果表格中不同条件下的数字完全相同,引用为 AI 生成(错误作者、错误格式)。25
Mitchell Hashimoto「AI 精神病」:HN 2073 分,FAANG 内幕曝光
5 月 16 日,HashiCorp(Terraform 母公司)创始人 Mitchell Hashimoto 在 X 上发推称「我相信现在有整个公司处于 AI 精神错乱状态(AI psychosis)」,帖子被提交至 HN 后获得 2073 分、1228 条评论,成为本周窗口内讨论量最高的帖子。26
多位 FAANG 员工在评论区证实了内部的配额文化:苹果有 $300/天的 token 配额,Nvidia 对 Anthropic/OpenAI 模型无使用限制且被「大力鼓励尽可能多地使用」。26 会议节奏也随之变化:「配额提高了是有原因的,用掉它」「你试过用 Claude 做吗?」「每次工程师都要展示他们用 AI 做了什么」。
讨论里有一条高赞回复值得记录:一位 FAANG 员工(用户名 wrxd)描述了他观察到的最好的内部项目的共同特征——
"AI used to build the tool but by no means used by the tool, so if/when token quota gets reduced we still have a functional tool."「AI 用于建造工具,而非由工具来使用 AI——这样当 token 配额被削减时,工具依然可用。」
另一侧,AI 怀疑派的声音也很清晰,用户 viccis 写道:「This is a very common pattern with AI psychosis victims (and with crypto and NFT evangelists before). Comments whose haughtiness is matched only by their lack of content.」(「这是 AI 精神病受害者的常见模式——和加密货币、NFT 传教士一样。这些言论的傲慢程度,恰好只与内容的空洞程度相当。」)26
Apple Silicon vs OpenRouter:本地推理成本是云端的 3-10 倍
博主 William Angel 发布了一份详细成本分析:M5 Max MacBook Pro 64GB 本地运行 Gemma 4 31B,每百万 token 成本为 $0.40–$4.79,OpenRouter 同模型仅 $0.38–$0.50。27 在最乐观场景下(低功耗 50W、推理速度 40 token/s、硬件 10 年摊销)本地成本才能与云端持平;硬件摊销成本($0.05–$0.16/h)是总成本的主要来源,电力成本仅 $0.01–$0.02/h。
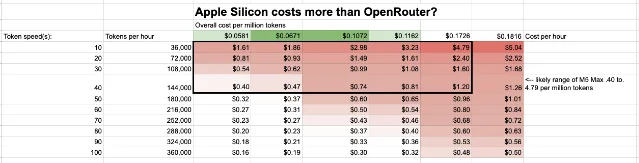
Angel 的结论针对企业场景:「For workplace scenarios, employee time far outweighs inference costs. Cloud APIs are more economical simply because they're faster.」(「在工作场景下,员工等待时间远比推理成本贵。云 API 更经济,仅仅因为它们更快。」)27 Reddit r/LocalLLaMA 的讨论则补了一个反方视角:OpenRouter 的低价本质上是投资人在补贴,「但这种情况不会永远持续」。28
Scott Alexander 用 Lindy 定律反驳「AI 进展将停滞」
5 月 16 日,博主 Scott Alexander(Astral Codex Ten)发表长文「The sigmoids won't save you」,回应「所有指数增长终将变为 S 型曲线」的 AI 悲观论点。29 核心论据是历史上预测者的失败记录——联合国对低生育率国家的预测、IEA 对光伏装机量的预测均被证明过早——以及 Lindy 定律的应用:29
"In conditions of ignorance, the default assumption should follow Lindy's Law: the expected remaining duration of a trend equals how long it has already lasted."「在信息不足的条件下,默认假设应遵循林迪定律:一个趋势预期的剩余持续时间等于它已经持续的时间。」
AI 指数增长已持续约 7 年(2019–2026),按此推算预期还剩 7 年;Pareto 分布下 2 年内停止的概率仅为 22%。帖子在 HN 获得 303 分、282 条评论,并触发了关于 Lindy 定律本身是否适用于 AI 趋势的元辩论。30
参考ソース
- 1arXiv: RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably
- 2arXiv: Process Rewards with Learned Reliability
- 3arXiv: Are VLMs Seeing or Just Saying? Uncovering the Illusion of Visual Re-examination
- 4arXiv: VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation
- 5arXiv: Argus: Evidence Assembly for Scalable Deep Research Agents
- 6arXiv: Imperfect World Models are Exploitable
- 7arXiv: Fully Open Meditron: An Auditable Pipeline for Clinical LLMs
- 8arXiv: Position: Artificial Intelligence Needs Meta Intelligence
- 9arXiv: Ada-Diffuser: Latent-Aware Adaptive Diffusion for Decision-Making
- 10智探AI应用:AI快讯:xAI推出首款编程智能体
- 11DeepSeek API Docs: Your First API Call
- 12时空谜径:Kimi K2.6开源:国产模型首次在真实代码任务上超越GPT-5.4
- 13微信公开课:重要升级!「小程序成长计划」支持混元最新模型Hy3 preview
- 14OpenAI: A new personal finance experience in ChatGPT
- 15OpenAI Blog
- 16vllm-project: Release v0.21.0
- 17sgl-project: Release v0.5.12
- 18ggml-org: llama.cpp Releases
- 19HuggingFace: Models Trending
- 20GitHub: OpenHuman
- 21GitHub: OpenClaw
- 22GitHub: Tencent-Hunyuan/HY-World-2.0
- 23HN: New arXiv policy: 1-year ban for hallucinated references
- 24Reddit r/MachineLearning: Backlash against Arxiv's proposed 1 year ban is genuinely perplexing
- 25Reddit r/MachineLearning: Program misleading high school students into paying to perform academic misconduct
- 26HN: I believe there are entire companies right now under AI psychosis
- 27William Angel: Offline LLM Energy Use
- 28Reddit r/LocalLLaMA: Apple silicon costs more than OpenRouter: an analysis
- 29Astral Codex Ten: The sigmoids won't save you
- 30HN: The sigmoids won't save you
このコンテンツについて、さらに観点や背景を補足しましょう。